
ML Case-study Interview Question: Self-Supervised Session Embeddings for Advanced E-commerce Fraud Detection


Browse all the ML Case-Studies here.
Case-Study question
A major e-commerce platform observed frequent fraudulent activities on its site, leading to unauthorized transactions and policy abuses that harmed both customers and the company. Data Scientists built a self-supervised customer session embedding system to capture user behavior patterns, then fed those embeddings into downstream fraud detection models. The result increased fraud detection performance by up to 18 percent (as measured by area under the Precision-Recall curve). Assume you have inherited this system and want to enhance it. How would you design and implement a pipeline that learns customer journey embeddings from session data, then applies those embeddings to advanced fraud detection tasks? What specific steps would you take, what model architectures might you consider, and how would you measure success?
Provide your full solution, including:
Details on collecting raw session data
Method for self-supervised representation learning and embedding inference
How the resulting embeddings would feed into downstream classification models
Approaches for evaluating improvement
Thoughts on scaling and future enhancements
Detailed solution
Collect raw session data by logging each page visit, user interaction, and time interval for each user session. Each user can have multiple browsing sessions. Concatenate session records into chronological sequences. Keep relevant features such as page type, click actions, and timestamps.
Embed the sequences with a self-supervised technique. Train a sequence model (such as a Recurrent Neural Network or a Transformer) using a pretext task to predict the next page type. This task requires only session data, so no manual labels are needed.
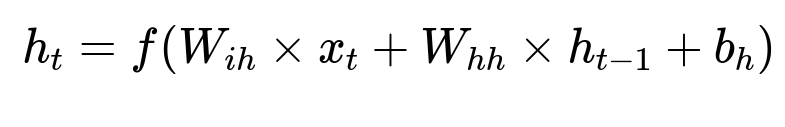
Here h_{t} is the hidden state at time t, x_{t} is the embedding of the t-th page type, W_{ih} and W_{hh} are learnable weights, and b_{h} is a bias term. f is a non-linear activation function such as tanh or ReLU. This captures temporal patterns in the sequence.
After training, extract the intermediate layer as the embedding vector for each session. Aggregate session-level vectors for the same customer over a short history (for instance, the last three sessions) to produce a final customer embedding vector. Feed these embeddings into your fraud model, possibly concatenating them with manual features such as average spend, frequency of returns, or known user metadata.
Evaluate performance by comparing metrics such as Precision-Recall AUC or ROC AUC on a holdout set of fraud labels. Measure improvements in detecting suspicious transactions and watch for changes in false positive rates. Re-train periodically, because fraud patterns shift over time.
To scale, run the inference step on a recurring schedule or near-real-time stream. Store embeddings in a feature store accessible to all downstream tasks. For future enhancements, experiment with more advanced architectures, such as Transformers, or adopt contrastive learning to create embeddings that separate normal versus malicious sequences more clearly.
Common follow-up question: How would you handle concept drift?
Concept drift refers to changing data distributions over time. Fraud behaviors evolve. Monitor model performance weekly. Trigger a re-training cycle when performance drops below a threshold. Incorporate a rolling window of recent data for re-training. Incrementally update embeddings or use online learning if real-time updates are needed. Validate that the new model continues to capture fresh fraud patterns without overfitting.
How would you ensure robustness if labels for fraud are delayed or scarce?
Collect weak labels from suspicious signals (chargebacks, returns, repeated unusual activity). Use self-supervised tasks that do not require explicit fraud labels. Create pseudo-labels from rules or from user-initiated flags. Validate those against a small set of verified fraud labels. Fine-tune your embedding on partially labeled data. Employ unsupervised or semi-supervised anomaly detection if explicit labels are insufficient.
How could you address cold-start issues for new users?
New users have little historical data. Generate partial embeddings from smaller sequences or rely on session-level embeddings alone. Initialize embeddings from a general pre-trained model built on broad user data. Update them when the user interacts enough times to form a meaningful sequence. In downstream fraud models, combine these partial embeddings with generic population-level statistics to mitigate sparse user data.
Why use self-supervised learning instead of just manually crafted features?
Manually crafted features often miss complex, hidden patterns. Self-supervised learning captures subtle relationships across time. It scales across numerous behaviors (page visits, clicks, device usage) without domain-specific engineering for each. It updates automatically as new data arrives. By combining the learned embeddings with manual features, you leverage both domain knowledge and pattern discovery.
Would you consider a Transformer or a Graph Neural Network?
Yes. A Transformer can capture long-range dependencies in user sessions and handle variable-length sequences efficiently. A Graph Neural Network can represent users and items as nodes, with edges showing interactions. Either method can produce rich embeddings. Compare each approach’s performance and complexity in controlled experiments, then choose the best for your fraud detection requirements.
How would you test your approach in production?
Deploy an A/B test where a subset of live traffic uses the enhanced fraud model with embeddings, and another subset uses the baseline model. Measure fraud detection rates, false positives, and customer experience metrics (e.g., friction in checkout). Track real-time cost savings from fewer chargebacks or fraudulent orders. Roll out widely if you observe consistent gains.
What if real-time scoring is required?
Implement real-time feature extraction and embedding generation. Cache partial user sequences. Update embeddings as new actions occur. Use an online version of your sequence model if feasible. For a quick solution, generate approximate embeddings on the fly from the most recent sessions. Optimize your pipeline with fast vector lookups, incremental sequence updates, and parallel inference engines.
How could you expand beyond fraud detection?
Apply embeddings to personalization, churn prediction, or category-level recommendation. Retain the same self-supervised backbone but adjust fine-tuning for each specific task. Monitor data drift, train separate downstream heads, and optimize metrics relevant to each use case. Keep the embeddings pipeline modular to accommodate multiple tasks.
How would you handle data privacy and security in this pipeline?
Store session logs in secure storage with restricted access. Use encryption for data at rest and in transit. Mask sensitive user details before training. Apply role-based access controls for those who run the pipeline. Log all data retrieval events. Comply with privacy regulations by anonymizing personal data and retaining only what is needed for fraud detection modeling.