
ML Case-study Interview Question: Multi-Level Relevance Ranking with Gradient Boosting for Better Marketplace Ads


Browse all the ML Case-Studies here.
Case-Study question
A major online marketplace wants to improve its recommendation engine for “similar item” advertisements on a product details page. The engine retrieves a relevant set of sponsored items and then ranks them to increase the probability of purchase, while keeping the platform’s CPA-based advertising model profitable. The team noticed that using only purchase data as a label for relevance led to many missed signals of genuine interest. They decided to incorporate additional user actions (like clicks, watchlist additions, etc.) into a multi-level relevance scheme. As a Senior Data Scientist, design a solution that identifies key engagement signals, assigns them different importance levels in the ranking model, and optimizes the final ranker to balance overall user satisfaction and advertising revenue. Suggest a complete approach, including data collection, label generation, model training, and evaluation strategies.
Detailed Solution
A robust solution involves multiple stages. Historical user logs and item details feed into a recall system and a ranking system. The goal is to incorporate a broader range of user actions, beyond direct purchases, into the training labels. A gradient boosting model can then learn how to assign higher scores to items that reflect stronger conversion intent.
First gather user behavior data for the recommended items. Each event that shows a user’s explicit or implicit interest should be considered. Map these events to relevance levels. Purchases are at the highest level. Actions like “add to cart” and “buy it now” are next, while clicks or watchlist additions signal milder but still useful intent. Items that remain unclicked are assigned the lowest relevance level.
Balance each relevance level with appropriate sample weights in the loss function. Doing so ensures that events closer to actual purchase have a stronger influence than weaker signals. A pairwise ranking loss is often used here. One can assign heavier weight to incorrect ranking of a purchase vs. a click.
Implementation involves training a gradient-boosted tree model. Every training instance consists of a seed item, a recommended item, and the user’s final action on that recommended item. Features include user personalization signals, item similarity metrics, user location, and other contextual properties. Higher tree depth helps model interactions, but hyperparameters must be tuned carefully, including learning rate, number of trees, and sample weights for each relevance level.
Below is a representative formula for pairwise ranking loss with sample weighting, shown in its own line with big font:
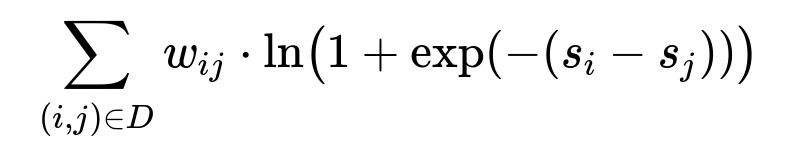
Where:
D is the set of all training pairs (i,j).
s_i is the predicted relevance score for item i.
s_j is the predicted relevance score for item j.
w_{ij} is a sample weight factor. For pairs involving a purchase, w_{ij} is higher. For pairs involving clicks or watchlist additions, w_{ij} is lower but still non-zero.
(s_i - s_j) determines the pairwise comparison. Minimizing this term encourages ranking relevant items (with higher user action signals) above less relevant items.
Train multiple variants with different weight configurations and track the offline metrics. Compare the average rank of purchased items, precision at top slots, and overall conversion. Then run online A/B experiments. Launch the model if it improves purchase count and ad revenue, confirming its real-world impact.
After deployment, monitor the distribution of user actions on recommended items. Use ongoing feedback to retrain or fine-tune the model. Adjust sample weights if certain signals degrade or user behavior changes over time.
Model accuracy also depends on correct item retrieval before ranking. Ensure retrieval surfaces items from a large pool but remains relevant. Combine textual similarity, categorical alignment, and collaborative filtering to produce a strong candidate set. Then finalize the ordering with the newly trained multi-level relevance ranker.
In code, a training loop using Python and a common gradient boosting framework could look like this (simplified illustration):
import xgboost as xgb
import pandas as pd
# data_df has columns: features..., label, sample_weight
train_data = xgb.DMatrix(data_df[feature_cols], label=data_df["label"], weight=data_df["sample_weight"])
params = {
"objective": "rank:pairwise",
"eta": 0.1,
"max_depth": 6,
"eval_metric": "ndcg"
# ... plus any other hyperparams
}
model = xgb.train(params, train_data, num_boost_round=500)
Explain to stakeholders that the final ranking score integrates multiple signals and is then optionally adjusted by ad rate or other business constraints. The marketplace remains aligned with its CPA model, charging only when a sale occurs.
Potential Follow-Up Questions
1) How do you decide which user actions to include in the multi-level labeling?
Users might perform different actions on various item formats. Examine the frequency of these actions and track how often they lead to eventual purchase. If some actions rarely predict a future sale, ignore them. Include those that strongly correlate with conversions.
2) Why not just keep a single binary label indicating purchase vs. non-purchase?
A single label ignores the fact that many relevant items do not get purchased for reasons unrelated to item quality (for instance, user budget constraints). Actions such as clicking or adding to watchlist hold meaningful partial intent signals. Incorporating these signals reduces false negatives and enriches model training.
3) How do you select the sample weights for each user action?
Search for optimal weights using a hyperparameter tuning approach. Split data, train the model with candidate weight sets, and track offline metrics like purchase rank and recall. Choose the best-performing combination. Validate by online A/B testing to ensure real-world gains.
4) How do you avoid penalizing items that are relevant but not clicked because the user purchased a different item?
Use multi-level feedback rather than simple binary labels. Consider items that were not purchased but received a strong action (like “add to cart”) as partially positive signals. Ensure the pairwise ranking model sees that such items have higher rank than items that received no engagement.
5) How do you handle new or rare item categories where you have limited historical user signals?
Use shared embedding or similarity-based approaches that generalize across categories. For items with minimal history, draw on their textual data (title or description) and metadata (price, shipping) to estimate similarity. As soon as new interactions appear, incorporate them into incremental model updates.
6) How do you balance the weighting of ad rate vs. pure relevance?
Apply a final re-ranking step that multiplies or otherwise combines the predicted relevance with the item’s ad rate. Calibrate the trade-off so that the platform does not surface only high-ad-rate items. Monitor user experience metrics (engagement, clicks, purchases) to verify that the ads remain relevant and profitable.
7) How would you maintain model freshness and handle concept drift?
Schedule periodic retraining. Stream recent user interactions into a data pipeline for near-real-time updates if needed. Watch for changing user behaviors (seasonal trends or emergent product categories). Adjust feature engineering, sample weights, and hyperparameters based on new data.
8) What offline metrics do you rely on before launching an online test?
Analyze average rank of purchased items, mean reciprocal rank, normalized discounted cumulative gain, and coverage across item types. Watch for consistent improvements. Then confirm everything with a small-scale production test before a full rollout.
9) How do you address the cold-start problem for new users with no prior history?
Use content-based signals or broad trending items. Show popular items in relevant categories. As soon as the user interacts with items, incorporate those signals and personalize. Consider look-alike modeling from users with similar browsing context or product interest.
10) How do you ensure the model does not degrade niche categories or risk a filter bubble?
Track performance across different segments. Ensure user diversity is preserved by having a wide set of items in the recall stage. If model metrics show coverage issues or repetitive items, reintroduce variety through recall rules or multi-objective optimization.
The multi-relevance ranking model addresses sparse purchase data and exploits additional signals to surface valuable items. This ensures a better user experience, improved item discoverability, and consistent revenue. The approach leverages a gradient-boosted tree ranker with carefully assigned weights and thorough A/B validation to confirm that it improves conversions while respecting the CPA model.