
ML Case-study Interview Question: Measuring Generative AI's Impact on Developer Productivity and Code Quality


Browse all the ML Case-Studies here.
Case-Study question
A technology company with a large engineering team introduced Generative AI-based code generation tools to boost developer productivity. They integrated these tools into everyday development tasks, including writing unit tests, automating routine data gathering, pruning redundant code assets, and speeding up urgent production fixes. They also tried using AI-assisted code review to catch fundamental coding issues and improve documentation. They now want to measure the impact on their overall development lifecycle. Outline the complete solution strategy to adopt these AI tools at scale, ensure good code quality, measure productivity gains, and refine or expand the usage of these tools.
Proposed Detailed Solution
Adoption begins with familiarizing developers with prompting best practices. Internal sessions help them use prompts effectively and blend AI-generated code with manual coding. Some teams saw a 60–70% reduction in time spent on unit tests, while others built quick scripts to handle production fixes in minutes instead of hours. AI-assisted code reviews highlighted potential errors, improved exception handling, and suggested better documentation.
In-depth tracking involves capturing metrics like lines_of_code_suggested, lines_of_code_accepted, time_saved_per_story, and code_quality_issues_prevented. The company can compute acceptance ratio by comparing lines accepted from AI suggestions to the total lines suggested.
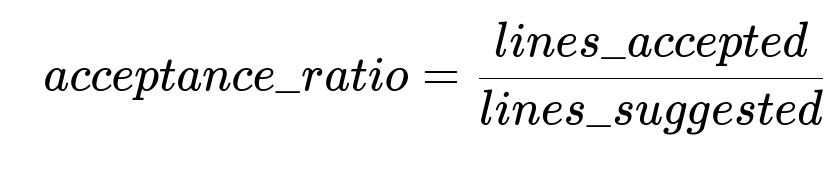
lines_accepted refers to how many lines of the AI-generated suggestions remain after manual edits. lines_suggested denotes total lines proposed by the AI tools. A similar approach can measure total code contributed by AI for each pull request. Further context awareness is crucial to ensure the AI has enough repository knowledge to produce relevant code. Integrating GPT-4 or similar models enables advanced code review and style enforcement.
Teams handled code quality concerns through manual reviews, small-scale PR checks, and eventually an AI-based automated PR checker. For routine tasks such as building weekly review decks, the AI pulls data from multiple dashboards, saving developer time. For code simplification, a script generated by AI identified and removed unused media assets, reducing the application size.
Clear guidelines are necessary for confidential code segments to avoid exposing them to external tools. For measuring effectiveness, the team can track how many lines come from AI suggestions and how many errors or security issues show up in subsequent static analysis. Over time, they can refine AI prompts and store frequent use cases in a knowledge base.
Measuring code quality can involve standard coverage tools or automated test suites combined with the overall acceptance ratio. Integration into the continuous integration and continuous deployment (CI/CD) pipeline allows real-time monitoring. A large-scale approach includes these building blocks: developer training, usage analytics, iterative improvements in model capabilities, and robust oversight in production environments.
Development of new scripts or utilities is faster with AI suggestions. Engineers only intervene when the generated code fails edge cases or conflicts with domain-specific logic. The net effect is time savings, fewer errors, and a more efficient development pipeline.
How would you measure the real effectiveness of these AI code generation tools in a production environment?
The best approach is an automated measurement framework. One method tracks each suggestion from the AI engine as it appears in the integrated development environment (IDE), then logs whether the developer accepts it, modifies it, or discards it. That data rolls up into an overall acceptance_ratio. Compare average time spent on writing a specific feature or test before and after introducing the AI tool.
Another method ties AI usage to code quality via standard gating checks. If test coverage remains high or even improves while time to deliver features goes down, the tool is likely effective. Large acceptance ratios alone do not guarantee quality. Combine acceptance ratio, bug density, and coverage changes for a more accurate picture.
How would you address concerns about the quality of AI-generated code or potential security issues?
Segregate AI-generated code segments into a dedicated branch for additional scrutiny, then run them through static analysis and dynamic security tests. Keep confidential code in an offline environment or use self-hosted models if privacy is paramount. Also have short-lifecycle manual reviews of new code from AI. If code consistently passes the automated checks and code reviews, the risk drops significantly.
Provide a fallback review process that flags any suspicious constructs for a deeper manual inspection. Over time, gather known issues to tune the AI model or refine the prompts. Maintain an internal style guide with security guidelines, then have a separate GPT-4-based checker enforce those guidelines on each commit.
How can the AI-assisted code reviews be integrated with the existing pull request workflow?
Include an AI-based reviewer as one of the checks. When a developer opens a pull request, the system automatically runs an AI code review that examines the diffs, identifies possible errors, and suggests improvements. The developer or reviewer sees these suggestions in the code review UI, then either accepts or rejects them. Over time, monitor how often the AI review’s suggestions are accepted.
If the project demands a rigorous standard, require the AI check to pass with a certain confidence threshold or else the pull request gets flagged for manual attention. The deeper context can come from indexing the repository with embeddings and feeding relevant references to the AI. This integrated loop ensures consistency with coding standards.
What are the next steps in evolving this solution as the project scales?
Focus on deeper integration, expanded coverage, and advanced analytics. For deeper integration, connect your CI/CD pipeline to the AI so it actively checks code style, test coverage, and potential vulnerabilities. For expanded coverage, adapt the AI tools to multiple programming languages or new modules. For advanced analytics, measure correlations between AI acceptance and key metrics like on-time delivery, bug frequency, or code churn.
Store frequently used prompts in a repository so teams can reuse them. Build an internal plugin or extension that supplies the AI model with domain-specific knowledge. Track trend lines over months to see if AI usage stabilizes. If acceptance rates flatten, refine your prompt strategy or upgrade the model. A feedback cycle between developers and the platform team ensures the system remains relevant and valuable.
How would you handle outdated code suggestions if the codebase has shifted significantly?
Set an expiration for generated suggestions if they remain unused for a certain period. Re-run the AI tool to align with the newest code. Tag your code with version identifiers and feed that version context to the AI. If the code changes break older suggestions, discard them or re-evaluate with fresh context. This keeps the suggestions relevant and reduces confusion for developers.
When a major refactoring or redesign occurs, run a migration script and feed the new code structure into the AI as baseline context. This ensures subsequent suggestions reference the updated architecture. Validate the AI’s newly generated code with a targeted test suite built for the refactored modules.
Could you show a simple example of how you might measure acceptance ratio in code?
Yes. Suppose you track code suggestions and acceptance in a database. You log each suggestion as it appears:
# A simple example snippet for measuring acceptance ratio
import time
class CodeGenTracker:
def __init__(self):
self.total_suggestions = 0
self.total_accepted = 0
def log_suggestion(self, suggestion):
self.total_suggestions += 1
def log_acceptance(self, suggestion):
self.total_accepted += 1
def get_acceptance_ratio(self):
if self.total_suggestions == 0:
return 0
return self.total_accepted / self.total_suggestions
def example_usage():
tracker = CodeGenTracker()
# AI offers 3 suggestions, dev accepts 2
tracker.log_suggestion("def foo(): pass")
tracker.log_acceptance("def foo(): pass")
tracker.log_suggestion("def bar(): pass")
tracker.log_acceptance("def bar(): pass")
tracker.log_suggestion("def baz(): pass")
# This one not accepted
acceptance_ratio = tracker.get_acceptance_ratio()
print("Acceptance ratio:", acceptance_ratio)
example_usage()
This logs suggestions and acceptance. If the ratio is consistently high and code health remains good, the tool is adding real value. If the ratio is high but quality issues spike, you must re-check the code generation logic.
What if the tool suggests partial code changes that the developer modifies before accepting?
Treat partial acceptance like a modified suggestion. Either track how many lines remain or let the developer mark the suggestion as “partially accepted.” Then measure partial lines_accepted vs lines_suggested. This provides deeper granularity. You could also prompt the developer to label the reasons for any modifications, e.g., domain logic mismatch, or style changes.
Over time, such logs help refine prompt engineering or guide the model. The team can see patterns where the AI consistently misunderstands domain rules, then supply clarifying context. By capturing partial acceptances, the metrics become more nuanced but still follow the core principle of measuring how much code was AI-driven vs manually created.
How does advanced prompt engineering help in this workflow?
Refining prompts is key. More context or better instructions lead to improved suggestions. For instance, telling the AI about the code structure or giving it a coding style guide yields more accurate code. If your project uses a specific naming convention, embed that detail into the prompt. If domain rules exist, add them too. By systematically iterating these prompts, the AI’s output becomes closer to final code.
In large-scale setups, store your improved prompts in a central repository. For new projects, developers can pick from these prompt templates. This fosters uniform usage and best practices across teams. If prompts become too large, chunk the data into smaller pieces and feed them incrementally. The end goal is to create an environment where the AI code suggestions align closely with your production code standards.