
ML Case-study Interview Question: Graph-Based Categories & Vision Embeddings for Automated Outfit Generation


Browse all the ML Case-Studies here.
Case-Study question
A major online retailer wants to automate outfit creation for its customers. They have a large dataset of outfits manually curated by fashion stylists. Their goal is to build a system that, given a single “seed” item (like a dress or a shirt), automatically recommends a complete outfit. They want a statistical model that first selects the list of item categories (for example, shoes, pants) that match well with the seed item and then chooses specific items in each category that visually complement each other. How would you design this end-to-end solution, and what approaches would you use to evaluate its quality?
Detailed Solution
A statistical graph-based model can generate an outfit template of categories starting from the seed item. The graph’s nodes are item categories (like “sneakers,” “cocktail dresses,” “handbags”). Weighted edges store pairwise probabilities of categories co-occurring in the same outfit, estimated from a historical dataset of stylist-curated outfits. Starting with the seed category, the model adds categories that have high-probability edges to previously selected categories until the desired number of total items is reached. This yields an outfit template such as “cocktail dresses, high heels, clutch handbags.”
A vision model then assigns specific items to each category. Two deep convolutional encoders convert each product image into an embedding vector. Cosine distance between two embeddings measures compatibility. The model is trained by ingesting pairs of items previously found together in real outfits. Large mini-batches are used so that the model can learn from many positive and negative pairings. Positive pairs are actual stylist-approved matches, while negative pairs are items not typically found together.
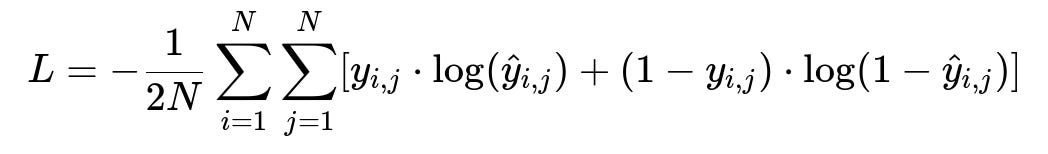
In this formula, N is the mini-batch size, y_{i,j} is 1 if item i and item j were historically paired in an outfit and 0 otherwise, and hat{y}_{i,j} is the predicted probability that items i and j should go together based on the cosine distance of their embeddings. The row- and column-wise cross-entropy losses are averaged to obtain the final loss value, which encourages the model to place matching items close in embedding space and incompatible items farther apart.
The system iterates over each slot in the outfit template and picks the most compatible items using approximate nearest neighbor search over the embedding space. That approach rapidly retrieves items that minimize cosine distance to previously chosen items. The final output is a multi-item outfit whose categories are coherent and whose chosen items are visually compatible.
Evaluation includes a Fill-In-The-Blank (FITB) test. The model removes one item from a real outfit and must identify the missing item among several visually similar distractors. Another evaluation method is a stylist Turing test, where expert stylists see a mix of human-created outfits and AI-generated outfits and try to guess their origin. If they have difficulty recognizing which outfits are AI-created, the system likely produces high-quality recommendations.
Implementation involves: Training a two-encoder computer vision model. Precomputing embeddings for the entire product catalog. Constructing a graph of category co-occurrence probabilities. Using the graph-based approach to build the template of categories from a seed item. Fetching items for each template slot by approximate nearest neighbor retrieval in the embedding space.
Deployment can employ a hybrid human-in-the-loop approach where generated outfits are reviewed or refined by stylists for special events or seasons. This final check ensures alignment with fashion trends, brand image, and domain nuances.
How to handle data sparsity in certain categories?
Ensuring robust embeddings for underrepresented product categories requires data augmentation or careful weighting of rare categories during training. Examples of potentially rare categories might be niche items like novelty hats. Adjusting sampling rates in mini-batches or using transfer learning from a larger, more general vision model can improve performance in these sparse zones.
How to personalize outfit recommendations?
Including user profiles or style preferences in the pipeline is possible by incorporating user-item interaction data. One approach is to rerank the final items based on past purchases or style tags. Another approach is to build user embeddings from prior activity and compute compatibility between user embedding and product embeddings.
What if we want fully unsupervised category discovery?
Removing the dependency on a predefined taxonomy calls for clustering methods in the embedding space. Instead of relying on labeled categories, the model can cluster similar products. The graph-based step becomes a similarity-based grouping of items that co-occur in outfits, potentially revealing emergent categories or styles not captured by the standard catalog.
Why two encoders, not one?
A single encoder often measures image similarity, not compatibility. A single encoder would place identical images very close in the embedding space, which is not desired here because identical items do not necessarily go together. Two encoders help distinguish “matching but not identical” items. Each encoder can push dissimilar but fashion-compatible images closer in space while keeping genuinely mismatched items distant.
How do you handle large batch training for the loss function?
Using mixed-precision training and GPUs with sufficient memory allows for batch sizes like 1024. If hardware constraints are severe, distributed training across multiple GPUs is an option. Large batches help the model see more positive and negative item combinations simultaneously, improving embedding quality.
How to ensure the recommended outfits are fresh over time?
Retraining on more recent stylist outfits can capture seasonal trends. Incremental training can quickly incorporate new product lines or ephemeral styles. A refresh cadence might be weekly during typical months and daily or near-real-time during peak seasons.
How to tune hyperparameters for the best performance?
Grid or Bayesian search can be applied on learning rate, batch size, and embedding dimensionality. Frequent offline evaluations with FITB and smaller Turing tests guide hyperparameter selection. Deploying A/B tests in production to compare add-to-bag rates or click-through rates provides real-world feedback.
How would you handle a scenario where stylist feedback conflicts with AI recommendations?
Introducing a feedback loop. Stylists can veto or refine machine-made outfits, creating additional training data that show the model which items or category combinations are unacceptable. This feedback is integrated into future retraining so that the system gradually aligns with stylist preferences.