
ML Case-study Interview Question: Building a Real-Time Notification System with Multi-Task ML and PID Control


Browse all the ML Case-Studies here.
Case-Study question
A large-scale consumer platform wants to replace its old daily notification scheduling system with a near real-time notification engine. They have multiple notification types (email, push, in-app), each with varied objectives. They want to generate candidate events for all users, rank those events, decide which notifications to send, choose the best channel, and fine-tune volume with automated controls. They also want a robust machine learning model to predict engagement and churn risk. How would you design this system, collect and handle data, build and serve the model, enforce policies, and align send volumes through feedback?
Provide all reasoning and discuss infrastructure, model architecture, policy decisions, and final experiment results. Outline a plan for dealing with engagement, unsubscribes, dynamic user segments, diverse content types, real-time data pipelines, and model serving at scale.
In-depth Solution Explanation
The Company previously used a daily budget notification system that relied on daily predictions for budget allocations. That approach lacked flexibility to handle near real-time engagement patterns or dynamic content changes. The new approach processes incoming notification events in a streaming fashion, allowing for timely and personalized notifications.
System Architecture
Events enter a streaming pipeline, where a job filters and potentially ranks them. If simple logic applies, the notification is sent immediately. If more complex logic applies, events go into an event store. A ranking job periodically triggers, scores all stored events for a user, and passes results into a policy layer that decides channel and send time.
Candidate Generation
They pre-generate candidate events for each user once per day to minimize infrastructure costs. Those candidates are stored in a key-value store. A ranking job runs multiple times a day at user-specific time slots to leverage the user’s historical engagement patterns. It reads candidates from storage, computes model scores, and decides if a notification should be sent.
Multi-Task Notification Model
They use a single multi-head model to predict various outcomes:
Probability of push opens.
Probability of email clicks.
Probability of unsubscribes.
They gather training data by logging events in production. They also maintain random and forced-send logging strategies to capture unbiased feedback. This multi-task model uses:
Content signals: notification type, historical engagement with that content.
User signals: user activeness, preferences, prior notification interactions.
User sequences: past engagements, notification sends, and time-based engagement patterns.
Transformer blocks: to capture temporal patterns in user sequences and content interactions.
Policy Layer
The policy layer uses model output to compute a linear utility score per event. If the utility is above a threshold, a notification is sent; otherwise, it is discarded. They manage separate thresholds for email and push channels. These thresholds adapt based on user segments, such as highly active users versus new users.
Automated Volume Control
They employ a Proportional-Integral-Derivative (PID) controller to auto-tune thresholds. This ensures the system meets target daily volume without excessive manual experimentation.
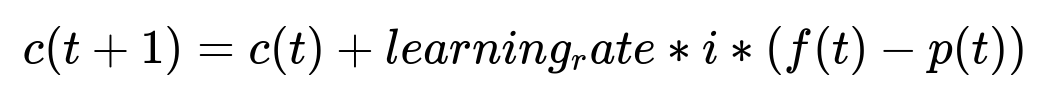
Here:
c(t) is the threshold at time t.
f(t) is the desired notification volume (target).
p(t) is the actual volume observed.
i is the proportional factor.
learning_rate controls how fast the threshold changes to align volume.
The PID logic observes volume mismatches, adjusts the threshold accordingly, and keeps notifications in a safe, balanced range.
Model Serving
They serve the model on GPUs for higher throughput. They cache user features at send time, then retrieve the same cached features when the user engages, ensuring consistency in logging. The framework runs asynchronously, fetching features and scoring events on the fly. They plan to optimize GPU usage further with techniques like low-precision inference.
Experiment Outcomes
They tested numerous variations. The final launch yielded:
Significant lifts in user engagement (email clicks and push opens).
Notable gains in weekly active users (WAU).
A moderate increase in unsubscribes due to higher notification volume, especially among new users.
Follow-up Question 1: How would you handle users who become more or less active over time, especially in the context of ranking and volume control?
Users’ engagement levels shift, altering the effectiveness of thresholds or channel preference. The best approach is to re-segment users periodically based on their new behavioral patterns. The policy layer maintains unique threshold values per user segment (e.g. active, medium-active, new users). Whenever a user’s activity crosses a boundary, reassign them to a more suitable segment. The PID controller readjusts the volume accordingly by learning from new volume mismatches in these segments. The ranker also needs features that reflect time-decayed user engagement so that older activity is weighted less.
Follow-up Question 2: How can you ensure content variety and prevent repetitive notifications when relying on a purely utility-based policy?
The model might repeatedly send the same top-scoring content. One method is to incorporate a diversity or novelty penalty for frequently repeated content. Another is to track content-level features (recently shown, user’s interactions) and reduce the score if the same content was shown recently. The system can add a penalty term to the utility score whenever an item has been sent multiple times. Rotational strategies can also reduce user fatigue by promoting fresh or less-seen content.
Follow-up Question 3: What strategies would you use to measure the true impact of your notifications versus organic user sessions?
They maintain a random holdout group with suppressed sends (or forced sends). By comparing engagement, session rates, and user retention in the holdout group versus the normal group, they estimate causal effects. For example, they randomly choose a small subset (e.g. 0.25%) of users where the system withholds notifications for a day to measure changes in session or retention metrics. They also create a forced-send group to see if sends are beneficial or if the model predictions are missing possible gains. These groups yield unbiased ground truth data and help calibrate the model.
Follow-up Question 4: How would you mitigate higher unsubscribe rates if the system decides to send more notifications?
They can integrate a churn risk prediction into the utility function. If unsub probability for a user-event pair is too high, the system raises the threshold. They also refine the policy layer so that it discounts events with a high chance of user annoyance. A safe approach is to combine an engagement score with an “unsub cost,” balancing user lifetime value with the risk of losing the user entirely. They can place stricter thresholds for new or inactive users, who might have lower tolerance for frequent notifications. The PID controller can also incorporate the unsubscribe rate as an additional feedback metric, adjusting thresholds to keep unsub rates within acceptable limits.