
ML Case-study Interview Question: LLM-Powered Natural Language to Query Translation Using Schema Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A major online platform decided to build a feature that translates plain-language analytics questions into an internal query format using a commercial Large Language Model. They faced issues with large schemas exceeding context window limits, unpredictable latency from vendor-hosted LLMs, and prompt injection risks. They also needed a robust legal and compliance framework to accommodate enterprise customers. How would you design and implement a solution that transforms natural-language questions into valid analytical queries? Outline architecture, techniques to handle big schemas, methods to reduce latency, prompt-injection mitigation steps, and key compliance considerations.
Detailed Solution
They used a core architecture where the system collects user text, merges it with relevant schema details, and sends that to an LLM. The LLM outputs a machine-readable query. The system parses and validates that query before executing it. They carefully restrict destructive actions so the LLM never makes irreversible changes. They also rate-limit usage. They place the LLM behind an interface that focuses on generating queries in response to plain-language inputs, not running arbitrary commands.
They tackled large schema problems by limiting schema fields to only those active in recent traffic. When schemas were still too big, they truncated the least-used fields. They tested an embedding-based approach to dynamically fetch the most relevant fields instead of the entire schema. They computed similarity using dot product on vector representations of field names and descriptions.
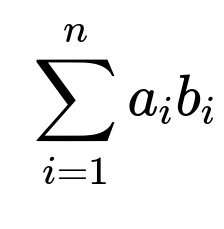
Here, a_i and b_i are embedding components for field vectors. A higher sum means greater similarity. This approach helped reduce context usage. They discovered large-context LLMs could accept the entire schema but often ran slower and hallucinated more, so they found embeddings more reliable.
They tried chaining multiple LLM calls but faced higher cumulative latency and an increased chance of errors. They noted that repeated calls amplify failure probabilities if each call can sometimes produce an invalid query. Instead, they refined a single-call prompt by adding carefully curated examples. They included instructions on how the final query must look, plus domain context. They avoided a separate chat-style interface. They only gave the user a single entry box for natural-language input.
They handled prompt injection by validating that the LLM’s output matched a strict query schema. They disabled dangerous operations. They truncated any suspicious output that exceeded expected length. They refused to connect the LLM to critical internal systems. They offered a simple toggle for enterprise users who refused to send even metadata to the LLM provider.
They tackled legal challenges by updating terms of service, clarifying that data may be sent to a third-party LLM vendor. They also created separate terms that governed AI usage. They identified customers under strict privacy agreements and disabled the feature for them until special arrangements were made.
They discovered the LLM alone was not a product. They needed standard product-design steps like user research, iterations, and usability testing. They tested with a small internal group, expanded the pool gradually, then released widely once they observed robust performance. They only recognized success once real users could generate consistent queries without repeated corrections.
They used Python for the main integration. A sample snippet follows:
import requests
def generate_query(user_question, schema_data, examples):
prompt = build_prompt(user_question, schema_data, examples)
llm_response = call_llm_api(prompt)
raw_query = parse_and_validate(llm_response)
return raw_query
def call_llm_api(prompt):
# Example usage of a third-party LLM service
api_response = requests.post("https://example-llm-api.com/completions", json={"prompt": prompt})
return api_response.json()["output"]
The core logic builds a long prompt that includes recent schema fields, a few examples, and explicit instructions. The system parses the response as structured text, discards invalid sections, and only proceeds if the validated query meets known constraints.
Follow-Up Question 1: How do you handle ambiguous user inputs?
Short answers may produce partial queries. They added fallback logic that defaults to a broad query in such scenarios. The LLM prompt tries to provide a “best guess” query, then the user can refine. If the text is too vague, the system surfaces a warning to encourage more details.
Follow-Up Question 2: How do you ensure queries are valid and secure before running?
They store the model output in a temporary structure. They validate all clauses against the known schema. They reject any queries referencing fields that don’t exist or contain malformed syntax. They forbid destructive commands. They keep logs for auditing and debugging. They never automatically run queries that fail validation.
Follow-Up Question 3: How do you measure success or effectiveness?
They monitor query completion rates, query-correction frequency, and user satisfaction. They observe how many queries result in correct visualizations without manual intervention. They also track LLM latency to see if the system remains responsive enough. They watch for prompt injection attempts or unusual errors that appear in the logs.
Follow-Up Question 4: How do you address the context window problem at scale?
They shorten the schema to recent fields. They evaluate embedding-driven field retrieval if the schema remains huge. They plan to “test in production” by measuring final query accuracy when using embeddings for dynamic field selection. They skip chaining LLM calls, given latency trade-offs. They also watch for future large-context LLM solutions once stability and speed improve.