
ML Case-study Interview Question: Semantic Podcast Search using Dense Retrieval and Transformer Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A platform that hosts a large catalog of audio episodes wants to improve its keyword-based podcast search capabilities. They have many user queries that do not match podcast titles or descriptions verbatim. The company wants a system that retrieves relevant episodes even when the user query phrases do not appear exactly in the metadata. You are the Senior Data Scientist tasked with designing a solution. How would you build and deploy a Natural Language Search system that addresses this issue?
Detailed In-Depth Solution
Semantic search solves the gap between user queries and matching podcast episode metadata. The core idea is to learn vector representations of queries and podcast episodes in a shared embedding space. Queries that are semantically close to an episode's content should have high similarity. This approach is called Dense Retrieval.
Choosing a Transformer Model
Transformers like BERT often produce contextual word embeddings but not always high-quality sentence embeddings. A better approach uses a pre-trained model specifically designed for sentence embeddings and multilingual support. This choice enables more generalized representations across different languages. Fine-tuning this model on the platform’s search data aligns it with the retrieval task.
Training Data Preparation
Historical search logs are examined. Queries that led to a successful click on an episode become (query, episode) positive pairs. Queries that initially failed but were reformulated by the user to eventually find relevant episodes are also included. This captures cases where the user’s query text did not match any of the episode metadata terms exactly. Synthetic queries are generated from popular episodes by training a text generation model on a large question-answer dataset, then feeding the episode metadata to produce (synthetic_query, episode) pairs. A small curated set of semantic queries and corresponding episodes is used only for final evaluation.
Fine-Tuning with a Siamese Bi-Encoder
A bi-encoder architecture uses the same Transformer network for queries and episodes. Cosine similarity measures how close a query vector is to an episode vector. The network is fine-tuned to increase similarity for positive pairs and reduce it for negative pairs.
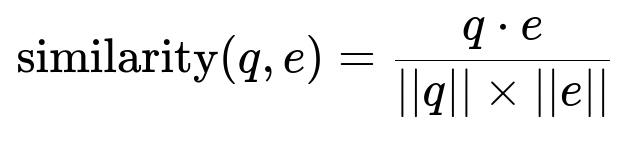
Here q is the embedding of a query, and e is the embedding of an episode. The dot operation is the vector dot product. The norm ||q|| is the magnitude of q, and ||e|| is the magnitude of e.
Generating Negatives In-Batch
Only having positive pairs from logs is not enough. In-batch negatives address this. A batch of size B has B positive pairs. Each query in the batch treats the other B-1 episodes as negatives. The training loop encodes queries and episodes once, constructs a cosine similarity matrix, and optimizes to make each diagonal entry (the correct match) higher than the off-diagonal ones.
Offline Indexing for Retrieval
Episode embeddings are computed offline by running the episode encoder on the metadata fields (title, description, etc.). These vectors are stored in a search engine that supports Approximate Nearest Neighbor (ANN). ANN handles fast retrieval of the top-k relevant episodes given a query vector, even when the index contains tens of millions of items. A first-phase ranking occurs inside the search engine to re-rank the top candidates based on additional signals like popularity.
Online Query Encoding
A user’s search query is passed through the query encoder at request time. The resulting vector is sent to the search engine, which uses ANN to return top matching episodes from the vector index. The system may cache repeated queries to reduce encoding costs. Deploying large Transformer models on GPUs often yields lower inference costs at scale compared to CPU-based hosting.
Multi-Source Retrieval
Exact term matching is still valuable for precision. Combining exact matches and dense retrieval outputs works better than relying solely on dense retrieval. A final-stage re-ranker merges candidates from both methods, using the cosine similarity value and other signals for re-ranking.
Example Python Snippet
import torch
from transformers import AutoTokenizer, AutoModel
import numpy as np
model_name = "my_pretrained_multilingual_model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
def encode_text(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
# Mean-pool the token embeddings
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings[0].cpu().numpy()
query = "electric cars climate impact"
query_vector = encode_text(query)
# query_vector can now be used for ANN search
How would you handle the multilingual aspect and ensure coverage across multiple languages?
Multilingual training data is essential. The chosen pre-trained model has multilingual support, but it still needs fine-tuning on multilingual queries and episode metadata. This requires collecting queries and descriptions in various languages. After training, the system uses the same encoder to handle any language. Proper evaluation for each language partition helps detect gaps. If certain languages are underrepresented, synthetic data generation or manual translations can fill those gaps.
How do you manage negative sampling at large scale?
Generating negatives by random sampling is fast but may not be challenging enough for the model. Hard negatives, which are near-duplicates or episodes with overlapping text, push the model to learn finer distinctions. In-batch negatives are efficient because you only need a batch of positive pairs to produce many negative pairs. Another strategy is to retrieve top matches from an untrained or partially trained model for each query, then label them as negatives if they do not match the correct episode.
Why keep existing term-based retrieval when the new approach outperforms it in some cases?
Dense retrieval can miss exact keyword matches. Some queries are more literal, and standard term-based methods can catch certain edge cases. Term-based retrieval also scales well in some scenarios. Combining both produces more robust results, which a final-stage re-ranker then optimizes based on semantic relevance, keyword overlap, and user engagement signals.
What if the model incorrectly returns irrelevant episodes?
A final-stage re-ranker corrects many mistakes from the initial retrieval. Offline evaluation with curated datasets ensures the system filters out major errors. Online A/B testing tracks performance metrics like click-through rates and listens per search. Monitoring helps retrain or adjust the model. Interpretable signals, such as matching keywords or user feedback, can reduce irrelevant results.
How do you evaluate success before final deployment?
One approach is to partition historical queries into train and test sets with no overlap in episodes. Standard retrieval metrics like Recall@30 and MRR@30 measure how well the approach brings relevant episodes into the top results. A curated set of difficult, semantically phrased queries is tested in a full-retrieval setting. Then an A/B experiment is run for a percentage of real traffic to confirm if overall user engagement improves.