
ML Case-study Interview Question: Embedding-Based Pipeline for Large-Scale Travel Image Moderation, Deduplication, and Similarity.


Browse all the ML Case-Studies here.
Case-Study question
You are part of a large travel platform that aggregates millions of activity images from multiple sources. Your task is to ensure only safe, relevant, and uniquely diverse images are used across marketing campaigns and product pages. How will you design an end-to-end pipeline that handles image uploads, moderation, deduplication, smart cropping, and large-scale similarity detection? Explain all technical choices, potential bottlenecks, and how you would validate your system.
Detailed Solution
Overview of the pipeline
Image files arrive from various partners, tour providers, and internal teams. Each upload must be checked for safety, malware, contextual appropriateness, and brand alignment before storing in an image repository. A single unique version of each image is kept, identified by its hash. Marketing units need to avoid near-duplicates when selecting images. A reliable similarity approach ensures diverse imagery in campaigns.
Malware and safety checks
Shortly after an image is received, an antivirus scan runs. This catch-all step defends against potential exploits hidden in the file. Once the file is declared virus-free, a safe-for-work filter checks content category. For example, a museum image with historical weapons can be safe if used in the right context, but not for certain romantic-themed ads.
Avoiding redundant storage
A hashing approach prevents storing the exact same pixel data multiple times. If two different tours share the same image, the system references a single stored copy. This practice reduces storage costs. A lookup table maps each image hash to all tours referencing it.
Automated annotation and brand alignment
A recognition step applies external and internal models. External services (e.g., Google Vision API) detect faces, landmarks, and tags. Internal classification models confirm brand alignment. For instance, an internal model labels images consistent with the brand style. Results are stored as metadata.
Smart cropping
The system computes multiple crop coordinates based on image saliency, focusing on important regions such as main subjects or landmarks. When small thumbnails are generated, these coordinates help preserve the most visually relevant parts.
Similarity detection
Images that share a hash are exact copies, but there can be near-duplicates with slight cropping differences or rotations. A robust pipeline uses embedding-based similarity. The system resizes each image to a uniform size. Then a feature extractor (for example, an EfficientNet model) generates a lower-dimensional embedding that captures the image’s content.
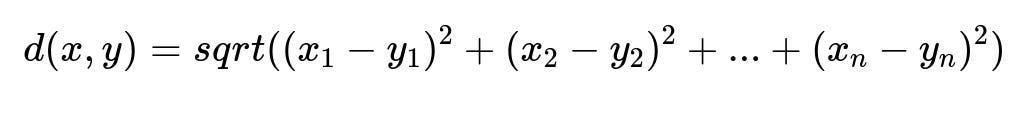
Here, x and y are two embeddings of length n. x_i and y_i are the i-th component of the embeddings. The distance d(x, y) indicates how similar two images are (lower distance means higher similarity).
These embeddings are indexed in a vector database like FAISS. Given a query image embedding, the system retrieves its nearest neighbors. If the distance is under a threshold, these images are flagged as highly similar. Campaign modules then skip redundant picks.
Example Python snippet for embeddings
import tensorflow as tf
import faiss
import numpy as np
from PIL import Image
# Assume we have an EfficientNet model
base_model = tf.keras.applications.efficientnet.EfficientNetB0(
include_top=False, pooling='avg'
)
def get_embedding(image_path):
img = Image.open(image_path).resize((224, 224))
img_array = tf.keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, axis=0)
preprocessed = tf.keras.applications.efficientnet.preprocess_input(img_array)
embedding = base_model(preprocessed)
return embedding.numpy().flatten()
# Build FAISS index
embedding_dim = 1280 # For EfficientNetB0 with include_top=False, pooling='avg'
index = faiss.IndexFlatL2(embedding_dim)
# Suppose we have a set of embeddings we add to the index
# embeddings_array is shape (num_images, 1280)
index.add(embeddings_array)
# Query for nearest neighbors
query_emb = get_embedding("test_image.jpg")
D, I = index.search(np.array([query_emb]), k=5)
# D gives distances, I gives indices of the nearest neighbors
In practice, more advanced indexing (e.g., IVF or HNSW structures) can handle large datasets faster.
Practical considerations
Storing computed embeddings is critical. Doing it on the fly is expensive. A database or a distributed file store holds these vectors. Periodic re-indexing is done if new images come in large batches.
Images flagged for marketing campaigns undergo one more filter to ensure variety. Near-duplicates with distances below a set threshold are pruned. This ensures final sets are diverse.
How would you handle model retraining and concept drift?
Changing traveler expectations or marketing guidelines may shift which types of images are considered brand-aligned or contextually safe. When the label distribution changes, new training data is collected. Metrics such as false-positive rate for brand-mismatch or safe-for-work filters are monitored. A consistent drop in performance triggers retraining. A versioned approach ensures reproducibility and rollback if a new model underperforms.
Retraining tasks use a pipeline with fresh samples added to the labeled dataset. A portion of older labeled images remains to preserve historical patterns. Validation sets measure performance. Rolling deployments allow canary testing before general release. If performance is stable, the new model fully replaces the old version.
What if certain images cause partial mismatches in brand alignment?
False positives arise if the model sees legitimate elements but interprets them as brand violations. The pipeline logs suspicious images for human review. Moderators can override model decisions and update ground truth. This feedback flows back into training sets. Over time, the model refines its internal representation to reduce mismatch. Specific interpretability tools like Grad-CAM can help visualize which regions triggered brand misalignment.
How would you measure success for the image optimization pipeline?
Metrics include percentage of invalid or off-brand images flagged correctly, success rates for near-duplicate detection, storage space saved by the hashing mechanism, and user engagement. For user engagement, click-through or conversion rates on marketing images can be tracked. If near-duplicate filtering is effective, diverse images increase campaign performance. For context checks, manual review time or error rates are monitored. Consistent improvements or stable low error rates indicate success.
How would you manage large-scale performance challenges?
A parallel ingestion service queues incoming uploads. Automated checks distribute across worker nodes, each handling malware scanning, hashing, and safe-for-work classification. Embedding extraction uses GPUs in a batch process. FAISS indexing is sharded if the dataset is too large for a single machine’s memory. Monitoring tools track memory and response times. If certain components lag, scaling either horizontally (adding more parallel nodes) or vertically (more powerful machines) is considered.
How do you deal with edge cases like historical weapons or controversial artwork?
Context-based classification is refined with domain-specific tags. Historical weapons may be acceptable in a museum-themed listing but not in a romantic dinner ad. The system references a context field describing the tour category. If the content is flagged, an override rule checks if the tour category aligns with the flagged content. If it does, the flag is lifted. Otherwise, the image is rejected for that context. This approach avoids blanket removal of images that are valuable when placed correctly.
How do you ensure final marketing selections maintain variety?
A diversity filter uses similarity embeddings to cluster images. Only one image per cluster is chosen, ensuring varied results. This can be done by iterating through the embedding list, picking the first image from each cluster and skipping near-duplicates. A small threshold decides cluster membership. This final pass ensures marketing doesn't end up with many near-identical selections.
How would you adapt your approach if real-time image moderation is needed?
Low-latency pipelines handle immediate checks. A microservice receives an image, performs a quick scan, and produces a yes/no response in milliseconds. Light models with accelerated inference engines handle on-demand moderation. If deeper analysis is needed (like offline near-duplicate checks), the pipeline tags the image for slower batch processes. This two-tier approach balances speed for immediate decisions with thorough checks that can happen asynchronously.
How do you verify the reliability of near-duplicate filtering?
A small set of known near-duplicates is curated for a test suite. Each pair has minimal differences. The pipeline is run against these pairs to confirm consistent detection. A separate holdout set with visually diverse images checks false positives. System logs and metrics help analyze retrieval results. If the pipeline marks truly distinct images as duplicates, the threshold or embedding approach is adjusted. This iteration continues until precision and recall meet the desired targets.
How would you maintain system resilience if external APIs fail?
External APIs provide initial tags or location-based annotations. If they fail or degrade, the internal model must still generate fallback embeddings for safe and brand classification. A circuit-breaker pattern in the microservice handles repeated failures. The system warns internal teams about repeated errors and routes images to a fallback queue for manual or delayed annotation. This ensures minimal disruption when external services are unavailable.