
ML Case-study Interview Question: Ranking Visually Compatible Furniture Using Deep Embeddings and Triplet Loss.


Browse all the ML Case-Studies here.
Case-Study question
A furniture e-commerce platform wants to recommend visually compatible products to customers. An item that a user has shown interest in (the anchor) should be paired with another product (the positive) that matches the anchor’s style, while avoiding items (the negative) that clash. Each product spans varied visual attributes like color, material, and shape. Propose a deep learning approach that ranks complementary products for any given anchor in real time. Clarify data collection strategies, model architecture, training methodology, and how to handle new items with minimal or no historical user interactions.
Detailed solution
A common approach is to learn an embedding space where compatible items lie near each other. One way is to use a Siamese Network with a triplet loss that pulls an anchor and a positive close while pushing a negative away. This reduces reliance on extensive user interaction data and allows cold-start items to be embedded based on visual features.
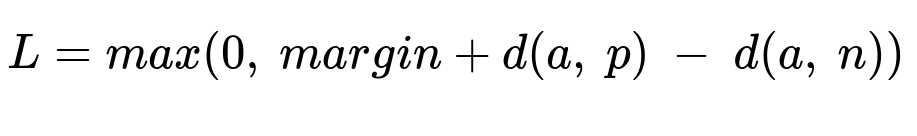
Here a is the anchor image embedding, p is the compatible item embedding, n is the incompatible item embedding, margin is a non-negative separation threshold, and d() is the squared Euclidean distance.
A second objective can involve a cross-entropy classification term that helps the model attend to different style criteria for different classes. This is helpful if a sofa-to-table match emphasizes color or shape differently than a sofa-to-rug match.
A convolutional neural network pretrained on large-scale image data is typically used as the base. One branch processes the anchor, another processes the positive, and a third processes the negative. The outputs go through L2 normalization, then the triplet loss penalizes instances where negatives are closer to the anchor than positives.
Training data can come from multiple sources. Some curated examples might be from 3D scene designs by in-house stylists, because those items are arranged together by experts. Another source might be existing purchase or browsing data. Items that are co-listed or co-ordered offer clues on real-world compatibility. Combining diverse data ensures the model learns broad style relationships, not just popularity patterns.
In production, embeddings for every product are precomputed. When a user views an item, the system fetches its embedding and performs a nearest neighbor search among candidate classes, returning top-ranked items with minimal latency. This avoids scanning the entire catalog in real time. Periodic re-embeddings ensure fresh inventory items are included and older items are updated with refined representations.
Below is an example of how to define a simplified triplet loss in Python using PyTorch:
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super().__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
dist_pos = (anchor - positive).pow(2).sum(1)
dist_neg = (anchor - negative).pow(2).sum(1)
losses = torch.relu(self.margin + dist_pos - dist_neg)
return losses.mean()
This snippet calculates the core part of the loss. The full model would include a convolutional backbone and a projection head that outputs normalized embeddings. After training, these embeddings help in retrieving compatible products.
Transfer learning speeds up convergence. One can fine-tune only the last few layers of the pretrained convolutional network or unfreeze the entire model, depending on data volume. Overfitting is mitigated via regularization (dropout, data augmentation, or weight decay). Once trained, the model captures cross-category style cues, allowing it to recommend coherent sets of furniture.
Follow-up question 1
How do you mitigate biases toward popular or frequently purchased items when training the compatibility model?
Answer: Bias often surfaces if the training data heavily skews toward high-selling items. One strategy is mixing multiple data sources. Include balanced samples from scene designs or internal style experts that incorporate lesser-known products, not just user-driven lists. Another approach is importance sampling, giving new or less-visited items a chance to appear in the triplets. A final check involves evaluating whether embeddings for cold-start items separate appropriately from the known popular items. If needed, regularize the triplet selection process or add class-balanced sampling so that the model sees a more representative distribution.
Follow-up question 2
How would you scale this solution to handle a constantly expanding catalog?
Answer: Maintain a dedicated pipeline that processes newly added products by extracting their embeddings immediately or on a fixed schedule. This pipeline uses the same trained model so the new embeddings remain consistent. Store them in an approximate nearest neighbor index (such as a library using Hierarchical Navigable Small World graphs or Product Quantization). When a customer views an anchor product, the system computes or retrieves that anchor’s embedding, looks up the nearest neighbors among relevant product classes, and returns the results. Periodic index rebuilding or incremental insertion keeps the results fresh. Caching popular items’ embeddings in memory further boosts retrieval speed.
Follow-up question 3
How would you incorporate color-based or material-based queries if customers specify preferences explicitly?
Answer: One option is to enrich the embeddings with features that highlight color or material by adding an auxiliary classification task. For instance, train a network to predict key attributes like “leather vs. fabric” or “gray vs. white,” then concatenate or fuse those attribute vectors with the main style embeddings. When searching, reweight or filter candidate items based on the requested attribute constraints. Alternatively, train a separate attribute-based model and combine its scores with the triplet-based similarity for the final recommendation. Both approaches let the user filter for specific attributes while still benefiting from the overall style compatibility model.
Follow-up question 4
How would you diagnose and fix potential failure cases where recommended products appear incompatible?
Answer: Start by examining the distance distributions or the embeddings of problematic items. Visualize them with something like t-SNE or UMAP to see if they cluster incorrectly. If certain materials or colors are mixing, refine the training set to ensure those distinctions are present in the triplets. If the model overemphasizes shape but ignores subtle texture differences, incorporate more triplets highlighting texture mismatches. Reviewing negative examples manually helps identify missing style cues. Another debugging approach is model ablation, temporarily removing cross-entropy or other auxiliary heads to see which component leads to improvement or regression. Continuous iteration on data curation and loss balancing usually resolves such misclassifications.