
ML Case-study Interview Question: Scalable Hierarchical Product Classification Using Hashing and Logistic Regression


Case-Study question
A large e-commerce platform hosts millions of merchants selling billions of products. Each product has a title, description, tags, vendor name, and other text-based attributes. The platform wants to categorize these products into a predefined, hierarchical set of over five thousand categories. The categories are arranged in a tree-like structure, similar to a known product taxonomy. The merchant-provided text is highly variable and often noisy. How would you design a scalable machine learning system to assign each product to the correct path in this taxonomy? Provide details on your approach, covering how you would process the text data, train a model to handle the hierarchical nature of the taxonomy, manage inference at scale, address evaluation metrics, and incorporate feedback mechanisms.
Outline your approach, describe your key design decisions, and highlight potential tradeoffs.
Detailed Solution
Problem Understanding
The challenge arises from the large number of possible product categories and their tree-structured relationships. A simple multi-class approach does not scale easily to thousands of classes. A hierarchical classification strategy can leverage parent-child relations in the taxonomy. Handling unstructured text requires feature engineering that remains efficient when data volume is massive.
Featurization
Raw product text is variable and can contain HTML, special characters, or unusual tokens. A text-processing pipeline can clean and tokenize this data. Common steps include lowercasing, removing special characters, removing HTML, and splitting text into words (tokens). Simple text-based features often scale better for large datasets.
A hashing-based vectorizer can produce fixed-length numeric representations. This approach avoids storing a large vocabulary dictionary. The tradeoff is possible collisions, but the ability to handle billions of products can justify that risk.
Model Training
A hierarchical classification task can be converted into a single large-scale classifier using a method inspired by Kesler's Construction. The idea is to prepend the target label to each token so a single binary classifier can learn to differentiate many classes in one step. The approach sidesteps training thousands of separate models.
Logistic Regression is a suitable choice for interpretability, faster training, and simpler hyperparameter tuning at scale. It can handle high-dimensional sparse vectors from hashing-based feature extraction.
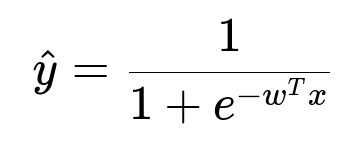
Above, y-hat is the predicted probability, w is the learned weight vector, and x is the featurized input vector. In this context, the label can be 1 (the product belongs to or is a descendant of that category) or 0 (it does not belong to that category).
Inference
A product is classified by traversing from the top of the taxonomy. The model scores each root category, picks the highest-scoring one, then repeats down the tree until reaching a leaf. This greedy approach prunes unlikely branches and reduces compute cost.
Evaluation
Standard flat accuracy, precision, or recall do not fully capture how wrong a prediction is if it is close to the correct branch. Hierarchical metrics incorporate the distance in the tree structure. A misclassification from “Shirts & Tops” to “Dresses” is penalized less than “Shirts & Tops” to “Cell Phones.” This aligns better with real-world needs.
Handling Misclassifications
A feedback loop flags incorrect predictions for human review. These corrections feed into the training pipeline so the model can continually learn from new edge cases or rarely seen product types. This human-in-the-loop approach addresses long-tail categories.
Future Improvements
Class imbalance remains a challenge when certain categories dominate the training data. Techniques such as minority oversampling or majority undersampling can help. Non-English languages require multi-lingual embedding or translation. Images could supply additional cues, but they add complexity in both feature computation and infrastructure.
Follow-Up Question 1
How do you handle categories that are new to the platform or missing from your training set?
Answer New categories pose an open set recognition challenge. One tactic is to map a product to the closest existing category, then route such cases to a specialized queue for human review. The annotation feedback creates fresh training samples for those new labels. Another method is to assign an “unknown/other” class if the confidence score is too low or text matches no known labels with sufficient probability.
Follow-Up Question 2
How do you address potential collisions in hashing-based feature vectors?
Answer Collisions occur when different tokens produce the same index in the hashing function. Empirically, increasing the dimensionality of the hash space can reduce collisions. Checking the model’s downstream performance is also crucial. If collisions degrade accuracy, the dimension should be raised or a more sophisticated hashing scheme used. Monitoring metrics like distribution of token frequencies per hash bucket can help detect problematic collisions early.
Follow-Up Question 3
What steps are necessary to incorporate image-based features?
Answer Image-based features require additional infrastructure. A convolutional neural network (CNN) can ingest product images and produce an embedding vector. Pre-trained models (for example, from large public image datasets) can generate these embeddings with less training overhead. The resulting embedding vectors are concatenated with text-based features. The system must store, process, and batch these images at scale, which demands more compute resources and a data pipeline for ingestion and transformation.
Follow-Up Question 4
What techniques can you apply to combat extreme class imbalance?
Answer Techniques include oversampling minority classes (for example, synthetic data generation methods like SMOTE in plain text or using advanced data augmentation for images), undersampling major classes, or assigning higher weights to minority classes in the training objective. Monitoring performance across both frequent and rare labels reveals whether the rebalanced model improves coverage of the less common categories.
Follow-Up Question 5
Why not use a deep learning architecture for text?
Answer Deep architectures (transformers or large-scale embeddings) could capture nuanced semantics but require large distributed systems to train on billions of records. Simpler methods like hashing plus Logistic Regression scale more predictably, demand fewer resources, and remain interpretable. A deep solution might offer higher accuracy, but the tradeoff in cost and complexity might be significant if the simpler approach already meets business needs.
Follow-Up Question 6
How do you verify the hierarchical traversal works effectively during inference?
Answer A top-down traversal selects the most likely branch at each level. A final predicted path is returned. Model confidence scores at each step can be tracked. If confidence drops below a threshold while descending, a fallback could compare sibling branches or roll back to the parent node. Testing this logic on a curated set of products ensures it chooses correct paths and avoids placing items in divergent branches.
Follow-Up Question 7
How does the logistic regression classifier learn from Kesler’s Construction in practice?
Answer Kesler’s Construction expands each training example into multiple binary-labeled examples. If an item belongs to category A, the tokens become “A_token1, A_token2,...” and get labeled 1, while other categories produce “B_token1, B_token2,...” labeled 0. This single binary model internally learns coefficient weights reflecting how tokens relate to each class. During inference, the same procedure (prepend each potential label to each token) yields a logit that indicates suitability for that label.
Follow-Up Question 8
How would you maintain model performance as the taxonomy changes over time?
Answer Taxonomy changes if new subcategories appear or categories merge. A regular retraining schedule must include data relabeled to reflect the updated hierarchy. The feedback loop ensures new categories gain labeled examples. If many categories are removed or reorganized, a data migration step updates existing labels to match new nodes. The system must remain flexible enough to accommodate these modifications in training and inference pipelines.
Follow-Up Question 9
What are the main logs or metrics you would monitor in production?
Answer Monitoring includes overall inference throughput, median latency, and hierarchical classification metrics (hierarchical accuracy, hierarchical precision/recall). Tracking top categories with the most misclassifications or user-corrected feedback helps detect data drift or changes in merchant behavior. Observing memory usage and CPU load ensures the large-scale inference pipeline remains stable under billions of products.
Follow-Up Question 10
How do you balance interpretability vs. accuracy?
Answer Logistic Regression offers interpretable coefficients but might sacrifice some accuracy compared to deeper methods. Interpretability is often critical in e-commerce, where category mistakes can be costly or violate content guidelines. If accuracy must improve further, advanced models could be considered. The final decision is a balance of performance, complexity, resource cost, and explainability for stakeholders.
Follow-Up Question 11
What if you encounter privacy or compliance requirements around product data?
Answer Data used for training must adhere to relevant regulations. Anonymization methods, secure data storage, and access controls help ensure compliance. If product text contains sensitive data, a data governance plan must remove or mask personal information before it enters the pipeline. Periodic audits confirm the pipeline’s compliance posture, and privacy-by-design principles guide new feature development.
Follow-Up Question 12
How can you incorporate domain experts in refining categories or subcategories?
Answer Domain experts can review ambiguous or misclassified items. Their domain knowledge helps refine edge cases. They provide curated examples or domain-specific vocabulary to enhance feature engineering. They also verify new or merged categories. A continuous collaboration model integrates their feedback into training or labeling workflows, improving the taxonomy’s accuracy and overall model performance.