
ML Case-study Interview Question: Optimizing Flight Price Notifications with Random Forest Predictions


Browse all the ML Case-Studies here.
Case-Study question
You work at a travel-focused e-commerce company that helps customers monitor and track flight prices over time. The team introduced a “price alerts” feature where a traveler subscribes to a specific route and receives notifications when fares change. Initially, static business rules triggered notifications. They noticed many alerts did not lead to user engagement, causing high alert costs and clutter. The team decided to apply machine learning to decide if a notification should be sent. They wanted to boost user engagement with these alerts while limiting unnecessary notifications. Their ML system used historical traveler interactions, subscription details, and price deltas to predict whether a traveler would open a notification. They ran Random Forest models, did hyperparameter tuning, and built fallback thresholds ensuring everyone got at least one notification. They tracked increased user engagement, improved bookings, and a high recall in identifying travelers who would open notifications. How would you approach designing, building, and refining this system?
Detailed Solution
High-Level Approach
Break down the problem into smaller tasks. First, define the primary goal: predict the probability that a user will open a price alert notification. This becomes a binary classification problem. Label direct opens as the positive class. Use relevant features, such as travel route, historical open rate, and subscription age.
Data Preparation
Retrieve travel route metadata, subscription timestamps, historical opens, flight price deltas, and user traits (like the number of concurrent subscriptions). Combine and clean this data. Convert categorical features to numeric form. Check for class imbalance since opens might be fewer than non-opens.
Model Selection
Choose a simple yet robust model (Random Forest) for baseline. Each tree votes on the classification result. The final prediction is the majority vote of all trees.
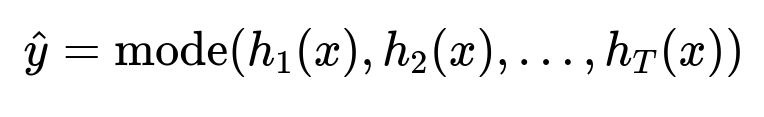
Here, h_i(x) is the prediction from tree i, and x is the feature vector (e.g., route, historical open rate, subscription information, flight price delta). T is the number of trees in the forest.
Random Forest provides interpretability via feature importance and handles varied data types well.
Training and Hyperparameter Tuning
Split data into training and validation sets. Fit the random forest classifier. Tune hyperparameters with a systematic search procedure. Example code snippet:
model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
# Insert code to set up hyperparameter search.
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
Use a tool or library that searches hyperparameter space more efficiently (e.g., Bayesian optimization). Track the best hyperparameters. Evaluate the F1 score, recall, and any business metric that captures the cost of sending unnecessary alerts vs. the benefit of sending successful alerts.
Key Safeguards
Send at least one notification after a specific time window if the model keeps predicting low open probability. Set a price-change threshold to trigger an alert for relevant big fare drops.
Metrics
Focus on recall to capture users who would open notifications. Maintain a watch on open rates, number of subscribers receiving alerts, and retention (fewer unsubscribes). Monitor booking conversions as a downstream metric.
Implementation Details
Use an automated pipeline that runs daily. Load new subscriptions and updated flight price data. For each subscription, calculate the probability of an open. Send a notification if it crosses the threshold or meets safeguard criteria. Track outcomes (opened/not opened). Feed these outcomes into subsequent model training for continuous improvement.
Handling Bias
The primary feature might be past open history. Mitigate by creating fallback rules for new subscribers with limited data. Let them see an alert after some days. Evaluate if biases exist across user segments, like travelers from a particular region.
Final Observations
The system can include an additional model or calibrate probabilities to reduce false negatives. Continuously refresh training data. Monitor performance in real time. Attempt new algorithms like gradient boosting if Random Forest saturates in performance.
Follow-Up Question 1
How would you address class imbalance if the number of notifications opened is much smaller than not opened?
Answer Explanation Balance the classes with undersampling or oversampling. Explore SMOTE or specialized class weights. Adjust classification thresholds post-training. Optimize recall and precision with a precision-recall curve. Evaluate real-world impact to avoid over-sending alerts.
Follow-Up Question 2
How do you prevent overfitting and ensure generalization in production?
Answer Explanation Use cross-validation and a separate holdout set. Regularize with hyperparameters like max_depth or min_samples_leaf in the Random Forest. Limit the number of features if some are redundant. Deploy the model with a shadow test before replacing the old system. Observe metrics over time.
Follow-Up Question 3
What challenges arise when integrating this system with real-time user subscription data and flight price feeds?
Answer Explanation Data freshness is crucial. Price changes daily, and new subscriptions appear constantly. Build batch or near-real-time pipelines that store updates, transform them into model inputs, then predict and trigger notifications reliably. Ensure system stability and handle spikes in data volume.
Follow-Up Question 4
How do you evaluate if your chosen model is the best option versus more complex deep learning methods?
Answer Explanation Compare performance metrics in A/B tests. Deep models might need more data, tuning, and compute. If random forest meets performance, interpretability, and latency requirements, it may be enough. Always weigh complexity vs. gains. Conduct experiments with small user groups to measure open rates, conversions, and system cost.