
ML Case-study Interview Question: Enhancing Search Ranking Beyond GBDT Plateaus with Unified Deep Learning


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with improving a large-scale search ranking system that originally relied on a gradient-boosted decision tree model. That model has reached a performance plateau despite extensive feature engineering. Your team proposes migrating to a deep learning approach. The question is how to create and deploy a unified neural network ranking model, while ensuring it surpasses the decision tree baseline and handles massive traffic in production. Devise a complete solution strategy, including how you would handle feature engineering, modeling pipeline, training time, serving latency, and the final migration to production.
Proposed Detailed Solution
Overview
The team started with a gradient-boosted decision tree (GBDT) model for ranking. Performance gains slowed after adding many engineered features. Deep learning was appealing because it can learn directly from data distributions without excessive manual feature engineering. The first idea was an ensemble of GBDT plus a neural network. This required parallel inference, added complexity in feature engineering, and showed no significant offline improvement. A unified deep learning model was chosen instead to avoid maintaining two distinct systems and to reduce inference time.
Core Ensemble Formulas
One proposed approach was to let g(x) represent the GBDT model output, and h(x) represent the neural network model output. The ensemble score and its loss function were:
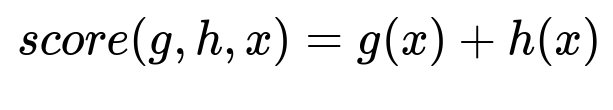
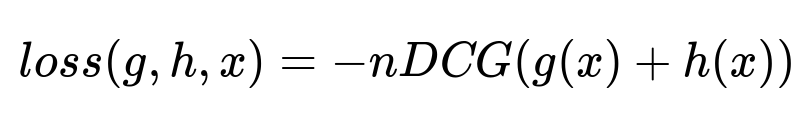
Here, x represents input features for both models, and nDCG means normalized Discounted Cumulative Gain. Offline tests showed no improvement. Infrastructure design was also more complex because it required parallel inference, and training needed both GBDT and neural network steps.
Transition to a Single Neural Network
The team switched to a unified deep learning model. Developer experience improved because only one system was maintained, training time decreased due to GPU acceleration, and serving latency was lower. It was straightforward to add domain-specific text embeddings. Larger data windows (about 40% bigger than before) improved the network’s performance. The new neural network leveraged custom embeddings of queries and items, leading to semantic representations more powerful than manual text similarity features.
Implementation Details
They refactored the entire pipeline using open-source components, such as Kubeflow Pipeline for orchestration and TensorFlow for training and inference. Data transformations were consistent across training and serving. Real-time features were integrated once they were converted to TensorFlow Examples, removing feature gaps between offline and online environments.
Final Online Results
An initial beta test without real-time/browser features revealed notable improvements for new listings and new users, likely due to robust semantic embeddings. After all features were fully integrated, parity or better performance was achieved. Deployment included scaling TensorFlow-based ranking to large traffic volumes. Once stable online results and performance parity were confirmed, the new neural model began replacing the legacy system.
Possible Follow-Up Questions
1) How would you ensure your neural network can handle complex text inputs effectively?
A well-trained domain-specific embedding layer is crucial. Off-the-shelf embeddings like BERT or other pretrained models might not capture unique user or item vocabularies in your domain. Training custom embeddings on in-house data ensures the text representations align well with the queries and items being ranked. In practice, a separate module that learns query–item embeddings can be attached to the main ranking architecture. By collecting query–item pairs (with signals such as clicks or purchases), the system learns more robust, domain-specific vectors than generic models would.
2) What are the primary challenges of moving from a GBDT pipeline to a deep learning pipeline?
Converting the data pipeline is often the biggest challenge. The GBDT system might rely on bespoke methods for feature extraction. Neural networks require more continuous or embedding-based representations. Ensuring consistent feature transformations from training time to inference time can be tricky. Infrastructure must also be updated. For instance, GPU acceleration lowers training time. However, online inference with GPUs or CPUs must be scaled properly. Monitoring also changes: neural networks might exhibit different failure modes, requiring updated logging and debugging tools.
3) How would you handle the risk that the neural network might overfit or underperform if not tuned properly?
Regularization (L2 weight decay, dropout, or batch normalization) and thorough hyperparameter tuning are crucial. Larger datasets are beneficial. A well-designed validation strategy monitors overfitting during training. Early stopping can help. Offline metrics like NDCG or Precision@K guide parameter selection. Finally, a staged rollout in production with A/B tests validates that offline performance translates to real traffic. If the model underperforms, collecting more labeled data or refining architectures can help.
4) Why might an ensemble of GBDT and neural network fail to improve results compared to a single neural network?
If the neural model already learns the relevant decision boundaries captured by the tree’s handcrafted features, the GBDT output might add little. Combining them also complicates training. Maintaining consistent coverage of features for both models becomes cumbersome. Extra inference time can degrade user experience, canceling out incremental ranking gains. If the single neural model is given enough capacity and properly tuned, it often surpasses a parallel ensemble for large-scale tasks, especially when domain-specific embeddings are used.
5) How do you handle real-time or session-based features that change quickly and need to be fed into the model?
Streaming data ingestion must be set up so that these features get processed on the fly. The data pipeline transforms them into the same format (for example, TensorFlow Example). Serving infrastructure must pull fresh signals (like current user behavior or session stats) and pass them to the model at inference. Feature parity checks ensure that training and serving transformations match. Caching layers may need to be minimized or carefully updated to avoid stale input. With advanced pipeline orchestration and event-driven data updates, the model can see the freshest possible features.
6) How would you justify investing in a complete pipeline overhaul instead of iterating on the existing tree-based system?
If a system hits a performance plateau, further increments in model complexity might yield diminishing returns. Neural networks can learn deeper abstractions, especially for tasks involving text, images, or user context. A new pipeline provides long-term gains in developer velocity. Training on GPUs can drastically reduce iteration time. Domain embeddings can directly encode semantic signals, making manual feature engineering less critical. Over time, the faster development cycle and improved performance offset the initial cost of redesigning the pipeline.
7) How do you ensure offline metrics (like NDCG) correlate well with real user satisfaction?
User satisfaction is often multi-faceted. The core offline metric might fail to capture some nuances. Validating that offline improvements persist in A/B tests is essential. Monitoring user behavioral signals (clicks, purchases, dwell time) is the ultimate test. Additional analysis or a multi-metric approach might detect trade-offs (for instance, short-term clicks vs long-term user retention). Continual experimentation and feedback loops ensure that the chosen metric aligns with user happiness.
8) Why is GPU acceleration more effective for neural networks than for GBDTs?
Neural networks involve matrix multiplications and backpropagation that GPUs handle efficiently in parallel. GBDTs rely on iterative splitting logic at decision nodes, which is less suited to GPU parallelism. This makes training a neural network far faster at scale. Consequently, you can train with larger datasets and iterate on hyperparameters more quickly. GBDT training can sometimes be parallelized on GPUs, but the gains are typically less pronounced than for neural networks.
9) What steps would you take to further push the performance of the new neural ranking model?
Experimenting with advanced architectures is common. Adding attention layers for queries and items might help. Additional domain features like user embeddings or context embeddings can be integrated. Monitoring for data drift ensures your model remains up to date. Incremental learning strategies can regularly refresh parameters, reducing latency between new data arrival and updated models. Exploring data augmentation can improve model robustness if data is sparse. Hyperparameter tuning or specialized optimizers might also boost performance.
10) How can you handle cold-start issues for items or users not seen before?
Embedding-based methods can capture semantic meaning from text, images, or metadata. An unseen item has text or images that the model can process without needing historical performance data. This lowers the reliance on historical click or purchase signals. For new users, the model focuses more on query context and item representations rather than user history. Continual updates of domain-specific embeddings improve cold-start performance as the model generalizes from similar items or queries.