
ML Case-study Interview Question: Real-Time Harmful Text Detection in User Reviews Using LLM Classification


Browse all the ML Case-Studies here.
Case-Study question
Imagine you have a user-generated content platform with millions of reviews posted daily. Some reviews contain harmful or offensive text. Your goal is to build a binary classification system that flags highly inappropriate content such as hate speech, lewdness, threats, and other forms of harassment, in near real-time. The platform’s existing moderation process is partly manual and partly automated. You are asked to propose a machine learning solution to address this at scale, ensuring high precision and recall. How would you approach this problem from data collection, model training, deployment, and post-deployment monitoring?
Detailed Solution
This platform collects user reviews. Some are inappropriate, including hate speech, explicit language, or threats. The volume of reviews is massive, so human moderation alone is costly. A Large Language Model (LLM) can help identify these reviews rapidly.
Data Curation
First, assemble a dataset containing examples of both appropriate and inappropriate content. Work with the moderation team to label past samples, focusing on examples with explicit or hateful elements. Introduce a severity scoring scheme to distinguish levels of harmfulness. Use embedding-based similarity to expand the dataset by finding additional samples that match the labeled examples in semantic space. Handle class imbalance with strategies like:
Oversampling rare sub-categories.
Undersampling the majority class.
Zero Shot and Few Shot Sub-Categorization
When explicit sub-category labels (e.g. hate speech vs. lewdness) are missing, use zero shot or few shot classification. Prompt an LLM to predict which category fits the text, then rebalance the training data with the needed sub-categories.
Model Architecture and Embeddings
Obtain a pretrained LLM from a public repository. Extract embeddings for each review. Visualize separation of appropriate vs. inappropriate reviews by dimensionality reduction (e.g. t-SNE). If there is sufficient separation, proceed to fine-tuning.
Fine-Tuning for Classification
Attach a classification head to the LLM. Train the model to output 1 for inappropriate and 0 for appropriate text. Use cross-entropy loss to optimize parameters.
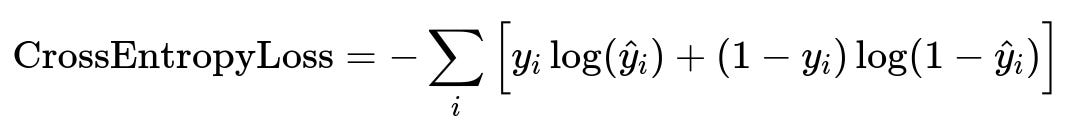
Where y_i is the true label (0 or 1), and hat{y}_i is the predicted probability of class 1 for sample i.
Assess metrics like precision, recall, F1-score, and confusion matrices on a balanced test set. Analyze false positives carefully because the real-world percentage of inappropriate content is small, and an excessive false positive rate causes poor user experience.
Threshold Tuning
Even if the model outputs a probability, you must choose a threshold for classification. Because real-world data might have very low prevalence of harmful content, run experiments with different spam prevalence rates in mock traffic. Adjust the threshold to reduce false positives. This ensures only the most egregious content is flagged.
Deployment and Real-Time Inference
After finalizing the model, package it with your platform’s ML serving stack. Store historical data in a data warehouse. Run a batch pipeline to preprocess and train or retrain the model regularly. Register the model in a model registry. Serve it with a suitable inference service that exposes an endpoint. The system intercepts new reviews, scores them in real-time, and flags them if the score passes the threshold.
Human-in-the-Loop
For each flagged review, keep human moderators in the loop. Their final decisions feed back into the pipeline, improving the dataset. Retrain the model periodically using these fresh labels.
Example Python Snippet
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "some-llm-model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
sample_review = "This place was terrible. The staff used hateful language."
inputs = tokenizer(sample_review, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)
score_inappropriate = float(probabilities[0][1].item())
threshold = 0.75
if score_inappropriate > threshold:
print("Review flagged as inappropriate.")
else:
print("Review is appropriate.")
The tokenizer encodes the text. The model outputs logits for the two classes. Softmax transforms logits into probabilities. If the probability of the inappropriate class exceeds the threshold, flag it.
Possible Follow-up Questions and Answers
1) How do you address sarcasm or subtle language that might be offensive?
Sarcastic text may not contain obvious hateful terms. Rely on LLM context awareness. Train on examples containing sarcasm by collecting annotated data with subtle cues. Expand labeled examples that moderators consider offensive even if no direct slurs appear. Use these for fine-tuning. If the model struggles, add more human moderation feedback loops.
2) What if the dataset is heavily imbalanced?
Imbalance is expected, since most content is benign. Use class rebalancing strategies. Over-sample minority classes or synthesize data (e.g. data augmentation). Under-sample the dominant class. Carefully monitor overfitting on minority classes. Maintain a realistic ratio or tune it so the model learns enough from the rare examples.
3) How do you set a decision threshold when real-world spam prevalence is small?
Generate mock traffic sets with different prevalence levels (for instance 0.1 percent to 5 percent). Calculate false positives and false negatives under varying thresholds. Aim for high precision while maintaining acceptable recall. Start with a conservative threshold, then monitor flagged content in production to see if moderators find too many false positives.
4) Why not just use an out-of-the-box LLM without fine-tuning?
Pretrained LLMs have general language understanding but might not focus on specific definitions of harmfulness. Fine-tuning aligns the model to the platform’s policy. Target training ensures it learns examples most relevant to your context. Out-of-the-box models may exhibit higher rates of confusion on borderline offensive language.
5) How do you maintain good performance over time?
User language evolves. New slurs or coded words may appear. Periodically collect fresh flagged reviews, incorporate them into the training set, and retrain the model. Regular audits help catch drift or new language patterns. Maintain close collaboration with moderators to label any newly surfaced categories of hate speech or inappropriate text.
6) Does real-time scoring add latency for users posting reviews?
Running an LLM can be resource-intensive. Use optimized inference (GPU acceleration, model quantization, or distillation). Deploy an asynchronous pipeline if real-time blocking is not strictly required. If near-real-time is needed, scale your system with load balancers and hardware accelerators. Use caching or simpler heuristic filters for extremely large volumes, then pass borderline cases to the LLM pipeline.
7) How do you deal with false positives that might cause user discontent?
False positives can harm trust. At high traffic, a small proportion of misclassifications can still affect many users. Keep precision high. Provide appeals or corrections so users can dispute flagged content. Human moderators should check flagged content. Track your false positive rate and continuously refine the threshold.
8) How do you handle the variety of offensive content categories?
Break down categories (hate speech vs. sexual content vs. harassment). Create sub-labels. Train a multi-class classifier or a hierarchical approach. Or keep it binary but ensure your training data includes diverse examples. If the platform’s policy needs more granular detection, add separate classification heads or specialized modules.
9) How might you extend this system to other languages?
Use multilingual LLMs or distinct models for each target language. Repeat data collection, labeling, and fine-tuning for each language. Monitor differences in cultural norms and slang. Collaborate with bilingual or native-speaking moderators to ensure correct labeling.
These steps create a robust pipeline. Continue human-in-the-loop feedback, retraining for evolving content, and threshold tuning for real-world conditions.