
ML Case-study Interview Question: Optimizing User Engagement with Scalable Machine Learning Recommendation Pipelines


Browse all the ML Case-Studies here.
Case-Study question
You are leading a Data Science team at a major tech organization aiming to optimize user engagement. The system processes large-scale user behavior data, then decides which content to promote. The prior approach used heuristic-based methods that led to suboptimal recommendations. The organization wants an advanced solution, leveraging recent progress in Machine Learning and Deep Learning, to increase user retention and platform growth. Explain how you would design a data pipeline, build machine learning models, handle production deployment, and evaluate the results. Propose a complete solution with specific technologies, data processing steps, modeling approaches, and metrics. Describe how to iterate and improve the system post-launch.
Proposed Solution
Use advanced feature engineering, model training, and an efficient deployment workflow. Divide the project into data ingestion, data transformation, model training, testing, and production rollout. Rely on robust feedback loops for continuous improvement. Combine user-level data signals with item-level content features. Use distributed data processing to handle large volumes. Integrate a real-time prediction service. Maintain strict monitoring of metrics. Retrain frequently to reflect changing user behaviors.
Data Ingestion and Architecture
Collect user logs from clickstreams, session durations, and interactions with various content types. Store them in a data warehouse that can scale horizontally, such as Apache Hive or a cloud-based equivalent. Process new data in near real-time by using a combination of micro-batch or streaming approaches. Choose a cluster-based distributed framework like Apache Spark for transformations and feature computations. Use a feature store for consistent access to standardized features across training and inference stages.
Feature Engineering and Modeling
Represent user content interactions by aggregating recency, frequency, and dwell-time signals. Encode content metadata with embeddings derived from a neural network that captures item similarity. Combine static features (user demographic) and dynamic features (recent user session activities). Train a predictive model to rank or score content items. Start with a simpler classification or regression algorithm for interpretability, then move to a deep neural network if performance gains are evident. For the ranking task, adopt a pairwise approach to compare two items or a pointwise approach to predict engagement probability.
Example Core Mathematical Formula
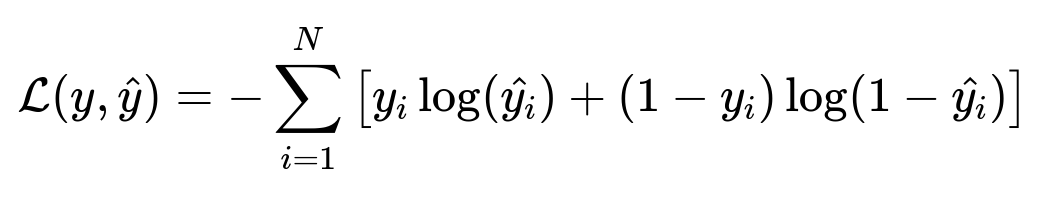
Here y_i is the ground truth label indicating user engagement, hat{y_i} is the model's predicted probability of engagement, and N is the number of training samples. The term log(...) denotes the natural logarithm. This expression measures the cross-entropy loss, which penalizes large deviations between the predicted probabilities and the actual labels.
Training Pipeline
Use offline historical data for initial model training. Split into training, validation, and test sets. Perform hyperparameter tuning using frameworks like scikit-learn or TensorFlow. Parallelize experiments with a cluster-based setup. Evaluate using metrics such as accuracy for classification or mean average precision for ranking tasks. Monitor overfitting with separate validation data. Check that the final model captures ephemeral user interests by testing on more recent time windows.
Production Deployment
Package the finalized model with any required feature transformations. Deploy as a REST-based microservice behind a load balancer. Use container orchestration for scalability, such as Kubernetes. Monitor real-time metrics (latency, resource utilization, request volume). Log prediction outcomes for future retraining. Follow a canary deployment approach, sending a small percentage of traffic to the new model while monitoring performance. Switch fully if metrics improve.
Observed Outcomes and Ongoing Improvements
Watch metrics like daily active users, session durations, and click-through rate. Assess distribution shifts by examining changes in user behavior, new content categories, and external factors. Retrain or fine-tune the model whenever engagement declines or the user base changes drastically. Validate that the feature store remains consistent with the production environment.
Code Snippet Example
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import log_loss
df = pd.read_csv("user_content_interactions.csv")
X = df.drop("label", axis=1)
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42)
model = RandomForestClassifier(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)
preds = model.predict_proba(X_test)
score = log_loss(y_test, preds)
print("Cross-Entropy:", score)
Explain that this simple pipeline can scale out with distributed computing. Use vectorized operations and transformations with Spark if the data is huge. Evaluate advanced approaches like a neural network with embeddings if random forests do not capture complex patterns.
How do you ensure data quality and correctness?
Implement automated checks at ingestion time to validate schema consistency and value ranges. Ensure features are consistent between training and inference by versioning data transformations. Handle missing data with either imputation or dropping if the proportion is small. Use frequent data reconciliation checks to catch inconsistencies.
How do you deal with user data privacy and compliance?
Mask personally identifiable information or store it in encrypted form. Create aggregate features rather than storing raw personal data. Follow regulatory guidelines for data usage. Conduct periodic privacy audits and incorporate user consent mechanisms.
What techniques handle model drift?
Monitor live predictions and compare distribution statistics to the training set. Use concept drift detectors that spot shifts in data distribution. Retrain with recent data to adapt to changes. Keep a window of the latest interactions to capture new patterns. Evaluate performance on a rolling basis to identify drift early.
How do you handle new content with no engagement history?
Use metadata and content embeddings derived from textual or visual signals. Infuse collaborative filtering to identify items similar to known content. Initialize item factors randomly, then update them as soon as any engagement data arrives. Integrate fallback recommendations if no signals are available.
How do you avoid a feedback loop?
Introduce random exploration to gather data beyond top-scoring items. Log outcomes even for less-confident recommendations to maintain coverage of the feature space. Create fresh training samples from the exploration traffic. Periodically evaluate exploration vs exploitation tradeoffs.
How do you handle latency constraints at scale?
Precompute features in a feature store. Use efficient model serving solutions that support GPU acceleration if needed. Cache partial results if repeated requests exist for the same features. Keep model size optimized through quantization or distillation if necessary. Track p99 latency in production logs to ensure real-time experience.
How do you iterate on the model architecture?
Experiment with new features and neural network architectures. Test gating mechanisms or attention-based layers for personalization. Compare offline metrics like cross-entropy or mean reciprocal rank, then do A/B testing in production for real-world feedback. Roll back quickly if engagement drops. Keep a stable baseline model on standby.
Why combine neural embeddings with user-level features?
Neural embeddings capture high-level semantic relationships among content items. User-level features capture personal preferences and contextual data. The combination helps the model identify synergy between user characteristics and item attributes, improving overall personalization.
What if the data distribution is extremely skewed?
Use sampling strategies or class-weight adjustments to address large class imbalance. Consider specialized metrics like AUC for performance tracking. Keep a representative test set to ensure generalization. Evaluate cost-sensitive losses if misclassifications of minority classes are critical.
How do you handle frequent re-ranking of items?
Cache predictions in short intervals. Recalculate on user activity triggers like new logins or major content updates. Use a streaming approach that updates partial user or item embeddings. Store the final scores in a low-latency key-value database. Invalidate stale predictions after a set interval or upon content changes.
How do you validate the success of the approach?
Track business metrics (user retention, user satisfaction surveys), as well as explicit engagement metrics (click-through rate, watch duration). Compare them to a control group or baseline model. Prove that the new system provides significant improvements with statistical tests like t-tests or confidence intervals on A/B test results.