
ML Case-study Interview Question: Two-Stage Semantic Models for Precise Multi-Intent Food Search Retrieval


Browse all the ML Case-Studies here.
Case-Study question
A hyperlocal food-delivery platform wants to improve the relevance of search results for complex customer queries containing multiple intents, like dietary preferences, preparation style, and cuisines. The platform’s menu items exceed millions, and real-time latency constraints are strict. How would you design, train, and deploy a two-stage language-model-based retrieval system to ensure items relevant to a query are retrieved first in a ranking pipeline?
Additional details
The platform caters to a multilingual environment with Indian and international cuisines. Historical data shows queries often combine different dish categories, dietary descriptors, and meal-time references. Many query keywords do not match item titles exactly, requiring a deeper understanding of semantic similarity. Real-world usage must handle both dense hyperlocal menus and sparser regions, ensuring consistent performance.
Proposed solution
A small pre-trained semantic model is selected for embedding generation based on latency constraints. The solution involves a two-stage fine-tuning strategy. The first stage is an unsupervised adaptation of the model to domain-specific text, and the second stage is a supervised approach using curated query–item pairs.
Stage 1 (Unsupervised Fine-tuning) Collect historical search data that led to successful orders. Combine the query text, purchased item name, and relevant metadata (dish category, cuisine, preparation style) into a single textual record. Distort each record by deleting or swapping tokens. Pass these noisy sentences to the transformer encoder to produce sentence vectors, and reconstruct the original sentences using a decoder. The model learns domain nuances for food-related text.
Stage 2 (Supervised Fine-tuning) Curate complex queries and their relevant item names. Use these pairs in a Siamese-style training setup where the query is the anchor, and the relevant item is the positive sample. Random negatives serve as distractors. The model uses Multiple Negatives Ranking Loss. This aligns embedding vectors of query–item pairs that are semantically similar while separating those that are not.
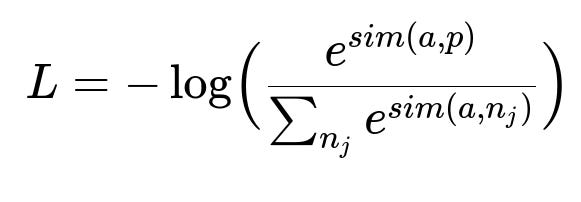
The anchor a represents the embedding of the query. The positive p is the embedding of the matching item. The negatives n_j are the embeddings of unrelated items. The function sim(x,y) measures similarity (often cosine similarity).
Model Deployment and Retrieval
Combine the fine-tuned model with an efficient approximate nearest-neighbor search or a similarity-based filter to retrieve top items for each query. Handle real-time traffic on CPU with minimal latency by optimizing model size and using vector databases or indexes. The system iterates with incremental training by collecting problematic queries over time, refining the supervised dataset, and retraining.
Monitoring and Metrics
Monitor Mean Average Precision (MAP), Precision@k, and user-specific metrics across different hyperlocal zones. Compare performance with classical string-matching algorithms or earlier baselines. When new cuisines or special items are introduced, retrain or expand the curated data.
What if the model encounters query terms outside its training vocabulary?
Handling out-of-vocabulary terms requires domain adaptation. Synonym expansions, subword-tokenization coverage, and continuous incremental training help. Maintaining a fallback mechanism (like a text-matching approach for rare terms) ensures coverage.
How would you handle queries containing multiple languages or transliterated text?
Extend domain corpora to include multilingual or transliterated text. Include examples where regional dish names appear in multiple scripts. Fine-tune with these samples so the encoder learns cross-lingual representations. Subword or byte-level tokenizers also improve robustness.
How do you ensure consistent performance across sparse and dense hyperlocal regions?
Benchmark retrieval on regions with different menu sizes. Validate MAP and Precision@k for each area. If the region is small, consider shortlisting items first with a faster textual match before applying embeddings. Check distribution shifts in item popularity across locations and periodically retrain.
How would you handle large-scale traffic in production?
Run the embedding inference on GPU or optimize CPU-based batching. Use approximate nearest-neighbor indexing for retrieval. Cache popular queries’ embeddings. Parallelize or shard indexing across multiple nodes. Monitor end-to-end latency and scale cluster resources if usage spikes.
How would you measure real-time relevance improvements?
Track user engagement metrics like click-through rates, add-to-cart rates, and final order conversions. Compare with a control group to see if the new ranking approach lifts these metrics. Conduct A/B tests to validate improvements under real-world load.
How would you handle queries seeking dietary preferences, like “protein-rich gym food”?
Gather curated samples linking such queries to relevant items like whey shakes or protein salads. Ensure the model includes metadata about nutritional attributes. Include a strong supervised component for these specialized queries. Incrementally retrain whenever new diet trends or items enter the menu.
How do you avoid data leakage or overfitting?
Partition training data by time. Ensure the curated dataset does not include future items only available after the training period. Regularly evaluate on new data. Control the model’s capacity and monitor training metrics, ensuring minimal overfitting or memorization of item names that no longer exist in the menu.
How do you manage pipeline updates?
Keep a versioned approach. Freeze older model checkpoints for fallback. Run new fine-tuning with fresh curated data. Validate offline using held-out sets or synthetic queries. Deploy the new model behind a feature flag or partial rollout to check stability. Collect new real-time feedback and iterate.