
ML Case-study Interview Question: Categorizing User Feedback at Scale with USE Embeddings and LightGBM


Browse all the ML Case-Studies here.
Case-Study question
You are working at a major streaming platform. The company wants to automatically categorize large volumes of written feedback from two sources: an internal user satisfaction survey and a public customer support portal. They already have rough ideas of what topics or categories commonly appear in the feedback. The user satisfaction survey includes text describing opinions on content, ads, features, and bugs. The support portal tickets include requests, issues, complaints, questions, or general inquiries. The goal is to build a robust system to process daily incoming text data and classify each text snippet into the correct category. This system will then feed into a dashboard to track category trends over time and help teams prioritize improvements.
They have asked you to propose a solution approach. How will you structure your data pipeline, encode text data, select models, measure performance, and deploy the system at scale to handle continuous feedback?
Explain any important modeling design choices and specify why you choose certain embedding methods. Share any potential next steps or advanced techniques that could further improve the system.
Proposed In-Depth Solution
Data Pipeline and Preprocessing
Collect text data from both user satisfaction survey entries and customer support portal messages. Assign each piece of text a label from a curated set of categories. If text samples are unbalanced across labels, attempt basic techniques such as undersampling or oversampling to maintain good coverage across all classes. Convert all text to a normalized form by lowercasing and removing extraneous characters.
Text Embeddings
Use a pre-trained language model to transform text into numerical vectors. A suitable option is Universal Sentence Encoder (USE). Each text snippet is passed through this model to obtain an embedding that captures semantic meaning. The embeddings become the input features for downstream classification.
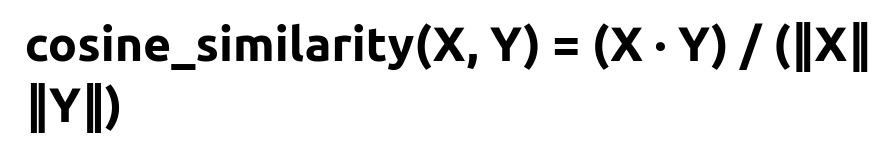
cosine_similarity(X, Y) returns a numeric value indicating how similar embedding vector X is to embedding vector Y. X dot Y is the dot product of the two vectors. ||X|| and ||Y|| are the Euclidean norms (magnitudes) of these vectors.
Classification Models
For classification, train one model per category using LightGBM or a similar algorithm. Prepare a labeled sample set of feedback snippets as the training data. For each snippet, feed the USE embedding into the model. If the model’s output probability exceeds a threshold, classify the snippet as belonging to that category. When combined, multiple such binary models can label each snippet appropriately.
Performance Metrics
Measure performance using ROC AUC, F1 score, and accuracy. Adjust thresholds to improve recall or precision, depending on whether you want fewer false positives or fewer false negatives in categorizing text. Monitor these metrics on an unseen test set.
Dashboard and Trend Tracking
Store model predictions in a database or data warehouse. Build a daily pipeline to process new feedback. Push aggregated results into a visualization dashboard. Track how many texts fall into each category over time. Observe spikes in certain categories to identify urgent issues.
Scalability
Deploy the trained models in a streaming or batch-based environment. For a streaming approach, wrap the model inference logic in a lightweight service that processes new requests in near-real-time. For a batch-based approach, schedule daily or hourly jobs that handle large volumes of text. Ensure the environment accommodates potential traffic surges from sudden spikes in feedback.
Future Enhancements
Consider multiclass or multi-label techniques to reduce the overhead of training multiple separate models. Experiment with more advanced encoders like BERT or XLNet if you require deeper language understanding. Incorporate sentiment analysis or keyword extraction to derive richer insights.
How do you handle feedback that fits multiple categories at once?
Some snippets might discuss more than one topic. A user could mention both ads and a bug. Treat the classification as a multi-label problem. Build one model per label or switch to an algorithm that can natively handle multiple labels. Evaluate each category separately, then merge the predictions into a final set of labels.
When training, ensure that data labeling clearly identifies which snippets belong to more than one category. During inference, do not force exactly one category. Let the system predict all relevant categories, and only filter if there are business rules that dictate a single category.
How would you approach data imbalance in this scenario?
Manually labeled data often has uneven label distributions. If certain categories occur far less frequently, the model may neglect those classes. To mitigate that, set class weights or apply sampling techniques. For example, oversample the minority classes or undersample the majority classes. Monitor confusion matrices to see if the model is ignoring rare categories. Adjust thresholds or use advanced sampling methods like SMOTE if needed.
Which performance metrics matter the most and why?
ROC AUC, accuracy, and F1 score are standard. Focus on ROC AUC to measure trade-offs between true positives and false positives across various thresholds. F1 is useful if you value a balance of precision and recall. Accuracy alone may be misleading with highly imbalanced data, since the model could learn to ignore rare classes yet still achieve high accuracy. Combine these metrics for a comprehensive view.
Why use Universal Sentence Encoder over BERT?
USE’s architecture is optimized for sentence-level embeddings that capture general semantic information, which is advantageous for text similarity and classification. BERT is often used for tasks requiring context-specific token-level or masked word predictions. For category classification of short user feedback, USE can yield strong results with fewer resources. If your text segments are lengthier or your classification tasks require deeper contextual analysis, BERT might be a better choice, though potentially more resource-intensive to deploy.
How to implement the system in Python?
Load a pre-trained USE model through TensorFlow Hub. Example Python snippet:
import tensorflow_hub as hub
import lightgbm as lgb
use_model = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
def get_embeddings(text_list):
return use_model(text_list).numpy()
# Suppose X_text is your list of text, y is the label array
X_embeddings = get_embeddings(X_text)
train_data = lgb.Dataset(X_embeddings, label=y)
params = {
"objective": "binary",
"metric": "auc",
"boosting_type": "gbdt"
}
model = lgb.train(params, train_data, num_boost_round=100)
This snippet constructs embeddings for each text snippet, then feeds them to a LightGBM classifier. The model predicts class probabilities for new text by generating embeddings and passing them through the same pipeline.
Would you consider a deep learning approach for classification?
Yes, large transformer-based methods can be fine-tuned end to end. That approach might give higher accuracy at the expense of training complexity. Fine-tuning BERT or other transformers can capture complex language patterns missed by simpler architectures. However, ensure you have enough labeled data and suitable hardware. If performance gains justify the resource cost, fine-tuning can be worthwhile.
How do you handle evolving categories over time?
User feedback changes. Introduce a process to identify new themes or categories as you analyze incoming data. Periodically review out-of-domain texts or clusters of low-confidence predictions. Add new categories if they become consistently relevant, and retrain or update the models. Implement human-in-the-loop checks for newly emerging topics so you can keep classification consistent.
How to ensure deployment reliability?
Containerize the inference pipeline so it can scale horizontally. Monitor throughput, memory usage, and model latency. Log model predictions and any errors. If you use a batch pipeline, schedule it with a tool like Airflow. Test for regression whenever you retrain. Confirm that threshold adjustments or new categories do not break existing dashboards. Keep a rollback mechanism ready in case a new model behaves unexpectedly.