
ML Case-study Interview Question: Interactive UI for Debugging and Experimenting with Personalized Search Microservice Pipelines


Browse all the ML Case-Studies here.
Case-Study question
A large online retailer deployed a personalized search feature powered by multiple microservices for query parsing, core search, and custom re-ranking. They built a specialized user interface to observe, debug, and iterate on the entire search pipeline. Imagine you are the Senior Data Scientist leading this project. How would you design the system to enable quick root-cause analysis, compare alternative pipeline configurations, investigate user-level anomalies, and perform “what if” experiments to see how different parameters or model components change the final rankings?
Provide a detailed plan for the pipeline architecture, the data flows among microservices, the logging and visualization strategies, and the methods you would implement to test alternative versions of the pipeline. Explain what technologies, metrics, and approaches you would use to ensure your personalized search remains effective, scalable, and easily debuggable in production.
Detailed Solution
Overview of the pipeline
A modular pipeline consists of three main microservices: a query parser, a core search engine, and a personalized re-ranking component. The parser detects relevant attributes or entities from the user's text input. The search engine retrieves candidate items from the inventory. The personalization layer applies user-specific preferences and reorders or filters items.
Observability and debugging approach
A custom interactive UI unifies data from all stages of the pipeline. Logs, metrics, and event traces show how a search query transforms into final results. A flow diagram (Sankey-style) indicates the relative weighting or number of items at each stage. Selecting an item in one view highlights it across the entire interface. Metadata displays help isolate any irregularities in attribute detection, scoring, or item ranking. By linking these visualizations, the UI pinpoints the service responsible for a suspicious outcome.
Key ranking formula
The system balances general relevance with personalization. A typical final score S_final(i, user) might combine a relevance term S_relev(i) and a personalization term S_personal(i, user). One way to show this combination is:
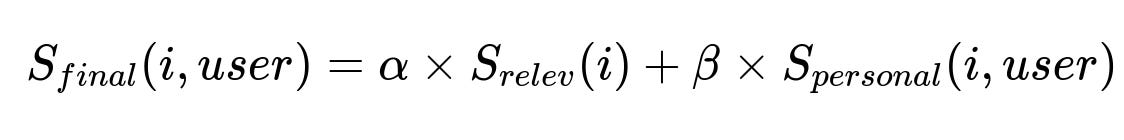
Here, alpha and beta are scalar weights. S_relev(i) is how well item i matches the parsed query. S_personal(i, user) reflects how item i aligns with the user's style history. Adjusting alpha or beta changes the system's emphasis on general query relevance versus personal preference.
Explanation of formula parameters
alpha is a weight that controls how heavily the pipeline emphasizes textual or attribute-based relevance. beta is a weight that controls the impact of the user's prior preferences. S_relev(i) is computed from the core search engine. S_personal(i, user) is derived from the personalization microservice based on the user's historical purchase or engagement data.
Interactive metric analysis
Another component of the UI examines the distributions of metrics (relevance score, personalization score, overall rank, etc.) through visual plots. Each search result is represented, allowing quick comparisons. Outliers in these plots indicate items that deviate in color, category, or assigned weight. The ability to filter specific items clarifies why they might fail to appear in the final results or appear in unexpected positions.
“What if” experiments
A sandbox mode modifies parameters on the fly. The query text, user identity, pipeline configuration, or item attributes can be changed. Engineers and data scientists compare the new results with the baseline. A version-control-like system preserves these configurations for future collaboration. This process reduces guesswork and shortens iteration cycles.
Example code snippet for Sankey visualization
import plotly.graph_objects as go
def create_sankey(links, labels):
fig = go.Figure(data=[go.Sankey(
node=dict(
label=labels
),
link=dict(
source=[lnk['source'] for lnk in links],
target=[lnk['target'] for lnk in links],
value=[lnk['value'] for lnk in links]
)
)])
fig.show()
# This function takes a list of links and their source/target indices,
# plus a list of string labels for the nodes.
# It then renders a Sankey flow diagram illustrating how items or
# subqueries move through the pipeline.
The code reads incoming connections from each microservice and renders them proportionally. Inspecting the flow helps identify where items drop out or gain prominence in the final results.
Follow-up question 1 (Architecture scaling)
How would you scale the pipeline if user requests grow significantly?
The microservices are independently deployable. Each service auto-scales horizontally under load. The query parser scales by splitting incoming requests across containers running language processing models. The core search engine scales through sharded indexing and distributed retrieval. The personalization layer scales by caching user features and distributing the re-ranking logic across multiple nodes. The UI aggregates metrics from services that publish them asynchronously to a centralized data store. Balancing load across these services, combined with a robust event streaming or queueing system, maintains low-latency responses.
Follow-up question 2 (Ensuring data quality and reliability)
How would you prevent data drift and ensure reliability?
Data drift is prevented by monitoring distribution shifts in user queries, item attributes, and personalization features. If the overall text distribution changes significantly, the parser's entity-recognition model might need retraining. The search engine’s index must be updated with the latest inventory data to avoid stale or missing items. The personalization microservice must handle new user behavior patterns promptly. Reliability involves circuit breakers or fallback modes in case one microservice fails. Strict logging at each stage ensures post-hoc analysis of pipeline failures.
Follow-up question 3 (Improving personalization)
How would you incorporate advanced machine learning models into the personalization stage?
A learned model can use embeddings for items and users. The re-ranking microservice calls a model that computes user-item compatibility scores based on these embeddings. The pipeline passes each candidate item to the model for scoring. The final ranking is sorted by S_final(i, user). If using deep neural networks, the system might store embeddings in a vector database for fast similarity lookups. Regular A/B testing compares the new model’s outcomes against a baseline pipeline. The UI can highlight re-ranked items that shift due to the model’s improvements or misclassifications.
Follow-up question 4 (Troubleshooting an unexpected search result)
What steps would you take if users see irrelevant items?
Begin by reproducing the query on the UI. Observe how the parser labeled the query. Confirm that the subqueries match expected attributes. Examine the search engine’s retrieved items to see if weighting or indexing caused mistakes. Check the personalization layer’s score contributions. Compare the final top results against the earlier list from the search engine. Confirm that the pipeline used correct user preference data. If the problem persists, test a different user or a different pipeline configuration to see if the issue is query-specific, user-specific, or systemic. Update the pipeline or retrain the model if the root cause is in the model logic or data distribution.
Follow-up question 5 (Security and access control)
How would you handle role-based access control for the UI?
Restrict read or write access to the pipeline configurations. Engineers or data scientists can experiment, while stakeholders might only view dashboards. Use an authentication layer that integrates with the platform’s identity provider. Logging any user changes to the pipeline helps maintain audit trails. Sensitive data, such as user preferences or personal information, must be masked or anonymized.
Follow-up question 6 (Collaboration across teams)
How would you align product managers, designers, engineers, and data scientists while maintaining observability?
Provide a shared UI that visualizes the entire pipeline’s transformations. Implement easy sharing of configurations through URL-encoding or a lightweight database. Encourage a common vocabulary around subqueries, metrics, and ranking. Store the results of test scenarios so that each team member sees consistent data. Establish feedback loops where product managers verify user experience concerns, engineers fix bugs, and data scientists refine models. Centralized logging and metric dashboards ensure teams spot anomalies early.
Follow-up question 7 (Maintaining flexibility)
How would you keep the pipeline composable for future changes?
Design each microservice with clear contracts on input and output formats. Place minimal assumptions on how they handle internal logic. Maintain well-documented APIs for extending or swapping any module. Keep feature engineering flexible so new or updated signals can be added without breaking the pipeline. Encourage experimentation with multiple versions of the query parser, the ranking logic, or the personalization component by adjusting them in the UI’s “what if” mode. Continue capturing metrics at each step in a uniform way to preserve consistent debugging.
Follow-up question 8 (Versioning and experimentation)
How would you manage experiments with different pipeline configurations?
Use a versioning system where each microservice can be tagged with a specific release. A single route aggregator can route user traffic to a specified pipeline version. Log the pipeline version used for every search request. In the UI, store each pipeline variant so teams can switch between them and observe how the final results change. Provide a consistent schema so that metrics for each version are comparable. This method ensures large-scale online A/B tests can be run while internal teams continue offline experimentation.
Follow-up question 9 (Model interpretability)
How would you expose personalization model interpretability to stakeholders?
Show each item’s personalization scores and attribute-level contributions. Display partial dependencies between user attributes and model outputs. Provide an interactive table listing the top factors influencing the item’s final rank. Offer a togglable view to reveal how changing a single user attribute might move an item up or down the final list. Give product managers an accessible summary without exposing the underlying machine learning complexities.
Follow-up question 10 (Future extensions)
How would you extend this approach to multimodal data or real-time updates?
Add embeddings for images or text extracted from the catalog. Convert user interactions (clicks, dwell times, purchases) into signals that update personalization models in near real time. Insert a streaming layer that triggers partial index updates. Maintain a queue that logs user events, then incrementally retrains or updates relevant model components. The UI can highlight newly available items or changing user preferences as soon as they are processed.
All these strategies ensure the system remains robust, interpretable, and consistently optimized for user needs.