
ML Case-study Interview Question: Robust Media Recommendations: Data Consistency, Drift Detection, and Automated Retraining


Browse all the ML Case-Studies here.
Case-Study question
A media-streaming platform wants to improve the personalized content on its main landing page. They have two stages in their recommendation system. Stage 1 uses a model that generates candidate items (albums, podcasts, playlists). Stage 2 ranks these items. The engineering team reports frequent data inconsistencies during training and inference, which degrade recommendation quality. They also struggle to detect data distribution shifts over time and want an automated retraining pipeline. How would you design a solution for candidate generation and ranking, ensure consistency between training and serving data, handle data validation, and deploy an automated system for retraining and serving at scale?
Detailed solution approach
Candidate generation should fetch potentially relevant items. These items could be older content the user has listened to, or new content inferred from user-activity and metadata. At large scale, generate these candidates offline or via a real-time microservice. In both approaches, unify the feature transformations for both training and inference. Logging features at inference time ensures the same transformations feed the offline training pipeline. Maintain a single code path that fetches, normalizes, and encodes features.
Ranking then reorders candidates in real time. Employ a model that accounts for user context, item attributes, and interactions. A real-time model server should expose an endpoint that receives user context and item features, then returns the predicted engagement probability. Ensure the ranking model receives the same features that were used to train it. This consistency is crucial for accuracy.
In production, data pipelines can automatically log transformed features. A scheduled batch pipeline can collect them for model training. Another pipeline can label data by detecting whether the user played or skipped the recommended item. This labeled dataset feeds weekly or daily retraining. Use a workflow orchestration tool (for example, Kubeflow pipelines) to schedule the entire retraining process. Retrieve the fresh dataset, conduct feature transformations, train the model, and push the model to a serving environment if performance meets a threshold.
Data validation monitors distribution of training vs serving features. Any drift triggers alerts. Compare distributions with a distance metric. The Chebyshev distance can measure drift on numeric features. To show the formula:
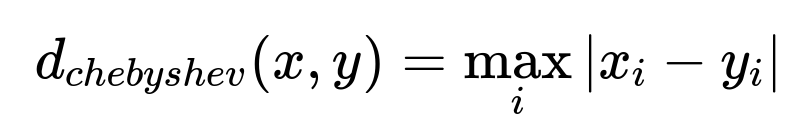
x_i and y_i are feature vectors for different time windows. If the distance surpasses a threshold, investigate pipeline changes or anomalies. Logging leads to consistent transformations and detection of any mismatch quickly.
Candidate generation code snippet example
import apache_beam as beam
from datetime import datetime
def transform_features(raw_record):
# Transform raw fields into model features
return {
"user_id": raw_record["user_id"],
"item_id": raw_record["item_id"],
"normalized_popularity": raw_record["popularity"] / 100.0,
"time_of_day": datetime.utcfromtimestamp(raw_record["timestamp"]).hour
}
p = beam.Pipeline()
raw_data = p | "ReadInput" >> beam.io.ReadFromParquet("gs://path/input.parquet")
features = raw_data | "TransformFeatures" >> beam.Map(transform_features)
features | "WriteOutput" >> beam.io.WriteToParquet("gs://path/transformed.parquet")
p.run()
Transform raw data into consistent features for both training and serving. Store them in a format accessible for training pipelines and real-time inference.
Validation and monitoring approach
Another component ensures training and serving features match. During training, compute statistical summaries and schemas. Compare them against serving data. If a mismatch arises, generate alerts. The pipeline may pause new model deployments until an engineer inspects the discrepancy. This setup stops subtle errors that degrade recommendations over time.
Automated retraining and deployment
A model’s performance can degrade if user preferences evolve. Weekly retraining is often sufficient. Configure the workflow to trigger each week. Train, validate, and compare to the existing model. If metrics exceed a set threshold, the pipeline automatically pushes the new model to the real-time serving layer. Version the model for rollback in case online metrics degrade.
How would you handle concept drift if the user preferences change faster than expected?
Use more frequent retraining or an adaptive mechanism that updates the model with streaming data. Implement real-time incremental updates. If logging shows major changes in user interaction, accelerate retraining. Monitor online metrics such as click-through rate or time spent on content. When metrics drop below an acceptable margin, schedule immediate retraining.
How do you ensure the model does not produce poor-quality predictions when online features are missing?
Use default values or imputation for missing features. Tag any record that lacks a critical field and decide how to handle it. Some item features might be optional, but user context data might be mandatory. If essential data is missing, skip or delay the prediction and log an anomaly event. Investigate any spike in anomalies to fix data ingestion problems.
How do you deal with computational constraints when generating candidates in real time for millions of users?
Run a distributed retrieval system. Cache frequent users’ top candidates in memory. Use approximate nearest neighbor search if the model relies on embeddings. Incrementally refine the top items. Keep the system scalable by splitting load across microservices that handle candidate generation. A well-indexed offline pipeline can handle bulk computations, while real-time requests fetch from these cached or precomputed results for speed.
How to debug a potential data mismatch issue that is causing suboptimal recommendations?
Check the feature transformations in training and inference code. Compare output distributions from training logs vs serving logs. Look for shifts in mean or range of features. Inspect an example user flow end to end, capturing raw input, transformation steps, and final predictions. Confirm if the raw data is correct, and whether any transformations differ between training and serving code. If the mismatch persists, revert to a simpler pipeline to isolate the error.
How do you ensure that changes in the data pipeline or transformations will not silently affect model performance?
Adopt a strict schema management approach. Maintain automated checks using data validation libraries. Track mean, standard deviation, and other descriptive statistics for each feature. If new code changes distribution thresholds, raise alerts. Force code reviews for any pipeline change that modifies transformations. Monitor production model performance daily. If performance dips beyond a threshold, immediately investigate and roll back the change if necessary.
How do you handle edge cases where newly joined users have no historical data?
Leverage cold-start strategies. For new users, rely on popular items, trending items, or anonymized user segments. After these users engage with a few recommendations, incorporate that feedback in the next iteration of the model. Some advanced methods infer user embeddings from minimal interactions. Keep separate logic for new users vs returning users until enough data accumulates for the main model.
How do you quantify success of the new approach once deployed?
Monitor both offline metrics and online metrics. Offline metrics might be precision at k or recall at k on historical test data. Online success relies on engagement metrics such as click-through rate or time spent. A/B test the new candidate generation or ranking approach against the old approach. If key metrics improve significantly, adopt the new method. Keep an eye on user retention and satisfaction to confirm that short-term gains align with long-term value.