
ML Case-study Interview Question: Unified Multi-Task Learning for Diverse Streaming Platform Recommendation Use-Cases.


Browse all the ML Case-Studies here.
Case-Study question
A large streaming platform wants to reduce the complexity of their recommendation engine by consolidating multiple item-ranking models into a single unified multi-task model. They have multiple use-cases: notifications (user-to-item), related items (item-to-item), search (query-to-item), and category exploration (category-to-item). Each use-case must preserve its unique features and latency constraints. How would you design and implement one consolidated machine learning system that produces recommendations for all these use-cases, with minimal maintenance overhead and improved model performance?
Detailed Solution
Unifying the Offline Pipeline
Use a single request context schema that combines necessary elements for each use-case. Introduce a categorical variable task_type that indicates which recommendation task is being addressed. Missing fields for a particular use-case are replaced with default placeholders. Generate labels for each use-case using the unified request context, then merge them into one training dataset.
Train a single multi-task model that learns to recommend items for different use-cases. Incorporate features relevant for each use-case within one data pipeline so new features or enhancements benefit every task.
Central Multi-Task Loss Function
A common approach is to optimize a sum of task-specific losses. One typical formulation is:
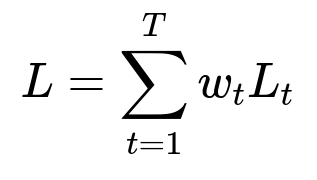
T is the total number of tasks. w_t is the weight for task t, controlling its importance. L_t is the loss for task t. Each use-case has its own ground-truth labels and evaluation metrics but shares the underlying representation learned by the model.
Explaining the Loss Function Terms
L_t: Depends on the objective, for example cross-entropy or mean squared error. w_t: Tune these hyperparameters to avoid any single task dominating the optimization. T: Adjust as you add or remove tasks in the consolidated model.
Serving the Model Online
Deploy the single model in multiple environments to fulfill distinct latency and scalability needs for each use-case. Keep a common inference API that accepts different context inputs (user, query, item). Expose configuration knobs to manage caching, data freshness, request timeout, fallback logic, and candidate retrieval rules. Allow each use-case to fine-tune these parameters independently.
Code Snippet (Simplified)
import torch
import torch.nn as nn
import torch.optim as optim
class MultiTaskModel(nn.Module):
def __init__(self, input_dim, hidden_dim, num_tasks):
super(MultiTaskModel, self).__init__()
self.shared_layer = nn.Linear(input_dim, hidden_dim)
self.task_heads = nn.ModuleList([nn.Linear(hidden_dim, 1) for _ in range(num_tasks)])
def forward(self, x, task_index):
shared_repr = torch.relu(self.shared_layer(x))
output = self.task_heads[task_index](shared_repr)
return output
model = MultiTaskModel(input_dim=128, hidden_dim=64, num_tasks=4)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# x_batch: Input features
# y_batch: Ground truth
# task_batch: Task indices
output = model(x_batch, task_batch)
loss = criterion(output, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
In this example, there is a single shared representation. Each task has its own output head that tailors the shared representation to the respective objective. Different tasks can share most of the parameters while retaining the flexibility for task-specific outputs.
Ensuring Maintainability
Unify model code, data ingestion, monitoring, and deployment. Reduce repeated feature engineering logic by producing a common feature set for all tasks, reusing transformations wherever possible. Keep alerting, logging, and fallback infrastructure centralized. This simplifies on-call duties and reduces code duplication.
Handling New Use-Cases
If you want to add a new recommendation type, expand the request context schema to cover its specific features. Include a new label-generation process and add an extra output head to the multi-task model. Because of the unified pipeline, you avoid major refactoring. The flexible design allows quick iteration to onboard new tasks.
Follow-Up Question 1
What if one task significantly outperforms the others, or receives far more training data, causing the model to be biased toward that task?
Answer
Balance losses for each task. Adjust each task’s loss weight w_t. Increase it for underrepresented tasks and decrease it for overrepresented tasks. Ensure the data loading process is stratified so every task is well-sampled. In practical implementations, track separate validation metrics per task. If a single task’s metric regresses, investigate rebalancing the loss weights or collecting more data for the underperforming tasks.
Follow-Up Question 2
How do you preserve real-time personalization for critical tasks if you only have a consolidated model?
Answer
Deploy the model in a real-time inference environment that supports up-to-date features, caching, and partial refits. Use streaming data pipelines for rapid feature updates. If a subset of tasks requires instant personalization, keep a minimal fast inference microservice for those requests, while still sharing most weights in the unified model. Introduce a short caching window to handle request spikes. Maintain frequent model updates or partial finetuning loops that refresh the shared representation. If a task has extreme latency requirements, consider a specialized deployment environment, but ensure it reuses the same underlying model to avoid fragmentation.
Follow-Up Question 3
What considerations do you keep in mind for model monitoring when multiple tasks share a single model?
Answer
Monitor each task separately on key performance indicators like click-through rate, engagement time, or conversion rate. Track aggregated metrics that measure global stability. Tag every inference request with its use-case identifier. Segment logs by task_type for quick diagnostic checks. Use error alerting or anomaly detection for each task. Evaluate model outputs offline with a separate validation dataset for each use-case. If any metric degrades, roll back changes or retrain on the consolidated dataset after adjusting relevant hyperparameters.
Follow-Up Question 4
How does this architecture handle business rules that vary across tasks?
Answer
Pre- and post-processing steps remain modular. Insert them in the request pipeline, not the core model. Each use-case can do its own filtering, ranking constraints, and fallback logic. The unified model provides a shared ranking score. The final output can still incorporate business-driven constraints. Keep these separate so they do not clutter the shared model code or cause large expansions in the model’s parameters for minor policy changes.