
ML Case-study Interview Question: Categorizing Short Text Savings Goals with Biterm Topic Modeling


Browse all the ML Case-Studies here.
Case-Study question
A leading digital bank provides a feature where users can create short free-text savings goals, sometimes with emojis. Over time, millions of these goals have accumulated, making it hard to categorize them manually. You are asked to design a scalable approach to cluster and understand how customers use these goals, identify major themes, and uncover seasonal patterns. Formulate a comprehensive plan that covers dataset construction, cleaning steps, topic modelling method selection (including handling short texts and emojis), model evaluation, and strategies for interpreting and applying the results. Propose your best solution.
Detailed Solution
Data Collection and Preparation
Data consists of short textual names, each reflecting a savings purpose. Some names contain emojis. Some are typos or single words. Gathering a large sample ensures broad coverage of different savings goals. Lowercasing is applied. Removing punctuation is necessary. Typos or equivalent words are standardized by lemmatization and string matching (for example, mapping "bday" to "birthday"). Emojis are mapped to textual placeholders like ":house:" so they can be processed and categorized.
Handling One-Word Entries
Many entries are a single word such as "Savings" or "Bills." They lack context for topic modelling approaches that rely on collocated words. Mapping one-word items to predefined lists of known keywords is a fallback plan. This hybrid approach captures items the model might otherwise fail to classify.
Topic Modelling Approach
Traditional topic models such as Latent Dirichlet Allocation rely on word co-occurrence in extended documents. Short names complicate this because word context is minimal. A specialized technique, Biterm Topic Modelling (BTM), focuses on counting distinct word pairs across the entire text. This method scans all possible word pairs from each short document to learn topics.
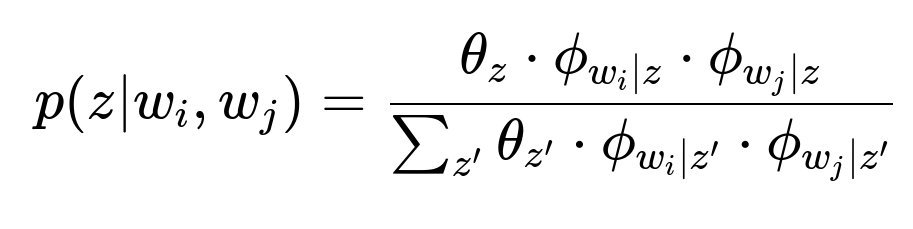
Here, z represents a topic. theta_z is the topic proportion in the corpus. phi_{w_i|z} is the probability of word w_i appearing under topic z. phi_{w_j|z} is the probability of word w_j appearing under topic z. The summation in the denominator normalizes the probability across all topics.
Model Tuning
Choosing the number of topics is done by trying multiple values and tracking coherence scores. A higher coherence implies words grouped under each topic have stronger semantic ties. Once the best number of topics is found, top representative words for each topic are examined to ensure they match real categories.
Building Category Lists
The output of BTM yields strong word clusters. From these clusters, lists of words and phrases are built. Single-word entries or edge-case text with limited context are mapped to these lists. Emojis are also matched to relevant clusters, for instance mapping ":gift:" or ":dog:" to "Life Events" or "Pets."
Observing Seasonality
Time-based exploration on these topics reveals how frequently each category is created. "Travel" topics might spike in January (post-holiday blues) or near summer months. "Gifts" or "Christmas" appear more often in late year. Pandemic periods show dips in travel-related categories. Observing these trends informs product strategies.
Sample Code Snippet
import re
import pandas as pd
from btm import OBTM # Example import, depends on chosen library
# Sample data
pot_names = [
"Holiday in Spain :flag_es:",
"Bills",
"Birthday fund :gift:",
"House deposit :house:",
...
]
# Data cleaning
cleaned_pot_names = []
for name in pot_names:
text = name.lower()
text = re.sub(r'[^\w\s:]', '', text) # remove punctuation except colon for emojis
text = text.replace("bday", "birthday")
text = text.replace(":house:", "house_emoji") # map house emoji to text
# add more replacements or lemmatization logic
cleaned_pot_names.append(text)
# BTM
obtm = OBTM(num_topics=20, alpha=50/20, beta=0.01)
obtm.fit(cleaned_pot_names, iterations=1000)
# Extract topics
topics = obtm.get_top_k_words_per_topic(k=10)
for i, topic_words in enumerate(topics):
print("Topic", i, ":", topic_words)
Here, num_topics must be tuned by testing different values and checking coherence or other metrics. This snippet is illustrative; real usage may involve specialized libraries or custom implementations.
Practical Outcome
Clusters cover bills, generic saving, travel, events like birthdays or weddings, and other goals. Single-word names are matched through the built keyword lists, avoiding misclassifications. Emojis provide additional context. This classification pipeline reveals high-level categories, their seasonal fluctuations, and popular saving themes.
Potential Follow-Up Questions
1) How do you handle new or unexpected words that are not in your keyword lists?
Unrecognized words can still be processed by the topic model, which infers their associations via word-pair distributions. Updating the word-to-topic lists periodically ensures coverage of emerging jargon. Embedding-based similarity approaches can suggest replacements for out-of-vocabulary words. For instance, we can maintain a background corpus or a continuous learning pipeline. If novel terms appear often, the model might be retrained or incrementally updated.
2) What if the coherence metric is inconsistent with human judgment of topic quality?
Coherence is helpful but not perfect. Practical solutions include a mixed approach. First, measure coherence. Then manually inspect top words per topic to confirm quality. In a business context, verifying interpretability is critical. If a topic has top words that make sense together, it is a useful cluster. If not, refining the preprocessing or adjusting the number of topics helps reconcile differences.
3) How do you incorporate user feedback or domain expert insights?
Experts can map certain words or emojis to specific themes. Incorporating curated dictionaries or synonyms ensures alignment with real business needs. For example, domain experts might want "salary" or "paycheck" to fall under "Bills," even if a purely data-driven approach puts them in a different cluster. Iterating on a feedback loop from subject matter experts (like product managers or finance teams) refines model outputs.
4) How do you manage privacy or sensitive data issues with free-text fields?
Names containing personal information or private references must be filtered or masked. Using hashed or anonymized forms of text can preserve privacy while still preserving word distribution statistics. Policies for data retention, encryption, and access control must be respected, especially under stricter regulations like GDPR. Only aggregated or de-identified topic distributions are shared for internal analysis.
5) How do you scale this solution with rapidly growing data?
Processing can be parallelized using distributed computing frameworks. Splitting the dataset into batches for iterative BTM fitting or streaming-based training methods keeps computation feasible. Caching preprocessed text reduces overhead if multiple experiments are needed. For real-time classification, a pre-trained model can label new names on demand, updating the system periodically to account for vocabulary shifts.
6) How would you measure success or return on investment (ROI)?
Tracking user engagement changes after enhancements is one measure. If certain categories indicate new product opportunities, measuring adoption rates or user satisfaction helps quantify the impact. Time-series analysis of category usage over months or years shows whether the product improvements align with customer saving patterns. A direct uplift in user satisfaction, retention, or new feature usage can validate the project’s success.
7) What if many category predictions are borderline?
Confidence thresholds can be introduced. If a name has low probability for each topic, it might be flagged for review or a fallback bucket labeled "Miscellaneous." Combining confidence measures with interpretability checks ensures consistent labeling. Gradual refinement of the model or category lists can reduce borderline cases over time.
Exhaustive testing of each step, consistent retraining or updating with fresh data, and careful interpretation of the results form the backbone of this solution.