
ML Case-study Interview Question: Boosting Online Marketplace Engagement with Deep Learning Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A large online marketplace observes declining user engagement. Leadership wants a system to personalize user experiences, increase satisfaction, and boost revenue. They have a diverse range of products, large-scale transaction data, and various user interaction metrics. They want a recommendation pipeline that learns from user behavior signals and product features. Engineering constraints include large-scale data processing, near-real-time inference, and frequent model updates. Design this system, outline the core technical components, discuss model selection and evaluation, and propose strategies for continuous improvements.
Proposed Solution
A recommendation solution uses historical user interactions, product metadata, and contextual information. Data is cleaned, enriched with user profiles, and stored in a distributed environment. A scalable data pipeline regularly refreshes features. A machine learning model captures user preferences by combining behavioral signals with item attributes. A deep learning model with user and item embeddings trains on sessions or clickstream data. The pipeline retrains at fixed intervals. An online serving architecture retrieves top recommendations and re-ranks them based on real-time signals. Offline and online metrics measure performance.
Data and Feature Engineering
Data includes session logs, click behavior, purchases, and product features. Systems track each user’s engagement. A distributed data storage holds the raw information. A feature store aggregates these signals. Feature transformations normalize numeric fields, encode categorical fields, and generate new features like recency of interactions. A strict data validation workflow checks for anomalies and missing values. A robust scheduling system retrains models on updated data.
Model Architecture
A supervised model predicts the relevance of a product for a given user. A neural network ingests user embedding, item embedding, and context features. Training uses a ranking loss function to emphasize precision at top ranks. Negative sampling ensures a balanced training set. A softmax or sigmoid output indicates a relevance probability. Large-scale training uses minibatch gradient descent with a learning rate schedule. Regularization techniques like dropout mitigate overfitting.
Representative Formula
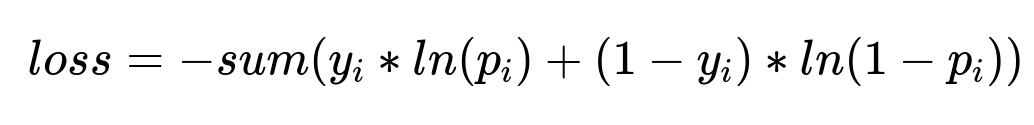
In this expression, y_i is the observed relevance label for item i, and p_i is the model’s predicted probability. Minimizing this loss pushes predictions closer to the observed labels. Regularization terms sometimes add to this loss to reduce overfitting.
Offline Evaluation
A holdout dataset measures metrics such as accuracy, area under the precision-recall curve, or mean average precision. Cross-validation ensures stable estimates. A ranking metric like Normalized Discounted Cumulative Gain prioritizes correct ordering of top results.
Online Serving
A service runs inference on user requests. A real-time feature stream updates context features like recent clicks. The system fetches user embedding from a cache, retrieves candidate items, and re-scores them with the model. The service returns top suggestions. Latency constraints require efficient memory usage and concurrency management.
Deployment
A continuous integration and deployment process manages model versions. Monitoring tracks performance trends and anomaly signals. A canary release tests new models on a subset of traffic before rolling out to all users.
Online A/B Testing
A treatment group sees recommendations from the new model while a control group sees existing recommendations. The key performance indicator is lift in engagement or revenue.
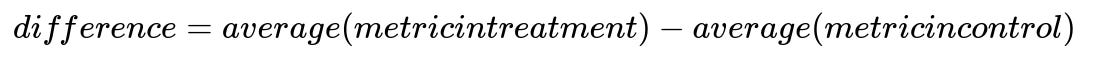
This difference indicates improvement or decline. Statistical tests assess significance. A large enough sample size ensures reliability.
Iteration and Improvements
Frequent retraining keeps pace with changing user behavior. Feature engineering evolves to capture new signals. Hyperparameter tuning refines the model. Embedding vectors update with new interaction data. Periodic re-analysis ensures the system aligns with business goals.
Follow-up Questions
How do you address data distribution shifts if user behavior changes drastically?
Retraining frequency must increase. A drift detection mechanism watches for changes in label distributions, feature statistics, and user segments. A triggered retraining job updates parameters. A model monitoring dashboard tracks real-time performance metrics and compares them to historical baselines. A fallback approach uses earlier stable models if new data is noisy.
How do you ensure the model remains explainable to stakeholders?
A model interpretability tool surfaces feature attributions on sampled predictions. Model behavior is compared against benchmark rules. Partial dependence checks show how single features affect predictions. A simplified model or a shallow tree sometimes approximates the deep network to validate its decisions.
How do you optimize for long-term user satisfaction rather than immediate clicks?
A reward function includes a long-term engagement metric. The training set includes signals like repeat visits or net promoter scores. A reinforcement learning approach refines the recommendation policy. A discount factor emphasizes immediate rewards versus future ones. Careful offline simulation precedes any production deployment to prevent negative user experiences.
How would you handle cold-start scenarios for new users or new items?
A default embedding for new users bootstraps from aggregated behaviors of similar users. The system updates quickly when new interactions arrive. For new products, basic metadata-based embeddings initialize the item vector. Embeddings refine as more clicks or purchases occur. A hybrid approach incorporates content-based features to mitigate sparse interaction issues.
How do you deal with infrastructure scaling for large data volume and high request throughput?
An autoscaling cluster processes incoming data. A distributed computing framework parallelizes feature transformations and model training. A serving layer with load balancing routes user requests to replicated model instances. An optimized retrieval system pre-computes candidate sets. Further scaling uses approximate nearest neighbor searches to handle large item catalogs. The system architecture is tested for failover, ensuring minimal downtime.
How do you mitigate biases in the recommendation system?
A fairness constraint punishes disparate impact across protected groups. A re-ranking algorithm balances utility with fairness goals. A bias-check pipeline audits model outputs. A threshold-based approach ensures distributional parity or equal opportunity. Continual monitoring examines performance across demographics, adjusting thresholds or embeddings if disparities grow.
How do you handle real-time updates vs. batch updates?
A hybrid approach merges frequent batch processing for large-scale data and real-time streaming for immediate events. A streaming pipeline captures signals like recent user clicks, which a caching layer uses for context. The bulk of model weights update in periodic batch jobs. This division optimizes cost, complexity, and timeliness of updates.
How do you evaluate the reliability of your model predictions?
Confidence intervals around performance metrics gauge stability. Bootstrapping or jackknife methods compute variance estimates. A robust validation strategy repeats training and validation on multiple data splits. Confidence scores for each prediction help rank items more cautiously where the model is uncertain. This builds trust with stakeholders and reduces unsatisfactory recommendations.
How do you fine-tune hyperparameters for the deep learning model?
A random search or Bayesian optimization approach finds promising parameter sets. A small validation set measures each trial’s performance. Key hyperparameters include learning rate, embedding dimension, number of hidden layers, and dropout rate. Automatic scheduling or a hardware accelerator speeds up this search. Early stopping prevents overfitting.
How do you confirm the improvement in user experience is real and sustainable?
Engagement and revenue metrics tracked over weeks confirm sustained gains. Retention-based metrics or funnel analysis provides clarity on user satisfaction. Surveys or user feedback channels offer qualitative insights. A holdout group remains on older recommendations for extended time, enabling stable comparisons. A difference-in-differences analysis checks long-term shifts in behavior.
How do you handle requests for interpretability from non-technical leadership?
An interactive dashboard presents model outputs for specific scenarios. A visual breakdown highlights feature contributions. Example-based explanations illustrate how different inputs lead to distinct recommendations. Monthly updates to leadership clarify improvements in metrics, reasons for model decisions, and upcoming enhancements to reduce confusion and build trust.