
ML Case-study Interview Question: Two-Tower Embeddings for Concept-Based Hotel Recommendations Using User Reviews


Browse all the ML Case-Studies here.
Case-Study question
A major online travel platform wants to build a lodging recommendation engine capable of retrieving accommodations based on user-specified travel concepts (for example, “family-friendly beaches,” “luxury with lake view,” or “wedding hotels”). They have abundant user reviews and an in-house tagging system that identifies concepts and sentiment (positive, neutral, negative). They aim to embed both hotels and concepts into a shared similarity space for rapid retrieval. Design a solution that learns these embeddings from user reviews, explain your approach for training and inference, discuss data needs and preprocessing steps, and outline how you would deploy the system at scale. How would you handle negative cases (irrelevant hotels) during training, and what techniques would you use to evaluate the model?
In-Depth Solution
Data
They gathered one year of booking data with corresponding user reviews. Each review is parsed with a proprietary tagging system to identify key concepts (for example, “spa,” “child-friendly,” “breakfast”), each linked to a sentiment label. This creates training samples mapping hotels to concept-sentiment pairs.
They store this data as tuples: (hotel_id, concept, sentiment_score). sentiment_score can be positive, neutral, or negative. The plan is to transform these tuples into examples for a two-tower model.
Approach
They adopt a two-tower neural network. One tower encodes the hotel into an embedding vector. The other tower encodes the concept into another embedding vector. The final similarity is calculated with a scoring function such as dot product or cosine similarity.
They select pairs (h, c_pos) where c_pos is a concept actually mentioned with a positive or neutral sentiment in a review of hotel h. They also form (h, c_neg) pairs where c_neg is a concept not associated with h or associated with negative sentiment. Both towers get trained so that f(h, c_pos) > f(h, c_neg).
They use a ranking loss:
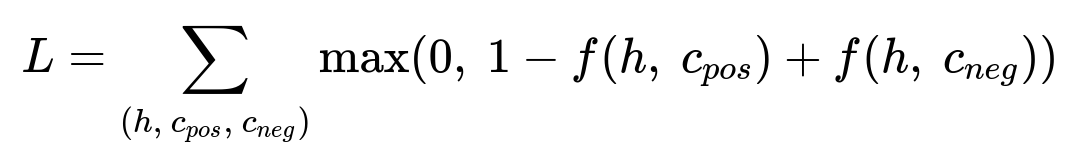
In the above, h stands for the hotel embedding, c_{pos} and c_{neg} stand for positive and negative concept embeddings, and f is the scoring function. The goal is to push the model to assign higher similarity to (h, c_{pos}) than to (h, c_{neg}).
They train this with mini-batch gradient descent. They might warm-start hotel embeddings using a separate model that was pre-trained on click sessions.
Inference
The inference step stores precomputed hotel embeddings in a data store. The concept tower can be queried on-the-fly whenever a user enters a keyword or phrase. Then the system calculates the concept embedding, uses an approximate nearest-neighbor index with the hotel embeddings, and returns a sorted list of hotels ranked by similarity score.
Deployment
They use a scalable key-value store to cache hotel vectors. They keep the concept tower in a service that transforms a given phrase or concept into its embedding. They use an approximate similarity search library to handle high-scale queries quickly.
They handle updates periodically by retraining embeddings or incremental fine-tuning, then refreshing the index. They test changes on a small fraction of traffic before a full rollout.
Example Code
import torch
import torch.nn as nn
class TwoTowerModel(nn.Module):
def __init__(self, hotel_vocab_size, concept_vocab_size, embed_dim):
super().__init__()
self.hotel_embed = nn.Embedding(hotel_vocab_size, embed_dim)
self.concept_embed = nn.Embedding(concept_vocab_size, embed_dim)
def forward(self, hotel_ids, concept_ids):
h_vecs = self.hotel_embed(hotel_ids)
c_vecs = self.concept_embed(concept_ids)
return h_vecs, c_vecs
def score(self, h_vecs, c_vecs):
# Dot product or cosine similarity
# For simplicity, use dot product
return (h_vecs * c_vecs).sum(dim=1)
They feed positive pairs and negative pairs into a triplet loss. They rely on standard negative sampling approaches for c_neg.
What is your negative sampling strategy to ensure hard negatives for training?
One approach is to pick concepts with high co-occurrence in similar hotels. If two hotels share many characteristics but differ in the presence of a concept, that concept becomes a hard negative for the other hotel. They also pick random concepts not found in the review data for the hotel as standard negatives. They maintain a dictionary mapping each hotel to its top competing hotels (for example, based on user click patterns), and they look up concepts from these competing hotels to create challenging negative examples.
How do you address the cold-start problem for newly added hotels?
They sometimes initialize new hotel embeddings using metadata, such as location or star rating. If no user reviews exist, they rely on surrogate signals like brand or chain. When sufficient new reviews arrive, they finetune embeddings. They also consider hybrid methods that mix content-based encodings (for instance, hotel amenities, region embeddings) to reduce reliance on direct user feedback.
Why prefer a two-tower approach over a single-tower cross-encoder?
A single-tower cross-encoder concatenates hotel and concept descriptions and processes them with a larger network. That can improve accuracy but is slower at inference. The two-tower model enables fast retrieval because they can store precomputed embeddings and compute similarity quickly. This suits large-scale scenarios where near-instant response is needed.
How do you measure success and evaluate your model?
They measure retrieval precision or recall at top ranks. For example, for a concept “beach hotels,” they check how many of the top recommendations are truly beach hotels with positive user feedback. They also collect user engagement metrics like click-through rate or user satisfaction from A/B experiments. They track coverage to ensure less popular hotels are still discoverable.
How would you handle out-of-vocabulary or unseen concepts?
They use subword tokenization or phrase-level embeddings for the concept tower. If a new concept phrase arrives, the model can break it into smaller known pieces. This helps the tower produce a meaningful embedding. They also maintain an ongoing pipeline to expand the concept vocabulary as new trending terms arise.
How do you manage bias or potential errors in user reviews?
They moderate sentiment extraction. They also watch for potential skew if certain segments of hotels receive systematically negative feedback for non-quality reasons. They track the distribution of sentiment across categories. They provide manual override or additional data signals to reduce unfair penalization. They might limit extremely negative user reviews if they are recognized as spam or fraudulent.
Would you incorporate image data or other auxiliary features?
They can incorporate images, hotel amenity metadata, or location-based signals for a better hotel tower embedding. They sometimes fuse pre-trained text and vision models to get richer representations. They also add skip-gram features derived from user click sessions to refine embeddings.
How do you handle multi-language reviews?
They either train a multi-lingual concept extractor or build separate pipelines for major languages. They unify hotel embeddings but allow concept embeddings to be language-specific. They can store a language-agnostic vector by merging across translations or rely on a large language model to standardize concepts from multiple languages.
What steps ensure this system scales for millions of hotels?
They use approximate nearest-neighbor indexes that scale sub-linearly with the embedding size. They batch or precompute concept embedding queries for popular requests. They keep consistent versions of hotel embeddings so that each index refresh is atomic. They use distributed GPU or CPU clusters for training and retraining, ensuring the embeddings remain up to date. They carefully design a pipeline that monitors data drift, automates retraining, and quickly redeploys new embeddings.