
ML Case-study Interview Question: Using Classification to Detect Outdated Browsers and Boost Video Streaming Quality.


Browse all the ML Case-Studies here.
Case-Study question
The scenario involves a large video-streaming platform struggling with browser compatibility issues that lead to playback errors and poor user engagement. You are asked to propose a data-driven strategy to detect outdated browsers and recommend updates to improve overall user experience. You have user interaction logs, browser version data, and performance metrics. Suggest an end-to-end solution, covering data ingestion, feature engineering, modeling approach, infrastructure, and deployment. Propose ways to validate results and ensure long-term effectiveness.
Detailed solution
Data ingestion starts with collecting user sessions, timestamps, browser information, and playback events from logs. The goal is to create a unified dataset that links browser version to observed performance issues. Each record might contain browser name, version, playback start time, buffering duration, and abandonment rate. Join these records with the relevant user attributes that come from account information to see how different user profiles correlate with specific browser performance outcomes.
Feature engineering extracts predictive signals. One key feature might be the browser_version_minus_latest, which measures how far the user's browser version is behind the current release. Another might be average_buffer_time for each session. Additional attributes might include session_duration and repeated_errors_count. A final dataset might look like user_id, browser_version_minus_latest, average_buffer_time, session_duration, repeated_errors_count, and a target label indicating whether an error occurred.
Modeling approach
Supervised classification can predict if a user is likely to experience playback errors based on browser version and session behavior. A logistic regression or gradient boosting classifier can be used. Each input row is a session. The output is a binary label: 1 if the session had a performance issue and 0 otherwise. The training procedure optimizes a loss that measures classification accuracy.
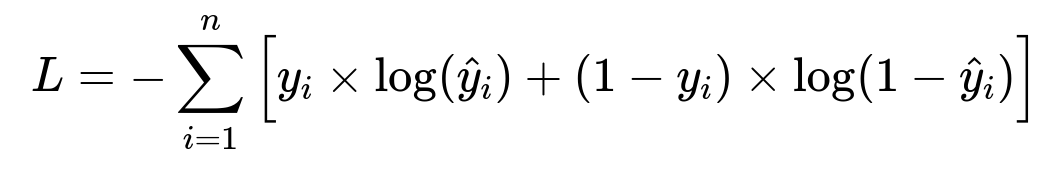
Here, n is the number of sessions, y_i is the observed label for session i, and hat{y}_i is the predicted probability of an error. Each coefficient in the model relates to features like browser_version_minus_latest. The model learns to assign higher error probability when that feature is large.
Training requires splitting the data into train, validation, and test sets. The model hyperparameters can be tuned with grid search or random search. Evaluate using area under the Receiver Operating Characteristic curve or F1 score. Overfitting checks with a validation set. Early stopping is used if the model stops improving.
Implementation steps
A pipeline in Python can manage data loading, feature processing, model training, and inference. Example snippet:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_auc_score
data = pd.read_csv("browser_performance.csv")
X = data[["browser_version_minus_latest", "average_buffer_time",
"session_duration", "repeated_errors_count"]]
y = data["error_label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1,
max_depth=3, random_state=42)
model.fit(X_train, y_train)
preds = model.predict_proba(X_test)[:,1]
auc = roc_auc_score(y_test, preds)
print("AUC:", auc)
The next step is to store the model using a framework like joblib. Integrating the model into a streaming platform involves intercepting user browser info at session start, passing it through the model, and returning an update prompt if the predicted error probability is above a threshold.
Deployment
Deploy the model on scalable infrastructure. Inference requests come from web services where each user’s browser data is fed into a real-time prediction service. A threshold on predicted error probability triggers a user prompt to update. Monitor system performance by tracking how many updates are recommended and how many people actually update.
Maintenance and monitoring
Data drift checks ensure that model assumptions remain valid. Periodically retrain with new data. Track user engagement metrics, content watch times, and decline in reported errors. Validate that the solution remains effective for new browsers or major version upgrades.
Possible follow-up questions
How would you handle users who are on rare or unsupported browsers?
Rare browsers create edge cases with very few data points. The model might fail to learn stable patterns. One approach is to set a default rule-based strategy for browsers not seen frequently. This strategy can be a conservative threshold that prompts an update if the browser is far behind the latest version. It is also possible to group rare browsers by family if they share underlying engines.
How do you ensure privacy when collecting browser and session data?
Use data aggregation and anonymization at the ingestion layer. Map unique user identifiers to random tokens. Store only essential fields needed for modeling. Retain logs for a limited duration. Implement access controls on logs so that only the machine learning platform can retrieve them. Comply with data protection regulations by respecting user consent and removing personal identifiers.
How would you handle real-time inference at scale?
A real-time prediction service would receive inputs via an endpoint. Containerize the model using a framework like Docker, then orchestrate with a system like Kubernetes for horizontal scaling. Cache frequent predictions to reduce load. Use asynchronous calls if necessary. Keep an eye on latency using metrics that measure the time from request to response.
How do you detect overfitting in production?
Compare the error rate the model predicts with actual observed errors on new data. If offline metrics are high but production errors remain, overfitting is likely. Keep track of a hold-out set that was never used in training or tuning. Monitor feature drift. Retrain if performance drops. Use a champion-challenger approach to compare the current model with a simpler baseline to see if it is truly outperforming.
How would you handle changing browser versions and user interface patterns?
Include version release data in your pipeline. Update the model features when a new browser release occurs. Keep data on how each release correlates with errors. Train the model to incorporate these signals. Develop an automated system that checks if a new browser version is significantly behind the official release. If changes in user interface patterns shift user behavior, gather fresh data on user interactions and expand the feature set to cover new usage patterns.