
ML Case-study Interview Question: Rideshare Payment Fraud Detection: An ML & Dynamic Challenge Approach


Browse all the ML Case-Studies here.
Case-Study question
A global ridesharing and delivery platform faces frequent payment fraud. Bad actors create accounts or use stolen cards to bypass payment. The platform used strict actions to block suspicious accounts, but found this alienated legitimate users who were misclassified as risky. Propose a data-driven approach for detecting and mitigating fraud while minimizing false positives. Describe how you would design a risk challenge workflow to verify ownership of a payment method, integrate the challenge within the platform’s user flow, and decide when to apply it. Explain how you would measure success, monitor results, and refine models to adapt to changing fraud patterns.
Proposed Detailed Solution
A risk management system must first detect suspicious behavior and then mitigate potential fraud. A rules-based engine checks signals like unusual trip requests or multiple payment methods added in quick succession. A machine learning model ranks the probability that a transaction will fail or that the user is not a legitimate cardholder. A dynamic challenge is triggered for cases above a certain risk threshold. This challenge asks users to prove ownership of the payment method with minimal friction. It can be integrated at ride-request time or when a new card is added.
A user-friendly step involves a small authorization hold on the user’s card. The user then checks their bank statement for two random amounts and enters them back into the app. Accurately verifying these amounts proves they have genuine access to the card details. If they fail, the system restricts further usage until they pass verification through customer support. This approach saves resources compared to automatically banning suspicious profiles.
Storing challenge status in a backend database allows the system to track whether the user partially completed verification. If the user exits the app during the challenge, the backend persists the incomplete status, and the challenge is resumed whenever the user attempts another transaction. Each session updates the user’s verification status. A large number of failed attempts signals likely fraud, leading to an automatic block. Success rates, user churn rates, and overall fraud incidence are measured and fed back to model training.
Machine Learning Pipeline
A supervised classification model can be built using user-level features (account age, average spend, device fingerprints) and payment-level features (card brand, location of issuance, usage velocity). A simple logistic regression approach might use a function of weighted inputs. The probability of fraud p is modeled using the logit function:
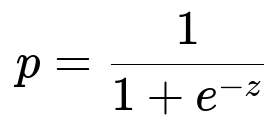
Here z is w0 + w1 x1 + ... + wn xn, where each x_i is a feature such as transaction history or user behavior patterns, and w_i are learned parameters. The model is trained on known fraud vs. non-fraud outcomes. The predicted probability triggers different actions: instant approve, request challenge, or block. High confidence fraud leads to stricter measures. Moderate confidence triggers the ownership verification challenge. Low confidence means minimal friction.
Implementation Details
The platform’s backend receives a ride request or a new card addition event. The rules engine runs, and the ML model evaluates the request. If the model’s score surpasses the threshold, an error code signals the mobile app to display the risk challenge flow. Once the user opts in, two small random authorization holds are placed via a payment service that interacts with the card issuer. The user then checks their card statement. When they return to the app, they enter the two amounts. The system verifies them. If correct, the challenge is passed, and the user continues. If they fail repeatedly, the system marks their card as potentially fraudulent and restricts their access.
Data on challenge completion rates and fraud outcomes is streamed into analytics pipelines. The product team monitors the percentage of people completing verification, time taken to complete, and the proportion of false positives. This feedback refines thresholds in the rules engine and re-trains the ML model. Over time, the system auto-adjusts its logic based on newly discovered fraud tactics or changes in user behavior.
How would you set the model threshold to balance fraud catch vs. user experience?
A threshold controls the tradeoff between labeling legitimate users as fraud vs. letting fraudsters go undetected. Low threshold equals more challenges (catch more fraud but risk annoying legitimate users). High threshold equals fewer challenges (better user experience but more fraud slipping through). Historical data can inform an optimal operating point. One method is to plot the precision-recall curve to see how different thresholds affect precision (fraction of flagged cases that are actually fraud) vs. recall (fraction of total fraud cases captured). Business cost metrics often shape the final decision. For instance, missed fraud might cost more than slightly inconveniencing a small percentage of legitimate users.
How would you handle new fraud patterns that bypass existing rules?
Monitoring fraud rates over time indicates if existing rules are failing. Rising fraud suggests new exploits. A pipeline should gather recent fraudulent cases as soon as they appear and label them quickly. Real-time streaming can cluster anomalies to find emerging tactics. Automated feature engineering helps incorporate new signals such as device IDs, IP reputation, or unusual ordering patterns. Retraining the model on these expanded features updates its decision boundary. Online learning or frequent batch retraining also helps the system adapt to new fraud variants.
How would you minimize friction for genuine users during the risk challenge?
Reducing friction involves limiting unnecessary challenges. Rules and ML scores should be tuned so that only truly suspicious profiles are asked to verify. Keeping the challenge steps brief lowers drop-offs. Users see short instructions, and the required action is just confirming two small amounts. Clear messaging assures them the process is secure. Allowing quick retries helps if they mistype amounts. Once verified, the user should not be challenged again unless there are significant new risk signals.
How would you evaluate whether this risk challenge approach is successful?
Success metrics include reduction in fraudulent transactions, decreased lost revenue from chargebacks, and lower customer support burden. Improved user retention for genuine users who were previously incorrectly blocked is another key metric. Success rates of the challenge flow measure how many complete it accurately vs. give up. Churn rates measure whether challenges drive people away. Tracking these metrics over several months highlights whether risk challenges effectively reduce fraud while preserving user satisfaction. Real-time dashboards show the volume of triggered challenges, pass/fail rates, and total fraud levels, allowing quick intervention if something spikes.