
ML Case-study Interview Question: Building Thematic Travel Collections with Machine Learning and Human Review.


Case-Study question
A travel-booking platform is shifting from a destination-based search to a category-based search. They want to group unique listings into thematic collections (for example, “Lakefront,” “Cabins,” “Historical Buildings,” “Skiing”) and display them on the homepage or after a user enters a destination. Their goal is to showcase interesting listings in lesser-known places and inspire users to book outside the typical popular spots.
They must assign each listing to relevant categories, select a standout cover image to represent the listing in each category, estimate the listing’s overall quality tier, and then rank listings within that category. They also want to rank the categories themselves to highlight the most relevant themes for different contexts, such as seasons or user locations.
Design a machine learning pipeline that solves these problems at scale and handles large volumes of incoming listings. Propose how to ensure high accuracy despite minimal time before the launch. Discuss how to embed a human-in-the-loop process to improve model performance over time. Finally, detail how you would handle ranking categories in different contexts (for example, winter vs. summer locations) and rank the listings within each category by quality. Address any potential data challenges, algorithmic considerations, and production-level constraints.
Detailed Solution
Overview
The main tasks are:
Generating candidate listings that might belong to each category.
Confirming those candidates via human review and model predictions.
Assigning each listing a cover image.
Estimating the listing’s quality tier.
Ranking categories and listings.
Candidate Generation
A rule-based approach can quickly identify listings that likely match each category. For instance, a “Lakefront” category might rely on textual mentions of “lakefront” in the listing title or user reviews, geolocation near a known lake, and references to water activities nearby.
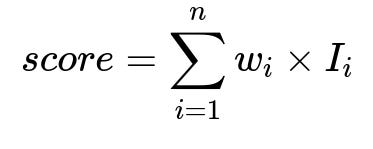
Where:
w_i are the weights assigned to each indicator (for example, distance to a lake, keywords in reviews).
I_i are binary indicators capturing whether a listing meets that criterion.
Higher score means stronger likelihood of belonging to the category. A threshold on this score produces an initial set of listing-category candidates.
Human-in-the-Loop Verification
An internal review team examines each candidate listing for certain categories, confirms or rejects the assignment, chooses the best cover image, and sets a quality tier (for example, “Most Inspiring,” “High Quality,” “Acceptable,” “Low Quality”). This manual feedback refines training data for the next stage.
ML Classification
A supervised model (for example, logistic regression or a neural network) then learns from human-labeled data. The model ingests features like listing text, review text, images, and geolocation. It outputs a probability that the listing belongs to a specific category.
Listings with scores above a certain high-precision threshold skip manual verification and go directly to production. Those in the uncertain range move to the review queue for human labeling. As the model re-trains, its performance improves, reducing manual overhead.
Quality Estimation and Cover Image Selection
A separate quality model predicts each listing’s overall tier, using booking performance, user ratings, image clarity, and text signals. Another model (for example, a vision transformer or CNN) identifies the best category-specific cover photo. The final system merges these outputs to present each listing with a compelling image and a quality label.
Category Ranking
The platform’s homepage shows multiple categories. A ranking model selects which categories appear first. It considers:
Season (for example, “Skiing” first if winter).
Location context (for example, highlight “Cabins” in mountainous areas).
Inventory coverage in each category (do not show a category with sparse listings).
Popularity or booking data.
Listing Ranking Within a Category
Within each category, the system sorts higher-quality listings near the top to achieve a “wow” effect. The rank can also reflect how confidently the model assigned the listing to that category (human-confirmed vs. model-only). The final ordering balances consistency (so the first listings shown are truly “on brand” for the category) with variety (so users see different styles or price ranges).
Implementation Details
Use stable and proven libraries for classification and vision tasks. Represent textual data with embeddings, and rely on geospatial services for location features. Store final assignments in a centralized database with fields for (listing_id, category_id, quality_tier, cover_image). Automate the retraining pipeline to incorporate fresh human labels each week or month.
What-if Follow-up Questions
How would you prioritize which listings to send for human review?
Aim to maximize the value of each manual review. Set a threshold on the ML model’s probability. High probability listings above that threshold can skip review. Lower probability listings get sorted by how important or high-exposure they are. A high-end property in a major region might get reviewed first, so those categories become more accurate where it matters most. Also consider coverage: if some categories lack enough confirmed listings, prioritize sending those for review.
How do you handle data drift for categories that rely on location-based signals?
Monitor changes in geographic data sources. Maybe new lakes or attractions appear, or old data becomes outdated. When changes occur, re-score all listings in those areas. Update the location-based indicators for new or removed points of interest. The retraining pipeline must incorporate these new signals to avoid stale or incorrect category assignments.
What if an image classifier mislabels a cover photo or picks a poor-quality image?
Maintain a fallback approach that defaults to the highest-rated photo (based on clarity and aesthetic features) if the classifier’s confidence is low. Periodically conduct quality audits on auto-selected images. Introduce user feedback loops (for example, a user can flag an image mismatch).
How would you handle a new category with minimal labeled data?
Start with rule-based signals or embeddings to identify approximate matches. Label a small set of those. Train a model on that small set. Perform iterative expansion by embedding similarity searches. Each new batch of confirmations enriches the labeled pool. Over time, the model improves enough to cut down on manual curation.
How do you ensure that category ranking is personalized or season-aware?
Incorporate user features (previous travel patterns, wishlists, browsing history) into a personalized category-ranking model. For seasonality, feed in the current date or season as an additional input. Maintain a dynamic weighting system so categories relevant to the user’s location or season float higher.
How do you maintain high precision when your coverage expands rapidly?
Set strong thresholds on ML classification. Expand coverage gradually with retraining cycles. Keep the human review step for uncertain predictions. Monitor user feedback (click-through rates, search queries, booking conversions) as a validation signal. If a category yields poor user engagement, investigate the model’s outputs and refine it.
Can you outline a sample Python snippet for training the listing-to-category classifier?
Below is a simplified code example:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# Sample dataset with features and binary labels for one category
data = pd.read_csv("listings_training.csv")
X = data[["indicator1", "indicator2", "indicator3", "location_signal"]]
y = data["category_label"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
# Evaluate
val_preds = model.predict_proba(X_val)[:,1]
threshold = 0.8 # set to ensure high precision
val_labels = (val_preds >= threshold).astype(int)
precision = sum((val_labels==1) & (y_val==1)) / sum(val_labels==1)
recall = sum((val_labels==1) & (y_val==1)) / sum(y_val==1)
print("Precision:", precision)
print("Recall:", recall)
This code trains a logistic regression classifier for one category. In reality, each category has its own model. The probability threshold is chosen based on desired precision. Predictions above the threshold can go live. Others go to human review.
Stay thorough with data collection and feedback loops. This ensures continuous improvement of category assignments, image selection, and final ranking. The pipeline’s correctness depends on robust feature engineering, stable labeling, and careful thresholding.