
ML Case-study Interview Question: Boosting Developer Productivity with Generative AI: Fine-Tuning, RAG & Commercial Tools


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform with tens of millions of lines of code wants to enhance developer productivity by using Generative AI. They have three approaches in mind: adopting a popular commercial AI coding tool, creating a customized Large Language Model by fine-tuning an open-source base model on their proprietary codebase, and building an internal knowledge base AI that can answer internal documentation queries. They have partial results from pilot testing each approach, but they need a cohesive plan to implement all three.
Describe your end-to-end solution strategy, including key technical considerations, ways to measure productivity, and how you will handle challenges in each of the three approaches.
Proposed Solution
Overview
The problem involves improving developer productivity at scale by leveraging three distinct AI-driven tracks. The organization wants to integrate a commercial coding tool, build a fine-tuned internal LLM, and create an internal knowledge base. The three tracks can operate independently, but they can also be combined to maximize efficiency. Each track has different implementation details, resource needs, and metrics to evaluate success.
Track 1: Commercial AI Coding Tool
Many teams start with a commercial coding assistant because it is straightforward to deploy. The tool can generate code suggestions, unit tests, boilerplate code, and translations from comments to code.
Short sentences explaining important points: Developers benefit from reduced repetitive coding. Commercial tools may not scale to handle massive codebases due to context length limits. You should design an A/B test with a control group to measure quantitative metrics (pull request times, code acceptance rates, code quality) and gather qualitative feedback via developer surveys.
Track 2: Customized LLM With Fine-Tuning
Fine-tuning an open-source base model on proprietary code can increase context awareness and produce domain-specific suggestions.
Short sentences explaining important points: Training on internal repositories helps the model understand unique frameworks and standard libraries. Massive code duplication can be reduced because the model knows other internal projects and services. Resource overhead can be large, requiring GPU clusters, specialized MLOps pipelines, and data engineers to maintain the training environment. You must continuously evaluate the fine-tuned model on real tasks to confirm improvements.
Track 3: Internal Knowledge Base AI
Engineers spend significant time searching for relevant references. An internal GPT-like system that indexes code and documentation can reduce that friction.
Short sentences explaining important points: A retrieval mechanism such as embedding vectors plus similarity search can pinpoint relevant documents or code snippets. Use a private instance of a large model to transform queries and relevant content into answers. A feedback loop using Reinforcement Learning from Human Feedback can gradually boost accuracy.
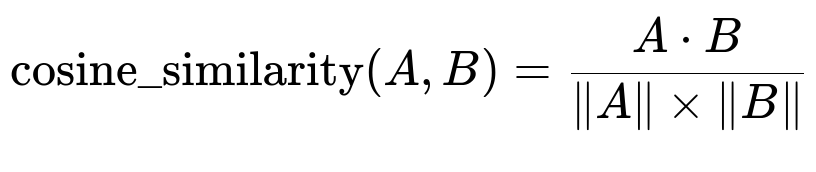
Here:
A and B are the embedding vectors for the query and the document.
A dot B is the dot product of vectors A and B in plain text form.
| A | is the magnitude of vector A in plain text form.
| B | is the magnitude of vector B in plain text form.
This formula is central to retrieval augmented approaches. It calculates how close two vectors are in multi-dimensional space, helping the system identify the most relevant documents.
Metrics and Evaluation
No single metric perfectly captures developer productivity. You might use pull request creation-to-merge time, code acceptance rates from the AI tool, code quality measures, and developer sentiment surveys.
Short sentences explaining important points: Track DORA and Flow metrics to capture throughput and stability. Assess code quality via static analysis. Use developer interviews or surveys to measure satisfaction with the AI solutions.
Implementation Example
# Example snippet of a retrieval-based system
import openai
import numpy as np
from vector_database import VectorDB
def get_document_embeddings(documents, model):
# This function encodes documents into vectors
return [model.encode(doc) for doc in documents]
def cosine_similarity(vecA, vecB):
dot_product = np.dot(vecA, vecB)
normA = np.linalg.norm(vecA)
normB = np.linalg.norm(vecB)
return dot_product / (normA * normB)
# Storing embeddings in a VectorDB
docs = ["Internal API docs...", "Service deployment instructions..."]
model = SomeEmbeddingModel()
embeddings = get_document_embeddings(docs, model)
db = VectorDB()
db.store(embeddings, docs)
# When a user query arrives:
query = "How to deploy my new microservice?"
query_vec = model.encode(query)
result = db.search_similar(query_vec, top_k=3)
# The AI model can now summarize or answer using the retrieved docs.
In this code:
We encode each document and store them along with their embeddings in a vector database.
We transform a user query into a vector.
We measure similarity (using plain text math in the cosine_similarity function) to retrieve relevant documents.
We feed those documents to a large language model for summarizing or answering queries.
Practical Tips
Keep each approach separate but ensure you can cross-validate performance. Always monitor the system and gather human feedback. Evaluate ongoing costs for GPU usage, maintenance of the LLM, and the effort required to keep your knowledge base updated.
Possible Follow-Up Questions
1) How do you mitigate hallucinations or inaccurate answers from the internal knowledge base AI?
Hallucinations occur when the model predicts answers that do not align with actual data. Solutions include: Use retrieval augmented generation to ground responses in real documents. The system provides a small set of relevant context from your vector database, reducing random speculation. Implement robust feedback loops. Encourage developers to flag incorrect answers. An RLHF mechanism can learn from these flags and reduce repeated mistakes. Set up a fallback policy. If the top retrieved results do not clearly answer the question, instruct the system to respond “I don’t know.”
2) How do you maintain data privacy and security when using a commercial AI coding tool?
Some commercial coding tools may send snippets of code to external servers. Ways to manage this: Enable private instances or enterprise versions of the tool. This can keep all data on your infrastructure. Redact or obfuscate sensitive tokens. Automated scanning tools can mask user secrets or API keys before sending code for suggestions. Set up strict usage policies. Developers should avoid exposing critical internal classes or proprietary algorithms to third-party systems unless a safe harbor or private environment is established.
3) How do you measure success for each track?
You must define clear, separate metrics for each approach: Commercial AI coding tool: Reduced code review cycles, improved code acceptance, stable or improved code quality metrics, positive developer survey feedback. Fine-tuned LLM: Efficiency in domain-specific tasks like upgrading frameworks, decreasing code duplication, fewer repetitive tasks, stable or improved code correctness. Internal knowledge base AI: Reduced meeting requests, fewer Slack or email queries about known procedures, shorter onboarding times for new hires.
4) How do you decide whether to keep using the commercial tool versus relying more on the custom LLM?
Both approaches can coexist. You can compare: Runtime performance when generating code. Large context windows might favor the custom LLM. Maintenance cost. If the custom LLM is expensive to train and update, the commercial tool might be cheaper to maintain. Coverage. The custom LLM has better coverage of internal code libraries, but a commercial tool may have broader knowledge of external libraries.
5) How would you handle continuous updates to the internal codebase and knowledge base?
Frequent code changes require regular retraining or indexing. You can: Set up daily or weekly pipelines that re-index code in the knowledge base. Periodically re-train or fine-tune the LLM on fresh data to avoid staleness. Maintain version control on embeddings. Keep track of changes so you can revert or debug issues that arise from newly introduced vectors.
Conclusion
These three tracks form a comprehensive approach to developer productivity. Combining them with systematic measurement and rigorous feedback loops will produce tangible gains. The commercial AI coding tool accelerates daily tasks, the fine-tuned LLM supports large-scale code management, and the internal knowledge base AI addresses high-level searches for documentation and best practices.