
ML Case-study Interview Question: On-Device Image Captioning using Compressed Models for Automatic Alt Text


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with creating an on-device machine learning system that automatically generates image descriptions to be used as alt text. The system must work locally on user devices to preserve data privacy, limit external resource dependencies, and handle limited computational capacity. The images often appear inside a digital document viewer, and users expect captions to be generated quickly for many types of images. Describe how you would build, deploy, and refine such a system. Suggest a complete end-to-end architecture that manages local inference, model caching, run-time integration, and user validation within a digital document workflow. Assume the system will be used widely on diverse hardware, including laptops and mobile devices.
Detailed solution
Model Selection and Compression
Select a vision encoder and a text decoder with fewer than 200M parameters. Fine-tune them on a labeled dataset such as a large-scale images-to-caption corpus. Use a compressed variant of a well-known decoder to reduce computation and disk footprint. Rely on standard training objectives to align image embeddings with textual output. Replace bigger language decoders with a distilled version to reduce size while preserving performance.
Key Training Objective
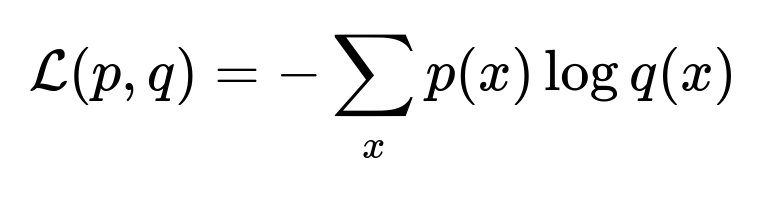
This cross entropy term p(x) represents the true probability of the next token in the sequence, while q(x) is the predicted probability. The training iterates over image-caption pairs to adjust the model weights, improving generated descriptions.
On-Device Inference Integration
Embed a WebAssembly-based inference engine in a separate process. Cache the model weights after the first download to avoid repeated long waits. Deploy runtime and models through a remote configuration service that can be updated independently of the core application. Isolate the inference logic from the main interface, ensuring the rest of the system stays stable if the inference engine fails.
Model Caching Strategy
Store downloaded model files in a local database accessible to the application. Create a simple interface that allows users to remove or update model files if disk space is a concern. Serve the files from your own servers and not from a third-party repository. Keep track of versioned models and switch seamlessly to new ones in the field.
User Validation of Generated Text
Insert alt text proposals into the document workflow. Let users review and edit the generated descriptions. Provide an interface to accept, reject, or modify alt text. Save the final user input for potential data gathering, but only with user consent. Avoid capturing personal images to preserve privacy.
Example Python Snippet
import onnxruntime as ort
import numpy as np
class ImageCaptioner:
def __init__(self, encoder_path, decoder_path):
self.encoder_session = ort.InferenceSession(encoder_path)
self.decoder_session = ort.InferenceSession(decoder_path)
def generate_caption(self, image_pixels):
# Preprocess image_pixels into correct shape
encoder_outputs = self.encoder_session.run(
None, {"input": image_pixels}
)
# Use encoder_outputs to condition the text generation
# Pseudocode to produce tokens from decoder
tokens = [start_token]
for _ in range(max_length):
decoder_input = np.array([tokens], dtype=np.int64)
decoder_output = self.decoder_session.run(
None,
{
"encoder_output": encoder_outputs[0],
"decoder_input_ids": decoder_input
}
)
next_token = np.argmax(decoder_output[0][-1])
if next_token == end_token:
break
tokens.append(next_token)
return self.decode_tokens(tokens)
def decode_tokens(self, tokens):
# Convert token IDs to human-readable text
return " ".join([self.token_to_word(t) for t in tokens])
Privacy and Performance
Keep model inference on the device without sending images or captions to any remote server. Use optimized ONNX runtime or similar to accelerate processing. Use local CPU or GPU if available. Aim for inference latency of a few seconds or less to maintain user satisfaction.
Continuous Improvement
Train refined models with updated data or new techniques. Provide new versions to users when improvements are ready. Capture error scenarios or user feedback if permitted, then incorporate these insights into future training iterations. Update the model in a modular way without changing the entire application.
Possible Follow-Up Questions
1) How do you handle edge cases with unusual images?
Explain how to reduce misclassification of very domain-specific images by adding a fine-tuning step on domain-relevant data. Discuss letting the user override outputs and ignoring the system if the model fails. Present an optional fallback that uses simpler text placeholders for unknown content.
2) How do you prevent sensitive data leakage?
Explain that no images or captions are sent to external servers. Show how to sandbox the inference runtime. Discuss privacy policies and confirm that logs do not store user content. Mention strict local storage encryption. Mention restricting any telemetry to high-level performance data only.
3) How do you handle the computational load on weaker devices?
Explain dynamic quantization or lower-precision representations to reduce CPU requirements. Show how to skip certain layers or use smaller variants of the encoder on less-capable devices. Mention the possibility of accelerating with WebGPU if a local GPU is available.
4) How do you mitigate biases in the model?
Explain thorough dataset review. Highlight the importance of a diverse training corpus. Describe oversight and iterative retraining. Provide the user with the option to correct biased captions. Use metrics to detect repeated patterns that reveal harmful stereotypes.
5) How do you validate or test model performance?
Explain an internal QA pipeline with a curated test set. Show how you measure correctness with standard captioning metrics like BLEU or CIDEr. Mention human evaluation for real-world images. Discuss how to run A/B experiments or user acceptance tests that measure adoption and satisfaction.
6) How do you maintain concurrency and responsiveness in a browser environment?
Explain how to offload model execution to a separate process. Use an asynchronous API that returns partial status updates. Show how to limit memory usage with a streaming approach. Mention that the main UI thread remains free to handle user interactions while inference runs in the background.