
ML Case-study Interview Question: Boosting Media Engagement via an End-to-End Neural Recommendation Pipeline.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale media platform wants to boost user engagement by personalizing content recommendations. They have diverse data sources, including watch histories, search queries, device logs, and user demographics. They ask you, as a Senior Data Scientist, to design an end-to-end pipeline for training and serving a recommendation model that improves click-through rates, watch duration, and long-term user satisfaction. They also request a robust approach to monitoring the system in production and proactively handling data drift and model degradation. Outline your solution approach and detail how you would implement, evaluate, and iterate on your recommendation system.
Detailed Solution
A unified data pipeline is necessary to collect watch histories, user profiles, and context signals. These raw inputs need to be standardized through stable schemas. Cleaning and feature extraction follow. Each user gets a feature vector capturing past interactions, time-of-day preferences, device types, and content categories. Each item (movie or show) gets features like genre, average user ratings, and popularity.
For training, historical user-item interactions form positive or negative labels based on engagement thresholds. Negative sampling is needed to help the model learn from content not watched or skipped. Early versions of the model can be a matrix factorization approach or a two-tower neural network architecture. The system then outputs ranked items for each user.
Model Architecture
Matrix factorization or neural embeddings handle large-scale user-item data. One popular objective is cross-entropy loss that optimizes probability of a user engaging with a recommended item. A sample objective function for classification tasks is shown below.
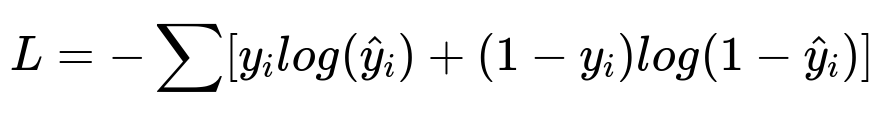
Here, L represents the loss function. y_i indicates the actual label (1 for clicked or watched, 0 for skipped). hat{y}_i indicates the predicted probability of a positive interaction.
Offline training uses a distributed framework. Data is sharded across machines. Systems like Apache Spark or TensorFlow Extended orchestrate parallel feature transformations. Training uses accelerated hardware for large-scale batch gradient updates. After training, validation compares ranking metrics such as Normalized Discounted Cumulative Gain, Mean Average Precision, and top-K precision across holdout sets.
Serving Pipeline
A real-time serving layer fetches the trained embeddings or model parameters. When a user arrives, the system retrieves user features, item features, and contextual signals, then generates a relevance score for each candidate. A top-ranked list is displayed. To reduce latency, approximate nearest neighbor techniques or in-memory retrieval speed up candidate selection, followed by more accurate reranking with the main model.
Monitoring and Iteration
Metrics like click-through rates, session duration, and user churn are tracked. If metrics degrade, or data shifts occur, the pipeline retrains the model on fresh data. Model versioning and canary deployments help test small user segments before a full-scale release. If a new model outperforms the old one in an A/B test, it is promoted to production.
Example Implementation Snippet (Python)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Flatten, Dot, Dense
# Sample user-item interaction DataFrame
data = pd.DataFrame({
'user_id': [1,1,2,2,3,3],
'item_id': [101,102,101,103,104,105],
'label': [1,0,1,0,1,1]
})
train, test = train_test_split(data, test_size=0.2, random_state=42)
num_users = data.user_id.max() + 1
num_items = data.item_id.max() + 1
latent_dim = 8
user_input = Input(shape=(1,))
item_input = Input(shape=(1,))
user_embed = Embedding(num_users, latent_dim)(user_input)
item_embed = Embedding(num_items, latent_dim)(item_input)
user_vec = Flatten()(user_embed)
item_vec = Flatten()(item_embed)
dot_prod = Dot(axes=1)([user_vec, item_vec])
output = Dense(1, activation='sigmoid')(dot_prod)
model = Model([user_input, item_input], output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit([train.user_id, train.item_id], train.label, epochs=5, verbose=0)
This code trains a simple matrix factorization model with an extra dense layer. Real systems would use more features, negative sampling, and advanced architectures.
Final Thoughts
Continual updates and robust monitoring keep the model relevant as user tastes evolve. A/B tests confirm gains in engagement metrics. New features, side-information, and advanced architectures (like multi-head attention) can be introduced in future iterations to maintain or improve performance.
How would you ensure scalability for millions of users and items?
Distributed data storage is essential. Partition the data by user or time range to avoid slow queries. Feature extraction systems run on Apache Spark or similar frameworks to handle large volumes in parallel. Model training can use GPUs or TPUs to reduce epochs. A specialized retrieval index or approximate nearest neighbor system like Faiss ensures quick lookups during serving. A hierarchical approach where a coarse model filters candidate items and a refined re-ranker applies a more complex model keeps response times low.
What steps do you take for robust A/B testing in production?
A random subset of users sees the new model while another subset uses the existing model. Key metrics such as click-through rate, completion rate, or watch duration are compared. Confidence intervals confirm if improvements are statistically significant. Data is collected for a set period to capture different usage patterns. If results remain positive, the new model is gradually rolled out to more users until full deployment.
How do you handle data drift and model retraining?
A continuous feedback loop tracks changes in feature distributions, engagement behavior, or content patterns. Automated alerts trigger partial or full retraining when statistical thresholds are exceeded. Periodic offline evaluations on fresh data measure feature shift and performance differences. If performance drops, the pipeline rebuilds new training sets, updates the feature space, and retrains. Version control tags each retrained model, and rollback options remain available in case of unexpected degradations.
How do you ensure reliable real-time predictions with minimal latency?
A high-throughput serving infrastructure is set up. Precomputed embeddings sit in memory for fast lookups. Low-latency databases like Redis store user states. A streaming queue like Kafka collects real-time events for quick updates of user features. Caching results for frequently accessed users or items reduces redundant computation. Latency profiling ensures that the model and the surrounding microservices each stay within tight time budgets.
Which metrics do you use to evaluate success beyond click-through rates?
Longer-term outcomes show true success, including time spent, repeat visits, churn reduction, or subscription conversions. Weighted metrics account for content quality or user satisfaction. Watching a short clip might not always indicate real engagement if the user immediately exits. A balanced view of short- and long-term impacts helps refine model optimization. A diverse set of success metrics ensures the system does not over-optimize for clicks at the expense of user retention.