
ML Case-study Interview Question: Extracting and Ranking Real Estate Features Locally Using BERT NER


Browse all the ML Case-Studies here.
Case-Study question
A large online real-estate platform wants to improve its home search experience by highlighting unique features and attributes found in property listings. They have millions of unstructured text descriptions and want a system to extract key phrases that resonate with home seekers in different regions. They also want to filter out ambiguous phrases and prioritize trending tags in specific areas. How would you architect this pipeline from end to end, including any machine learning methods, data processing steps, and ranking approaches?
Proposed Solution
Fine-tuning a BERT model for named entity recognition (NER) helps find relevant phrases from property descriptions. The pipeline has three major parts: keyword extraction, filtering, and ranking based on user search patterns.
Keyword Extraction Using BERT
A BERT-based NER model classifies each token into “entity” or “non-entity.” Each token is embedded, passed through BERT’s transformer layers, and then fed into a classifier to predict whether the token is part of a phrase like “granite countertops” or “ocean view.” The process uses a cross-entropy loss to train on labeled tokens.
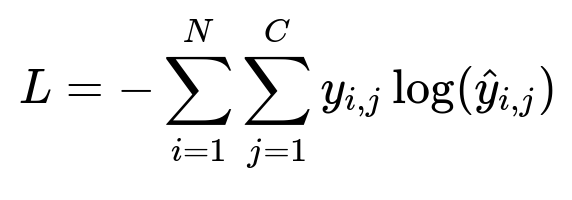
N is the number of tokens. C is the number of classes (entity vs non-entity). y_{i,j} is the ground truth (1 if token i is in class j, else 0). hat{y}_{i,j} is the model’s predicted probability. Minimizing L trains the model to assign higher probability to correct entity labels.
A sample Python training snippet:
model = BertForTokenClassification.from_pretrained("bert-base-uncased", num_labels=2)
optimizer = AdamW(model.parameters(), lr=2e-5)
for epoch in range(num_epochs):
model.train()
for batch in dataloader:
input_ids, attention_masks, labels = batch
outputs = model(input_ids=input_ids, attention_mask=attention_masks, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
Filtering Extracted Phrases
Extracted phrases sometimes include incomplete terms or require contextual references like “minutes to” or “other lots.” The pipeline checks part-of-speech tags to remove tags ending in prepositions or pronouns. It also checks a list of terms known to be too vague or too short for display.
Ranking by Trending Searches
Many insights remain after filtering. A region-aware ranking algorithm picks the phrases that align with local search trends. The model analyzes search traffic signals for terms in each area (for instance, “beachfront” might be more common in coastal regions) and reorders the extracted phrases by popularity. Higher traffic signals elevate the importance of related keywords. The output is a final set of top tags per listing.
Personalization and Future Steps
Personalized recommendations would re-rank the tags based on user histories or explicit preferences. Implementing a user-specific model would combine aggregated regional traffic data with an individual’s browsing patterns. This could involve a neural re-ranking layer that assigns weights to user behavior features like saved homes or previously clicked tags.
How would you handle overlapping or nested entities in property descriptions?
NER often produces overlapping phrases like “new renovated kitchen” and “renovated kitchen.” A common approach uses a conditional random field (CRF) or a constrained decoding step on top of BERT outputs. CRF ensures that the model learns valid transitions between tag boundaries. Another approach is to pick the longer span if two spans overlap and share the same start or end token. Careful data labeling is necessary so that the final system prioritizes the phrase that best matches user queries.
How would you ensure domain adaptation to real-estate text, given that BERT was originally trained on general corpora?
Collect a domain-specific corpus of real-estate text, such as property listings and agent notes. Fine-tune BERT on masked language modeling using this specialized corpus. This step aligns the embeddings with real-estate jargon. The next phase is supervised fine-tuning for NER with ground-truth tags. Monitoring metrics like F1 score on a domain-specific validation set ensures the model learns relevant domain language patterns.
How would you extend the ranking model to incorporate user feedback signals (clicks, saves, ignoring tags, etc.)?
Train a separate re-ranking module that learns from user engagement metrics tied to displayed tags. The input is the set of filtered tags, and the output is a score that indicates how relevant each tag is for a given user. Features could include user profile vectors, session-level context, and global popularity. A neural ranking model or gradient-boosted decision trees can optimize a loss function such as mean squared error on user engagement. The pipeline passes the top-k tags from the initial region-based ranking into this second stage. The final output reorders tags with the user in mind.
How would you handle phrases that require morphological normalization or synonyms?
Lemmatization or synonym expansion helps unify phrases that refer to the same attribute. For instance, “near the sea,” “close to beach,” or “beachfront” might all reflect a waterfront theme. A custom synonym dictionary or word embedding similarity measure can cluster these terms. The pipeline replaces each variant with a canonical representative. This step can happen at multiple points: during training data creation (to unify tags for the same entity) or post-extraction (to group extracted tags for ranking).
How would you scale this pipeline for millions of listings with near real-time refresh?
Parallelize the BERT-based NER on distributed GPUs. Use a streaming architecture (e.g., Apache Kafka) to handle incoming listings. The filtering module is stateless and can scale horizontally. The ranking model can leverage a real-time feature store with region-level popularity metrics updated regularly. Caching partial results for repeated or highly similar text reduces redundant computations. A load balancer spreads the requests across multiple identical pipeline replicas, ensuring quick turnaround time for new or updated listings.
How would you measure success and evaluate model performance?
Measuring click-through rate or user engagement on displayed tags is a practical business metric. A/B testing can compare the new pipeline’s impact against a baseline that shows no tags or random tags. Model-level evaluation uses precision, recall, and F1 on an annotated validation set of property descriptions. Ranking evaluation uses discounted cumulative gain on a set of “desired tags” for each listing and region. Combining offline metrics with live tests ensures the pipeline meets both technical and real-world business requirements.