
ML Case-study Interview Question: Scalable Global Time-Series Forecasting: Unified Pipeline for Diverse Streaming Markets.


Browse all the ML Case-Studies here.
Case-Study question
A large streaming platform has expanded to over 180 countries. They need robust and scalable weekly and on-demand user forecasts. They have three types of markets: Mature (with a rich historical dataset), New (with limited data, requiring a proxy-based approach), and Custom (markets requiring additional human involvement). The infrastructure must handle hyperparameter tuning at scale, generate automated insights, and allow manual interventions. How would you architect and implement a system that meets these requirements, ensures high accuracy, and accommodates evolving business needs?
Provide detailed reasoning on model design for each market type, hyperparameter tuning methods, infrastructure choices, data quality checks, and strategies for validating and adjusting forecasts. Explain how you would incorporate tooling and reporting to allow business stakeholders to refine the forecasts with forward-looking inputs. Include potential pitfalls, trade-offs, and resource constraints. Propose solutions to address cold-start problems. Describe how you would organize the pipelines for fast iteration without compromising quality control.
Detailed solution
Infrastructure Overview
Build one unified pipeline. After input data quality checks, branch into three workstreams for Mature, New, and Custom markets. Use parallelization where heavy computations are required, and separate core logic from peripheral logic. Use containerized Python jobs on a cluster manager to automate smaller tasks. Split hyperparameter tuning from daily or weekly inference to save resources.
Mature Markets
Collect historical user metrics. Remove disruptions that would skew time-series models. Run cross-validation over multiple hyperparameter configurations to capture different seasonal, trend, and holiday patterns. Evaluate a forecast error metric for each hyperparameter set.
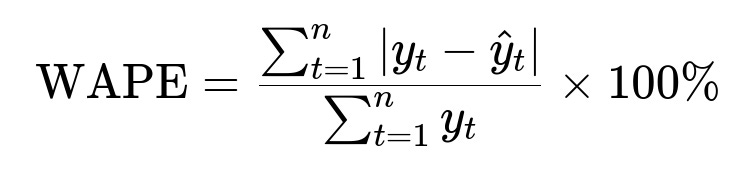
WAPE is Weighted Absolute Percentage Error. y_t is actual value at time t. hat{y}_t is forecasted value at time t. n is the total number of observations. This helps measure forecast accuracy by normalizing total errors by total actual values.
Choose the best-performing models based on aggregated validation error. Apply the best model over the full historical window, then forecast forward. Surface a final output for manual review. Publish forecasts and automated visualizations for stakeholders. Show historical data, model fit, error metrics, and forward projections.
New Markets
Have limited data. Identify “proxy” or look-alike markets by clustering external signals (macroeconomic or cultural) to find markets with similar user adoption patterns. Learn from these proxy markets’ launch curves. Adjust the growth trajectories with partial user data from the new market as it arrives. This approach addresses cold-start by transferring knowledge from established proxies.
Custom Models
Sometimes business input or experiment-driven logic is needed. Keep specialized models separate from the core system to preserve stability. Use the same final output quality checks. Provide an interface for stakeholders to inject forward-looking factors, such as planned marketing campaigns, that cannot be inferred from historical patterns.
Hyperparameter Tuning Strategy
Perform tuning offline once a week. Partition time series data into train and validation segments. Evaluate multiple error metrics if needed. Store hyperparameters in a metadata table and pass them to parallel workers. Keep the hyperparameter search space manageable to reduce costs. Use in-house or external orchestration to run large parallel jobs.
Quality Control
Separate stable, critical code such as data cleaning and model training logic into a well-tested Python library. Place visualizations, data exports, and notifications in a more flexible layer. Maintain unit tests for core components. Monitor anomaly detection dashboards with triggered alerts. Implement integration tests to verify data flow correctness.
Example Python Code Snippet
def time_series_train_validate(data, params):
# data is a preprocessed pandas DataFrame
# params is a dictionary of hyperparameters
train_data = data[data['date'] < params['cutoff_date']]
val_data = data[data['date'] >= params['cutoff_date']]
model = SomeTimeSeriesModel(**params)
model.fit(train_data['y'])
preds = model.predict(len(val_data))
error = weighted_absolute_percentage_error(val_data['y'].values, preds)
return error
This function shows how one might train and validate a simple time-series model. Additional parallelization would come from distributing this function over many markets and hyperparameter sets.
Practical Implementation Details
Use a cluster manager service for Dockerized jobs that run hyperparameter tuning in parallel. Store intermediate computations in a scalable data warehouse. Post-computation, apply the best model to the entire series. Provide a final forecast with anomaly checks. Expose results via internal dashboards or APIs. Log every step for reproducibility.
Potential Resource and Cost Constraints
Large-scale parallelization consumes computing resources. Trim hyperparameter search spaces by focusing on variables shown to affect accuracy. Build smaller models for some subsets if the cost is too high. Keep the system modular to pivot easily when product or infrastructure evolves.
Potential Follow-up Questions
What if the initial hyperparameter search yields suboptimal solutions for certain markets?
Perform targeted refinements. Analyze patterns in which markets fail. Narrow or expand hyperparameter ranges based on insights. Incorporate domain knowledge from regional experts. Possibly override certain results with a custom approach.
How to handle outliers or anomalies in time series data?
Remove or adjust known disruptions before training. Maintain a separate metadata table specifying dates and reasons for adjustments. Validate differences by checking final forecasts against known business events.
How to integrate external signals into forecasts?
Augment the training data with macroeconomic, cultural, or music consumption data. Encode these signals as additional regressors in the model. Keep an ablation test to confirm they improve accuracy. Ensure the data is updated regularly and remains reliable.
How would you scale this approach when doubling the number of markets?
Ensure the pipeline remains modular, with minimal shared state. Increase parallel workers in the hyperparameter tuning step. Cache intermediate results. Possibly reduce the number of hyperparameter sets for markets with stable historical patterns.
How do you handle frequent changes to business needs and new feature requests?
Maintain strict testing for the core logic. Keep new features as optional plugins or separate layers. Document each major change. Release new versions of the pipeline only after tests pass. Balance quick iteration with the stability required for user-facing forecasts.
How do you ensure business stakeholders trust the forecasts?
Provide intuitive visualizations of historical fits. Show error metrics. Present a simple interface for manual adjustments. Document methodology, quality checks, and known limitations. Communicate changes clearly whenever the pipeline or model logic updates.