
ML Case-study Interview Question: Scalable Hybrid Recommendation Systems for Real-Time Engagement and Personalization


Browse all the ML Case-Studies here.
Case-Study question
You are leading a data science initiative at a large-scale online platform. The user base is massive, and the platform offers personalized recommendations for content discovery. Product managers want to increase engagement by serving more relevant recommendations. You have historical user interaction data, content metadata, and user profile features. You also have a new user cold-start challenge. Formulate an end-to-end plan to build, deploy, and maintain a recommendation solution that maximizes click-through rates and session length. How will you address data quality issues, model selection, personalization strategies, and real-time inference needs?
Detailed Solution
Data Collection and Preparation
Gather historical user interactions, content metadata, and user demographics. Filter out inconsistent entries. Convert textual metadata into numerical embeddings using a pretrained transformer model. Create time-based splits to reflect user behavior changes over time.
Feature Engineering
Generate user-level statistics (session frequency, dwell time). Produce content-level features (popularity scores, taxonomy categories). Normalize numerical fields. Encode categorical variables with target encoding. Handle missing demographic data. Apply imputation strategies.
Model Architecture Choices
Train a hybrid system. Use a content-based model to address the cold-start scenario. Combine with a collaborative filtering approach on users who have sufficient interaction history. Experiment with matrix factorization or neural-based embeddings for collaborative filtering.
Model Training Details
Use multiple model candidates (Gradient Boosting, Neural Networks). Split data into train, validation, and test sets in chronological order. Track performance on out-of-sample data. Evaluate top-k recommendation accuracy and user session length improvements.
Core Loss Function Example
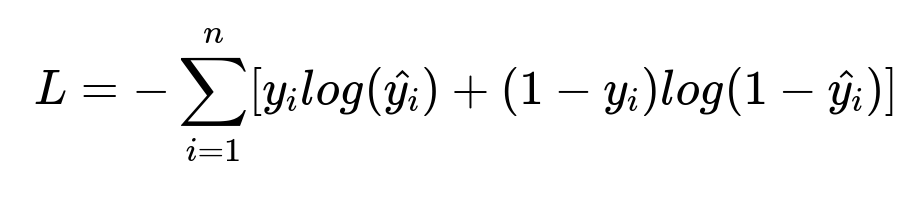
L is the negative log-likelihood loss function. y_i is the actual label (1 if user clicked, 0 otherwise). hat{y_i} is the predicted probability of a click. n is the total number of training samples.
Explanation of Loss Function
This binary cross-entropy calculates the divergence between predicted probabilities and true labels. Minimizing L leads to improved click probability estimates.
Model Evaluation and A/B Testing
Perform offline evaluation with standard metrics such as AUC and recall. Deploy champion model behind a controlled feature flag. Serve recommendations to a small user subset. Compare user engagement to baseline. Once stable gains are confirmed, roll out the new system to all users.
Deployment
Serve models behind a scalable endpoint. Store user embeddings in a fast key-value store. Generate real-time recommendations by retrieving similar content or user-based neighbors. Use a parallel microservice architecture to handle surges in traffic.
Maintenance and Monitoring
Monitor drift by tracking changes in user content preferences. Retrain models on new data. Log system metrics (latency, throughput, reliability). Incorporate feedback loops to refine recommendations based on continuous user interaction data.
Example Code Snippet
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
data = pd.read_csv("interaction_data.csv")
X = data.drop("clicked", axis=1)
y = data["clicked"]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2)
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=6)
model.fit(X_train, y_train)
preds = model.predict_proba(X_test)[:, 1]
The code reads data, splits it, and trains a model. Probability outputs can serve as recommendation relevance scores. Pair these with a candidate generation step (matrix factorization or nearest neighbor retrieval) to form a two-stage pipeline.
How do you handle model scalability for millions of users in real time?
Partition data across distributed storage. Cache frequently requested recommendations. Use approximate nearest neighbor libraries to speed up similarity searches. Parallelize or batch processing steps to manage throughput.
How would you reduce cold-start issues for new users and new content?
Start by serving content-based recommendations relying on metadata features. Gradually incorporate user interaction signals for new users. Embed new content by leveraging textual or categorical attributes. Update embeddings periodically.
How do you monitor and debug performance issues in production?
Track inference latency, hardware resource utilization, and response throughput. Compare real-time feedback with offline metrics to detect anomalies. Collect logs from each service endpoint. Investigate errors and retrain if performance declines.
How do you handle data quality problems in incoming real-time streams?
Apply validation checks on raw inputs before feeding them to models. Impute or discard corrupted entries. Maintain robust ETL pipelines with error handling. Reconcile anomalies with user or content IDs. Store relevant statistics to identify suspicious spikes or dips in data flow.
How would you address potential bias in personalized recommendations?
Measure fairness metrics across demographic segments. Implement re-ranking to ensure diverse content exposure if analysis reveals systematic bias. Train or finetune models to penalize or limit certain types of skewed results. Validate fairness during both offline and online evaluations.
How do you perform hyperparameter tuning at scale?
Adopt distributed hyperparameter search or Bayesian optimization frameworks. Conduct iterative experiments on small subsets of data or with fewer training epochs. Track results in a centralized experiment repository. Preserve top-performing models for final evaluation.