
ML Case-study Interview Question: Boosting E-commerce Engagement with Scalable AI-Driven Recommendation Systems


Browse all the ML Case-Studies here.
Case-Study question
You lead a Data Science team in a large technology platform. Your team wants to enhance an AI-driven user recommendation engine for an e-commerce platform that serves millions of daily transactions. You have multiple data streams including user browsing patterns, product metadata, and transactional history. You also have user feedback captured through explicit ratings and implicit signals like cart abandonment or session length. Design and implement a system to improve user engagement and long-term value using these data sources. Describe your approach, the machine learning pipeline, the data engineering architecture, the metrics, and how you would deploy the model in production.
Detailed Solution
Your system can combine large-scale data aggregation, feature engineering, and a model serving pipeline. Start with raw data extraction from clickstreams, product tables, and historical transactions. Create a framework to store data in a scalable data lake or distributed file system. Use data integration jobs to unify logs with user and product metadata.
Train a model on user behavior sequences. Use different features like user demographics, product attributes, time-based usage patterns, and aggregated interaction signals. Build a strong representation of each user profile and each product. Consider a deep learning approach to capture context. For instance, incorporate embeddings for both users and products. These embeddings can represent historical interactions that reflect user preferences.
Some systems optimize with a standard classification or regression approach. If you focus on the probability of user engagement, you can use cross-entropy as your loss function. For example:
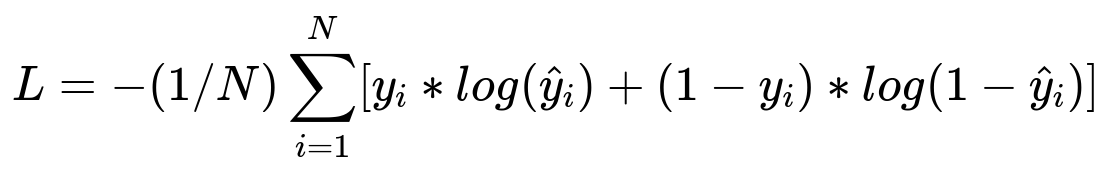
Where N represents the total samples. y_i represents the true label (1 for engagement and 0 otherwise). hat{y}_i represents the predicted probability of engagement. This formula penalizes large deviations from actual behavior.
Experiment with different architectures and hyperparameters to see which approach yields the most stable performance. Use offline validation by splitting data into training and test sets. Also run A/B tests in production. Calibrate confidence intervals, especially if the system influences user purchasing behavior. Track business metrics like average order size, retention rates, and session frequency.
Deploy the model using containerized microservices. Load the trained parameters and host the inference job behind a low-latency service layer. Use techniques like feature caching, approximate nearest neighbor searches for embeddings, and real-time updates to adapt to changing trends. Periodically retrain to mitigate concept drift.
Retrain the model on a rolling basis. Monitor the metrics in real time. Trigger an alert for large performance drops or unexpected shifts in data distribution. Evaluate fairness and bias by exploring model outcomes across demographic segments.
Keep everything documented. Communicate insights with stakeholders. Show how changes in user engagement metrics correlate with the recommendation system’s modifications.
How would you handle feature engineering for categorical variables?
Convert categorical inputs like product category or brand into embeddings or one-hot encodings. For brand or category, consider embeddings that capture semantic relationships. Create a dictionary of unique categories or brand identifiers and map them to numeric indices. During training, the embedding layer learns a dense representation of each category. This representation helps the model capture subtle relationships between categories with fewer parameters than one-hot vectors.
What are potential issues with data leakage?
Data leakage can happen when future information is inadvertently included in the training set. For example, if features include post-purchase signals that reflect outcomes not visible at prediction time. Prevent leakage by strictly separating data chronologically. Ensure that only data up to the prediction point is available. Another issue arises when aggregated features include interactions that occur after the target event. Validate feature sets with timelines. Check whether any aggregated signals are computed with full knowledge of future outcomes.
How do you ensure robust model performance under shifting user behavior?
User preferences shift over time due to trends, promotions, or seasonal patterns. Implement continuous monitoring of key performance indicators. Perform rolling retraining at fixed intervals or upon detecting significant distribution changes. Use strategies like online learning or incremental updates. Examine error distributions for drifting segments. Evaluate if embeddings become stale for new users or newly launched products. Introduce partial fine-tuning if system constraints do not allow full retraining every time.
How would you address cold-start users with minimal history?
Represent the user with limited profile data. Fall back to global popularity trends. Assign average rating or engagement probability for unseen users. Use content-based features such as known demographic or contextual signals like time of day or the user’s region. If partial session data is available, incorporate short-term session-based signals. Gradually refine the user embedding as new interactions accumulate.
What approach would you take to scale the solution for millions of daily users?
Use distributed computing for data preprocessing. Store raw logs in a data lake. Process them with a big data framework. Keep model training scalable using GPU clusters or parameter servers that handle large-scale matrix operations. Host the trained model in containers or serverless endpoints behind an auto-scaling service. Cache frequently requested embeddings in memory. Deploy streaming pipelines that update user embeddings or recent interactions in near real time.
How do you evaluate the recommendation model’s success beyond just CTR?
Track user retention rates, conversion rates, and average revenue per session. Assess long-term user engagement. Examine dwell time or repeat visits. Evaluate coverage metrics, measuring how well the recommender surfaces diverse items. Analyze potential over-specialization by checking how often new products get shown. Conduct user surveys or gather feedback signals to see if recommendations feel relevant and interesting.
How do you detect and mitigate bias in recommendations?
Check if certain demographic groups receive fewer offers. Examine recommendation distributions by demographic segments. If the system systematically under-represents certain product categories for certain groups, adjust the training approach. Consider fairness constraints or re-ranking steps that rebalance results. Validate with a balanced dataset to avoid underfitting or biasing toward the majority class. Communicate these fairness measures clearly.
How do you secure the data pipeline?
Apply encryption and access control on data storage and transfer. Implement role-based permissions and rotating credentials for cluster resources. Anonymize personal information using tokenization or hashing. Restrict direct access to logs. Comply with data governance principles, ensuring user consent and minimal retention policies. Document each step and train the team on security best practices.
How would you handle real-time updates of user behavior?
Include near real-time event streams. Parse new clicks or transactions and update user features quickly. Maintain an incremental inference pipeline that updates predicted probabilities or user embeddings. If you see data distribution shifts, queue a partial model refresh. Carefully plan data ingestion so events come with minimal lag. Confirm that consistent user identifiers enable easy aggregation.
How would you train junior team members for advanced model debugging?
Guide them in setting up thorough validation checks. Teach them to inspect confusion matrices, calibration curves, precision-recall distributions, and partial dependency plots. Show them how to run ablation tests to see which features matter. Encourage them to simulate user behavior with controlled test sets. Let them read logs to confirm data transformations are correct. Collaborate on code reviews. Teach them to ask for metrics that reveal hidden data issues or overfitting signs.
How do you deploy an experiment and measure success?
Use an online experiment framework. Assign a treatment group that sees the new model. Compare with a control group on critical metrics. Watch for significant changes in daily conversions or average session time. Run the experiment for a statistically meaningful period. Compare confidence intervals. If results look promising, roll out more widely. Otherwise, revert to the old system. Keep a thorough record of each experiment for future reference.
How would you integrate business constraints or inventory limits into your recommendations?
Design a re-ranking step. Suppose the model scores items by predicted engagement. Impose constraints on stock quantity or business goals. Adjust final ranking by blending the raw score with constraints. Re-balance if a product is low on stock. Possibly allocate certain impressions for new product launches. The re-ranking step can be dynamic. Evaluate performance trade-offs by measuring if this re-balancing significantly affects user satisfaction or revenue.
How do you manage version control for models?
Tag model artifacts with version numbers or commit hashes. Store them in a model registry or object store with metadata about hyperparameters, training data snapshots, and evaluation metrics. Keep a reliable rollback path. Implement feature store versioning too. Combine the correct feature set version with the matching model. Use container images for reproducible inference environments. Log every change with reasons and performance results.
How do you justify resource allocation for GPU clusters?
Show that training with GPU clusters reduces training time and iteration cycles. Demonstrate that faster experiments generate more insights and accelerate improvements. Provide benchmarks on how CPU-only training would limit your ability to explore deeper architectures or run large-scale hyperparameter searches. Identify cost trade-offs and tie them to business value from accurate recommendations. Present usage statistics to validate that the GPU resources are fully utilized and beneficial to outcomes.