
ML Case-study Interview Question: Hybrid Neural Recommendations: Adapting to New Products and Shifting User Preferences


Browse all the ML Case-Studies here.
Case-Study question
A large consumer platform wanted to upgrade its AI-based recommendation engine to enhance user engagement and revenue. They collected behavioral logs, transaction histories, and product metadata from millions of users. Their existing model underperformed when tested on new seasonal products or when user preferences shifted rapidly. You are asked to propose a new approach, explain how you would handle feature engineering, model architecture, training pipelines, and real-time serving, then outline a plan to monitor long-term performance and prevent model drift.
Proposed Detailed Solution
This solution integrates user session data and product attributes. It captures changing preferences quickly, updates predictions on new items, and measures performance robustly. It balances complexity with production feasibility.
Data Collection and Preprocessing
Combine historical events, user profiles, and product details in one data warehouse. Aggregate user actions such as clicks, favorites, or purchases and join them with structured product data. Clean missing or corrupted fields. Deduplicate repeated events. Generate features for user behavioral patterns (time-based, frequency-based) and product stats (ratings, categories).
Feature Engineering
Create embeddings for text descriptions. Encode metadata (brand, category) and user attributes (age bracket, region). Include frequency-based signals like session counts or average dwell time. Use interactive features like user-product pair histories. Normalize continuous variables. Embed categorical variables using a trainable layer in a neural model or one-hot encoding for simpler approaches.
Model Architecture
Use a neural collaborative filtering network or a hybrid approach combining matrix factorization with a feedforward layer that processes explicit features. Train with user-product pairs and negative samples. For textual data, incorporate a pre-trained transformer encoder to extract relevant context embeddings. Concatenate item embeddings and user embeddings, then pass them through feedforward layers.
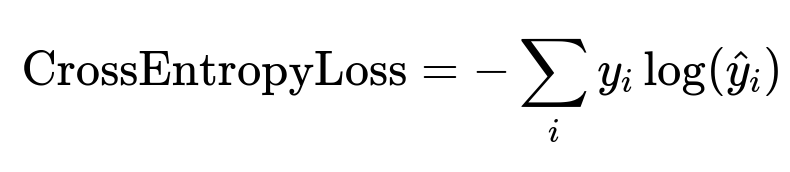
Where y_i is the ground truth indicator for class i, and hat{y}_i is the model's predicted probability for class i. This measures how well the model ranks relevant items over irrelevant ones. Minimizing it improves recommendation quality.
Pipeline and Training
Use distributed processing for large data volumes. Partition user and item data by time to emulate real-world flow. Perform early stopping when validation metrics stall or degrade. Apply hyperparameter tuning on hidden layer sizes, learning rate, and embedding dimensions. Use robust shuffling strategies to prevent training on data that leaks future user preferences.
Real-Time Serving and Online Learning
Deploy a model-serving architecture with a low-latency endpoint. Cache frequent user-item representations in memory. Retrain or fine-tune the model daily or weekly on new logs. Use feature stores to manage transformations consistently between offline and online pipelines.
Monitoring and Maintenance
Track metrics such as click-through rate, product coverage, and average purchase value. Implement an A/B testing system for new versions. Detect data drift by comparing statistical distributions of user interactions over time. Retrain when drift crosses a threshold. Store model outputs and actual outcomes for audit and error analysis.
Example Python Code Snippet
import torch
import torch.nn as nn
import torch.optim as optim
class HybridModel(nn.Module):
def __init__(self, user_dim, item_dim, hidden_dim):
super(HybridModel, self).__init__()
self.user_embedding = nn.Embedding(user_dim, hidden_dim)
self.item_embedding = nn.Embedding(item_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim * 2, hidden_dim)
self.output = nn.Linear(hidden_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, user_ids, item_ids):
user_vec = self.user_embedding(user_ids)
item_vec = self.item_embedding(item_ids)
x = torch.cat([user_vec, item_vec], dim=1)
x = torch.relu(self.fc(x))
return self.sigmoid(self.output(x))
# Assume user_dim=1000000, item_dim=50000
model = HybridModel(user_dim=1000000, item_dim=50000, hidden_dim=64)
loss_fn = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
Train by sampling positive interactions (user, item) and negative samples (user, random item). Forward pass, compute loss, backprop, update weights. For online learning, periodically load fresh data batches.
What if the training data distribution keeps shifting over time?
Use incremental training. Validate with rolling windows. Implement a streaming data pipeline to capture changing behaviors daily or weekly. Maintain a stable baseline model and a more frequently updated model. Evaluate performance on hold-out sets that represent future data segments.
How do you deal with sparse interactions for rarely viewed items?
Introduce item-based embeddings that generalize across similar attributes. Group items by category or content vectors. Increase negative sampling frequency for sparse items. Use techniques like hierarchical classification or product taxonomy embeddings.
How do you handle large-scale embedding sizes without running out of memory?
Use hashing or dimension reduction. Partition the embedding space into multiple sub-embeddings. Prune inactive users or items based on usage. Store full embeddings on disk and load segments on demand. Implement approximate nearest neighbor queries for item lookups.
How do you manage interpretability and trust in black-box models?
Develop explanation modules for user-facing staff. Show top contributing features or item similarities. Compare neural predictions with simpler baseline models. Log input features during inference. Periodically measure alignment with fairness criteria or business rules.
Why might a single neural model underperform if user behavior changes rapidly?
Neural models can overfit stable historical patterns. Real-time changes in product popularity or user interests might cause mismatch. Rapid retraining or fine-tuning, plus fresh negative samples and evolving embeddings, helps maintain alignment.
How do you prevent data leakage when training with different temporal windows?
Partition data by transaction timestamp. Keep training sets strictly prior to validation/test sets. Implement time-based cross-validation. Avoid user features that depend on future data. Monitor performance on sequentially withheld slices.
How would you ensure the pipeline handles high-traffic inference loads?
Use a scalable serving cluster with GPU acceleration or CPU optimizations. Batch multiple inference requests. Cache repeated user embeddings. Profile bottlenecks and optimize I/O. Use asynchronous queues when waiting for model responses.
What if offline performance metrics conflict with online metrics?
Run controlled experiments in production. Compare user engagement, bounce rates, or short-term conversions. Combine offline cross-validation with limited-release A/B tests. Optimize for a weighted combination of offline and online metrics.
How do you orchestrate model deployment in a large engineering ecosystem?
Integrate with a CI/CD system. Containerize the model. Register metadata (model version, training set) in a central registry. Implement rollbacks when metrics degrade. Use feature flags to swap models gradually. Schedule automatic retraining jobs.
How do you handle cold-start for new users or items with minimal data?
Use content-based features extracted from text or images. Generate initial embeddings from item metadata. Assign a default or learned user embedding for brand-new users. Refine the embeddings once enough interactions are collected.
How do you confirm the system's performance gains hold up under real-world load and session complexity?
Track a robust set of metrics. Measure average response time, error rates, user-level predictions. Audit model decisions against real user actions. Continuously capture feedback. Conduct random holdout groups that remain on the old system to confirm improvements statistically.