
ML Case-study Interview Question: Scaling Real-Time Recommendations: A Two-Stage Embedding Pipeline for Coverage and Cold Starts


Browse all the ML Case-Studies here.
Case-Study question
A major platform with millions of users wants to improve product recommendation coverage for its online marketplace. They have diverse product categories and face frequent cold starts, sparse user-item interactions, and fast-changing shopping trends. They also have global footprints, which requires real-time updates. Propose a complete plan to build an end-to-end system that handles large-scale data, generates relevant recommendations in real time, and efficiently adapts to new products and shifting user behavior.
Explain your modeling approach, data pipelines, deployment architecture, performance evaluation metrics, and experimentation strategy. Include any specific algorithms you would use and why.
Detailed Solution
The solution combines a two-stage recommendation pipeline. One stage retrieves a manageable number of candidate items. Another stage re-ranks them using a more sophisticated model. The first stage uses approximate nearest neighbor search on embeddings to speed up retrieval, and the second stage uses a re-ranking model that incorporates user signals, product features, and context.
The data pipeline starts with user clickstreams, purchases, search queries, and metadata. This is converted into training examples for the retrieval model and the re-ranking model. User IDs and product IDs are mapped to dense embeddings, updated constantly as data streams in. Real-time updates happen via a streaming pipeline. This is essential for adapting to new product listings and evolving user activity.
The retrieval model uses user embedding similarity to find a set of candidate products from a large product repository. A typical approach is to train user and item embeddings using factorization-based methods or neural methods that learn representation from historical interactions. Negative sampling is used to handle implicit feedback. To retrieve items fast in production, store embeddings in an approximate nearest neighbor index such as a library optimized for high-dimensional vector search.
The re-ranking model refines the candidate set. One popular approach is to feed user features and item features into a neural network with hidden layers. For classification-based recommendation, a common loss is cross-entropy, which measures the difference between the predicted probabilities and the actual labels. A typical logistic cross-entropy objective for a training set of size N is:
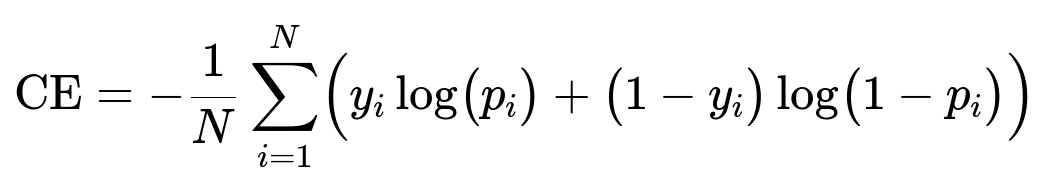
Here, y_{i} is the observed label (1 if the user interacted with the item, 0 otherwise) in the training data, and p_{i} is the model’s predicted probability of interaction. The parameters are learned by minimizing this cross-entropy. This helps the model distinguish items the user is likely to engage with.
The architecture uses a shared embedding space for retrieval, then a separate neural network for re-ranking. The retrieval step must handle millions of items quickly. The re-ranking step is more computationally expensive, so it is limited to a small set of candidates. Batch processing frameworks handle large data offline, but real-time pipelines ingest new interactions to refresh user and item embeddings. These updated embeddings are pushed to serving layers or cached in memory for instant lookups.
The evaluation relies on top-k metrics such as Hit Rate and Mean Average Precision. In an offline setting, hold out a portion of historical interactions. Generate a rank of items for each user in the test set, then see if purchased or clicked items appear near the top. Online performance is measured with A/B tests. Subsets of live traffic see the new pipeline. Compare clickthrough rate, revenue, or other key business metrics to the old pipeline.
The experiment strategy cycles through offline prototyping of new features or architectures, followed by staging environment tests, then limited region rollouts, and finally a global launch if outcomes are positive. This iterative approach reduces risk of negative user impact.
Below is a minimal Python code snippet that shows an example training loop for a neural re-ranking model. This is just a schematic:
import torch
import torch.nn as nn
class ReRanker(nn.Module):
def __init__(self, user_dim, item_dim, hidden_dim):
super(ReRanker, self).__init__()
self.fc = nn.Sequential(
nn.Linear(user_dim + item_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
nn.Sigmoid()
)
def forward(self, user_emb, item_emb):
x = torch.cat((user_emb, item_emb), dim=1)
return self.fc(x)
# Example training logic
model = ReRanker(user_dim=128, item_dim=128, hidden_dim=64)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.BCELoss()
for epoch in range(num_epochs):
model.train()
for user_emb_batch, item_emb_batch, labels in dataloader:
preds = model(user_emb_batch, item_emb_batch)
loss = loss_fn(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
This model concatenates the user embedding and item embedding into a single vector, runs it through a feed-forward network, and outputs a probability of interaction. In a real production environment, user_emb and item_emb come from a database or feature store that is updated constantly.
Models must handle cold start for new products and new users. Train an additional system that leverages content-based features (e.g., product descriptions, user demographics) or rely on unsupervised embeddings that do not require large historical interactions. Incorporate domain knowledge (e.g., brand popularity) for new items. For new users, apply a lightweight model to guess preferences based on minimal data or context from sign-up.
What if the system lacks enough negative samples?
A balanced training set is often necessary for stable learning. When positive samples far exceed negative samples, the model might struggle. Sample additional negatives from the item pool. Weighted sampling or easy/hard negative sampling can help. Hard negatives are items that are similar to positives but not actually clicked or purchased. Adjust the sampling probability so the model sees a wide variety of items that the user did not interact with. Evaluate these strategies with validation sets to confirm improvements.
How do we ensure real-time embeddings are updated fast?
Run a streaming pipeline that listens to user actions and quickly re-computes or refines embeddings. For example, use micro-batches on a streaming system that updates user embeddings every few minutes or even seconds. For items, cluster them by similarity so updates propagate only to relevant neighbors. Cache the new embeddings in a fast key-value store. When a new request arrives, fetch the latest user embedding from the cache and pass it to the retrieval service. This ensures the system reacts to trends rapidly.
How do we handle ranking for big audiences with multiple user segments?
Segment the user base by region, language, or preferences. Maintain separate retrieval indices if necessary. Some features may vary by market, like local product availability or currency conversions. The re-ranking model can contain embedding lookups for separate segments if user behaviors differ widely. Conduct region-based A/B tests to confirm the model generalizes well across segments.
How do we evaluate the overall business impact?
Analyze both short-term and long-term engagement. Short-term metrics include clicks, conversions, add-to-cart rates. Long-term metrics focus on returning users, user satisfaction, and purchase frequency. Compare these before and after the new pipeline. Log user-level interactions for in-depth analysis. If metrics are positive, roll out widely. If some segments see regressions, refine the approach or implement segment-based ranking logic.
What if we need more personalization?
Include more user-side features (e.g. recency of last purchase, average spend) or item-side features (e.g. brand, product metadata). Combine embeddings with these features. Incorporate user context like device type or time of day. The re-ranking model can have attention mechanisms or gating layers to weigh which features matter most. Profile memory usage and inference latency so the pipeline remains scalable.
How to mitigate overfitting and ensure model generalizes?
Use regularization methods such as dropout in neural layers or weight decay. Reduce embedding dimensionality if the model memorizes training data. Validate regularly on a hold-out set. Rotate or shuffle negative samples. Monitor A/B tests for consistent gains. If results degrade, check for data skew or distribution shift. Adjust hyperparameters, re-balance positive/negative examples, or increase training data diversity.