
ML Case-study Interview Question: Using Machine Learning to Drive Timely Browser Updates and Enhance Security


Case-Study question
A large user-facing online platform noticed many customers using outdated browsers. This caused security risks, poor user experience, and reduced feature compatibility. As the Senior Data Scientist, design an end-to-end machine learning solution to identify, segment, and encourage at-risk users to update their browsers. Propose your data collection plan, outline your modeling approach, and detail how you would measure and iterate on the system.
Detailed Solution
Data Collection and Preparation
Gather user interaction logs from web server records or front-end tracking. Extract browser version, operating system, session duration, error logs, and relevant engagement signals. Store them in a central data warehouse. Clean, parse, and label data with the user’s current browser version to identify outdated or at-risk browsers.
Feature Engineering
Transform user agent strings into numerical or categorical signals. Create features reflecting session engagement such as average watch time, page load times, or bounce rates. Build features capturing time since last browser update, frequency of security warnings, and login success rates.
Modeling Strategy
Predict the likelihood that a user will update their browser if prompted. Use classification models, such as logistic regression or gradient boosting. Train the model on historical data where users were prompted to update, and measure the outcome (did they update or not?).
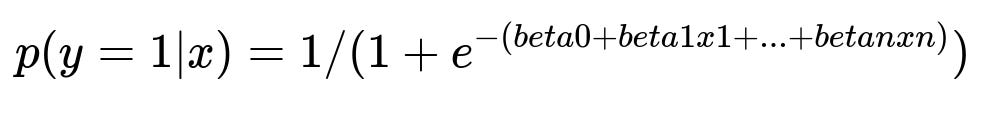
Where:
p(y=1|x) is the probability that a user will update.
x1, x2,...,xn are the input features (e.g. browser version, engagement metrics).
beta0, beta1,...,betan are model parameters learned from data.
Optimize beta coefficients to minimize log-loss on the training set. Validate the model on a hold-out set to ensure generalization.
System Deployment
Implement real-time model inference in production. Track each user’s browser string. If flagged, present an update prompt. Log the result to feed back into training data. Run A/B tests with different prompts or update workflows. Use metrics like browser-update rate, conversion time, and session durations to evaluate performance.
Monitoring and Iteration
Monitor precision and recall for predicting which users are likely to update. Confirm the model is not generating excessive prompts for users who never update. Periodically refresh training data to capture evolving user behavior and new browser versions. Retrain the model with the latest logs to adapt to usage shifts.
Practical Example
Use Python for data ingestion. Collect logs in a data table that includes user_id, session_id, browser_version, OS, prompt_shown (True/False), and update_completed (True/False). Train a logistic regression model with scikit-learn:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
data = pd.read_csv("browser_logs.csv")
X = data[["browser_version_code","session_length","bounce_rate"]]
y = data["update_completed"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
print("Training Accuracy:", model.score(X_train, y_train))
print("Test Accuracy:", model.score(X_test, y_test))
Train, tune hyperparameters (like regularization) via cross-validation, then deploy. Track performance metrics in real-time, and update the model on a schedule or on data-drift triggers.
Follow-Up Question 1: How would you handle data imbalance if only a small fraction of users update successfully?
Use class weighting or oversampling. Check confusion matrix to ensure the model does not ignore the minority class. Modify the loss function to penalize misclassifications of that class more heavily. Possibly use SMOTE or other oversampling methods. Evaluate success via recall or F1 score for the minority class.
Follow-Up Question 2: How would you measure the effectiveness of prompts and confirm real improvement?
Set up an A/B test. Segment a control group with no prompt and a treatment group with the prompt triggered by the model. Measure update rates, session performance, user retention, and post-update engagement. Compare metrics to confirm any lift is statistically significant.
Follow-Up Question 3: How would you handle evolving browser versions and rapidly changing user behavior?
Schedule retraining with fresh data. Monitor data drift using distribution checks on browser_version_code or new session patterns. Retrain if metrics degrade. Integrate a pipeline that automatically checks performance thresholds and triggers a new model build if performance drops.
Follow-Up Question 4: Why might a more complex model like gradient boosting or neural networks help?
Complex models can capture non-linear relationships like combinations of session length and browser version. They might yield better predictive performance if user behavior patterns are complex. Validate gains in cross-validation and production tests to confirm if the added complexity pays off.
Follow-Up Question 5: How would you address user privacy and compliance concerns?
Anonymize data and remove personal identifiers. Apply data protection policies to comply with regulations like GDPR where relevant. Log only essential information needed for the update model. Obtain user consent for the data collection process. Store user-level data in secure servers with role-based access and encryption.
Follow-Up Question 6: How would you ensure the prompts do not harm user experience?
Monitor user engagement metrics, prompt dismissal rates, and site exit rates. Keep the prompt unobtrusive. Test different prompt designs and measure bounce rates. Defer or skip prompts for users who consistently ignore them. Stop or reduce prompt frequency if negative engagement spikes.
Follow-Up Question 7: What techniques would you use to ensure real-time predictions scale with high traffic?
Use a low-latency model inference server or vectorized inference pipeline. Consider a model compression technique if the model is large. Deploy the model on a robust infrastructure (e.g. container orchestration, load balancing) to handle traffic peaks. Cache or store results for returning users.
Follow-Up Question 8: How would you handle conflicting goals of security vs. user annoyance?
Weigh security risk from outdated browsers against user friction from repeated prompts. Collaborate with product stakeholders to define a threshold for risk acceptance. Adjust the model’s cutoff probability to balance recall (catch more at-risk users) and precision (avoid excessive alerts). Track feedback from support tickets and user surveys to find an acceptable prompt frequency.
Follow-Up Question 9: What if user agent strings are spoofed?
Add extra data sources, such as server-side feature checks or JavaScript detection, to confirm real browser capabilities. Compare declared user agent version with known feature support. Build anomaly detection rules that flag improbable version combinations. Update the model accordingly once suspicious patterns are confirmed.
Follow-Up Question 10: How would you present results and get buy-in from leadership?
Show improvement in security posture, reduced support tickets, and faster site performance. Provide a clear chart of update rates over time with the model vs. a baseline. Outline potential growth in user retention and cost savings by preventing security breaches. Summarize test metrics and highlight return on investment for future expansions.