
ML Case-study Interview Question: Optimizing Multi-Product Campaign Assignment with Uplift Modeling


Browse all the ML Case-Studies here.
Case-Study question
A growing consumer-facing platform offers multiple financial products. Different product teams want to reach overlapping user segments with marketing campaigns. Marketing frequency is restricted by internal policies to prevent messaging fatigue. The business wants to decide which user should receive which product’s campaign, in a data-driven way, to maximize total uplift while respecting constraints around user experience and strategic product goals. You have historic A/B test data for each product, user attributes, and post-campaign outcomes. How would you design an approach to assign each user the most relevant campaign and measure the resulting impact?
Detailed Solution
Overview
Each product campaign seeks to influence user behavior: for instance, opening a savings plan or subscribing to a premium tier. Uplift modeling helps estimate how a user’s behavior changes if they receive a campaign (treatment) versus not receiving it (control). Multiple products complicate the situation because deciding which campaign to send requires comparing potential uplifts across products, then choosing the best overall assignment. Controlled experiments are crucial to measure the actual incremental benefit.
Uplift Modeling Concepts
Uplift modeling estimates additional user response due to an intervention. Consider a binary outcome (e.g., user subscribes or not), or a continuous outcome (e.g., total savings). For each user x, let f_treatment(x) predict the user’s outcome if they receive the campaign, and f_control(x) predict it if they do not. The core uplift formula is:
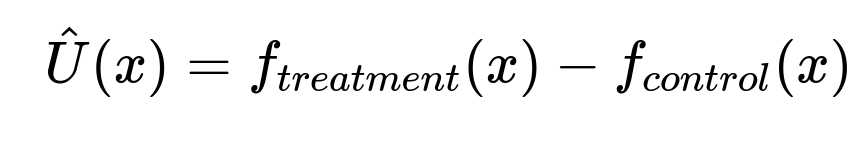
Where f_treatment(x) and f_control(x) are predictions from separate or combined models. A typical approach uses:
T meta-model: Train one model on treatment data, another on control data.
S meta-model: Train a single model that includes a variable indicating treatment or control.
Building the Models
Data comes from past A/B tests for each product. Include users who received the campaign (treatment) and those who did not (control). Extract features that predict product usage. Label each user with the outcome of interest (e.g., subscription). Split data for training and validation. For a T meta-model:
Train a model on the treatment subset to predict the outcome.
Train another model on the control subset.
For a new user x, compute f_treatment(x) and f_control(x) and subtract to get uplift.
For an S meta-model, train a single model with a binary feature indicating treatment group. Predict outcomes with that feature set to 1 (treatment) and 0 (control) for the same user to get the difference.
A sample Python snippet using the CausalML library could look like this:
from causalml.inference.meta import BaseTClassifier
from sklearn.ensemble import RandomForestClassifier
# Suppose X is your feature matrix, treatment is a list of 0/1 flags,
# and y is the outcome (0/1)
t_model = BaseTClassifier(learner=RandomForestClassifier(n_estimators=100))
t_model.fit(X=X, treatment=treatment, y=y)
# Predict uplift
uplift_scores = t_model.predict_uplift(X)
Models for each product require relevant response data (for instance, total savings or subscription flag).
Multi-Objective Optimization
Multiple products each have their own uplift model. Each model’s outcome metric can be binary or continuous. When deciding which single campaign to send a user, compare uplift predictions from each product. If you have two products A and B, define a parameter t to prioritize A over B if (uplift_A) is t times higher than (uplift_B). Adjust t to control the relative importance of campaigns. Large t favors sending product A’s campaign, while small t does the opposite.
You can simulate the final results by varying t and estimating how many users receive each product’s campaign. Pick the t that balances business requirements for each product (like minimum volume of signups or revenue objectives) while maximizing total uplift.
Controlled Experiment
Implement your optimization algorithm, then randomly split your users into:
Treatment (Random): Users receive campaigns randomly chosen among products.
Treatment (Optimized): Users are assigned campaigns via the uplift-based optimization.
Control: Users receive no campaign.
Observe the outcomes to measure how much more effective the optimized assignment is compared to random or no messaging. Use the control group to confirm the incremental gains truly come from campaigns, not external factors. Periodically retrain or refresh the model as new user behaviors or additional campaign data become available.
What could be asked next
How would you handle cold-start products with no historical A/B tests?
Use proxies or related product test data. Temporarily deploy a small randomized trial for the new product to gather initial data. Extend existing models with domain knowledge or user similarity methods.
How do you address the risk that T meta-models might overfit?
Use cross-validation on treatment and control sets separately. Limit model complexity or apply feature selection. Monitor performance metrics (like Qini or uplift curves) on holdout data. Consider S meta-model or variant methods (X-learner, R-learner) if overfitting persists.
How would you implement multi-objective optimization for more than two products?
Combine each product’s predicted uplift with a weight or threshold vector. If product i’s uplift is U_i, compare U_i with U_j for j != i. For user x, assign the product i that satisfies U_i >= t_i * U_j for all j, or use linear/convex optimization if you must satisfy constraints at a global level.
How do you maintain model performance over time?
Monitor key metrics (accuracy, uplift at different probability thresholds) after each campaign. Re-run the A/B test approach periodically to validate current uplift assumptions. Track concept drift if user behavior changes significantly, and retrain models when performance degrades.
Could the S meta-model ignore the treatment variable if the effect is subtle?
Yes, if the model fails to capture small differences. Address this by careful tuning, feature engineering, or using advanced methods like transformation-based uplift learners. Ensure your training set has enough samples and balanced treatment/control for robust detection.
Why is the control group essential?
It provides a baseline for measuring true incremental effect. Without it, you cannot confirm if observed behaviors are due to the campaign or external factors. The control group also helps keep uplift estimates accurate for ongoing model refinement.
How do you manage user fatigue constraints?
Set rules for maximum message frequency within a time window. Embed these constraints in your assignment code by checking how recently a user received another campaign. If they reached the limit, skip or queue further campaigns.
How do you handle multiple segments that have different responses to different products?
Segment the population by key traits (e.g., user’s financial profile). Train specialized uplift models or apply hierarchical modeling, letting each segment have distinct parameters. The assignment logic then picks campaigns based on segment-specific uplift estimates.