
ML Case-study Interview Question: Scalable Real-Time Recommendations: Collision-Free Embeddings via Cuckoo Hashing for Sparse Data.


Case-Study question
A large-scale video platform needs a real-time recommendation system. They receive massive user signals every minute and must adjust recommendations quickly. They have extremely sparse user and item features, where new IDs arrive continuously, and old IDs become inactive. They also must capture user behavior shifts in near real-time. Propose a system architecture and training pipeline that handles:
Collision-free embeddings for sparse features.
Real-time data streaming and model updates to tackle concept drift.
Efficient parameter synchronization between training and serving to keep recommendation quality high while avoiding huge memory and network overhead.
Failover and fault tolerance mechanisms.
Explain the complete solution. Outline the main design choices, how they reduce collisions in embedding representations, how they handle non-stationary data distributions, and how they efficiently perform real-time model serving. Show how you would maintain high reliability with a minimal loss in performance.
Detailed solution
Collisionless Embedding Table
Use cuckoo hashing to store sparse embeddings without collisions. Build a large-scale key-value store where each ID is placed in one of multiple possible locations. If a location is occupied, evict that occupant, reinsert it into an alternate location, and repeat until all insertions stabilize or a rehash is triggered.
Maintain expiration for inactive IDs and frequency filtering before admission. Expire IDs not seen for a long time. Filter out extremely rare IDs to save memory.
Real-Time Data Streaming
Adopt a streaming approach. Gather user actions from a queue, join them with features, then push them as training examples. Use negative sampling to handle class imbalance. Apply log odds correction at serving time to calibrate predictions.
Core DeepFM Model
Use factorization machines plus a multi-layer perceptron for final prediction. A standard DeepFM formula:
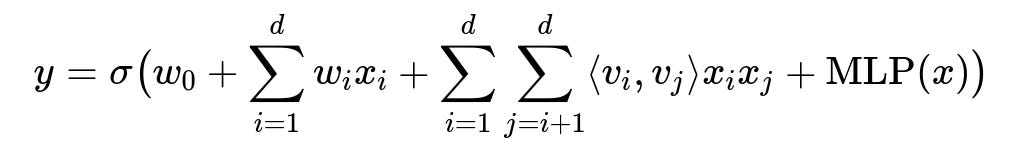
Here y is the predicted probability. x is the input feature vector. w_{0} is a global bias. w_{i} are linear weights. v_{i} are embeddings for factorization machines. MLP(x) is a dense neural network applied on the same input. sigma is the sigmoid function for binary outcomes.
Parameter Synchronization
Push embeddings from training to serving in increments. Only send updated sparse embeddings on a short interval. Send dense weights less often. This reduces bandwidth usage and prevents large memory spikes. Keep serving uninterrupted during model updates.
Fault Tolerance
Snapshot the full model periodically. Recover from the last snapshot if a parameter server fails. Accept that a small part of recent user updates may be lost. The effect remains small given the broad user base and sparse updates.
Implementation Details
Maintain separate infrastructure for batch and online training. Use a streaming engine like Kafka plus a joiner to unite labels and features in real time. Sync updated parameters from training to serving continuously. Update embeddings that changed since the last sync. Update dense layers less frequently.
Keep a robust caching layer for feature joins. When user events arrive out of order, persist features on disk and match them with delayed user signals.
Practical Trade-offs
A short synchronization interval preserves fresh user trends at the cost of higher network and compute overhead. A daily snapshot is enough for dense parameters. Sparse parameters require more frequent updates. This speeds adaptation to shifting user interests while limiting resource usage.
What if the system sees unbounded ID growth?
Build an eviction policy that removes stale IDs after a fixed period of inactivity. Filter extremely rare IDs to manage memory. Keep the cuckoo hash dynamic so new user or item keys can be inserted without collisions.
How do you handle skewed distributions in clicks?
Use negative sampling and set a suitable ratio of negatives to positives. Calibrate the final predictions with log odds correction at inference. This ensures an unbiased probability output.
Why are embeddings updated more often than dense layers?
Sparse embeddings are specific to particular users or items and shift faster as behaviors evolve. Dense parameters aggregate global patterns, so their drift is slower. Frequent sparse updates capture transient user actions. Less frequent dense updates reduce overhead.
How do you ensure minimal service interruption?
Incrementally apply updated parameters. Let the serving system swap embeddings in memory on the fly. Keep partial older parameters active until the new batch fully loads. Avoid blocking or shutting down the serving cluster during updates.
How do you evaluate performance over time?
Track AUC or other classification metrics every day. Compare real-time training with purely batch-trained models. If the real-time version yields consistent lifts in online metrics, keep short sync intervals. If the gain is minimal, possibly lengthen intervals to reduce overhead.
How do you handle large-scale failures?
Store frequent model snapshots. Recover lost parameter servers from the last snapshot. Rely on daily or multi-daily snapshots. Accept that a fraction of updates is lost if one parameter server fails. Empirical tests show the final effect is small given the small portion of IDs residing on the failed node.