
ML Case-study Interview Question: Unified 100-Language Speech & Text Translation with a Single Self-Supervised Transformer Model.


Browse all the ML Case-Studies here.
Case-Study question
A large tech firm wants to build a single unified speech and text translation model that can handle speech-to-speech, speech-to-text, text-to-speech, and text-to-text translations for up to 100 languages. They have access to 1 million hours of open speech audio data, from which they create self-supervised speech representations and an automatically aligned speech-text corpus. They then combine these data sources, filtering and augmenting them with labeled and pseudo-labeled examples. They aim for state-of-the-art translation quality, reduced latency compared to multi-stage cascaded systems, robustness to background noise and different speakers, and minimized toxicity or bias in the model outputs. They also want a scalable evaluation workflow and a plan to release their model, code, and metadata as open source. As a Senior Data Scientist, propose a complete solution covering data collection, architecture design, training strategy, evaluation metrics, robustness checks, and bias/toxicity mitigation. Specify how you would ensure high-quality translations and safe outputs under production constraints.
Detailed Solution
Data Collection and Alignment
This problem requires harvesting 1 million hours of open speech audio. Self-supervised learning methods transform the raw audio into general feature representations. Filtered and pseudo-labeled speech-text pairs then join human-labeled samples in the final training corpus. Large-scale alignment methods pair segments of speech with the corresponding text translations in multiple languages, creating a single multilingual speech-text dataset. Automatic alignment ensures broad coverage but demands strict filtering thresholds to maintain data quality.
Model Architecture
A single encoder-decoder structure handles both speech and text inputs. Speech inputs use a self-supervised front end that produces contextual embeddings from raw waveforms. Text inputs route through an embedding layer that shares the same decoder space. A unified decoder layer generates targets (either speech tokens or text tokens) based on a learned tokenization scheme for both speech and text. The model incorporates multi-head attention and feed-forward layers with dimension configurations that support 100 languages.
Training Approach
Masked prediction tasks on speech representations initialize the parameters via self-supervised learning. The main translation task then optimizes cross-entropy to align source signals (speech or text) with target sequences (speech or text). Curriculum learning can start with monolingual automatic speech recognition or text-to-text tasks, then progress to mixed speech-text translation tasks. Large-scale distributed training leverages gradient accumulation and careful learning rate scheduling. Early stopping and checkpoint averaging safeguard against overfitting.
Evaluation
Researchers measure translation quality using BLEU for text outputs and an adapted version of BLEU for speech outputs. They also compare single-step direct speech-to-text or speech-to-speech translation against cascaded two-step baselines. Robustness tests inject background noise or alter speaker identities to assess model resilience. Toxicity checks and gender bias tests verify safe, fair, and non-harmful translations.
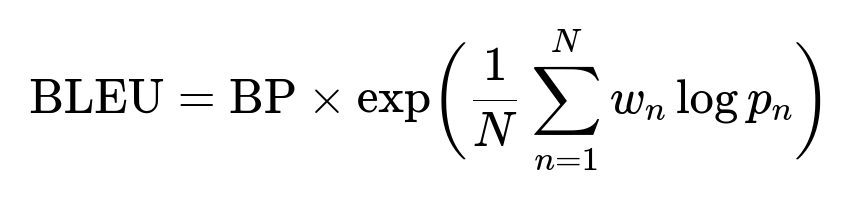
In this formula, BP is the brevity penalty, N is the maximum n-gram size (often 4), w_n is the weight assigned to each n-gram precision term, and p_n is the measured n-gram precision.
Robustness to Noise and Speaker Variation
Multilingual and multi-speaker data introduce diversity in accent and style. The training dataset includes varied acoustic conditions. Data augmentation with background noise and speed perturbations further increases robustness. Speaker embedding techniques help the model generalize to new voices.
Mitigating Bias and Toxicity
Filtering of training examples removes inappropriate content. Additional fine-tuning on curated datasets pushes the model toward safe outputs. A toxicity classifier can be placed on top of the translations for real-time rejection or post-processing. Frequent checks of gender pronouns and identity terms detect problematic translations that require intervention.
Open Source Release
Publishing the final model involves a well-documented repository containing inference scripts, finetuning instructions, and metadata to recreate the aligned data. This fosters community adoption and external validation.
Practical Python Example
import torch
from fairseq.models.transformer import TransformerModel
# Load a multilingual model
model = TransformerModel.from_pretrained(
model_name_or_path="unified_speech_text_model",
checkpoint_file="model.pt",
data_name_or_path="data-bin"
).cuda()
# Inference with speech or text input
def translate_input(input_signal, is_speech=True):
if is_speech:
# Convert waveform to embeddings and decode
features = extract_audio_features(input_signal)
return model.translate(features)
else:
# Directly translate text
return model.translate(input_signal)
# Example usage
translation_output = translate_input("Hello world", is_speech=False)
print(translation_output)
This snippet loads a pre-trained transformer-based model. Speech inputs would first pass through a function that extracts low-level acoustic features, and text inputs feed directly into the model. The final translation or speech output is generated by the single unified decoder.
How would you handle large-scale distributed training efficiently?
Mixed precision training reduces memory usage. Gradient checkpointing limits stored activations. Pipeline and tensor model parallelism spread the workload across many GPUs. Adaptive learning rate schedulers and an effective batch size ensure stable convergence.
How do you measure translation errors beyond BLEU?
Human evaluations gauge fluency and fidelity. Edit distance-based metrics help identify specific error patterns. Internal metrics for speech translation also measure word error rate against known transcriptions. Confidence scores from specialized quality estimation models detect uncertain segments.
What is your strategy for fine-tuning on low-resource languages?
Use multilingual transfer. Freeze earlier layers that capture generic audio features, then finetune later layers on limited language-specific data. Leverage synthetic text or pseudo-labeled speech segments from related languages to boost representation quality.
How do you ensure the model remains safe when translating harmful or offensive content?
Training data filtration removes blatant examples. Reactive detection checks the output before serving it. Manual reviews handle flagged edge cases. Ongoing monitoring logs suspicious translations to refine the toxicity classifier or the data filtering pipeline in future releases.