
ML Case-study Interview Question: Improving Ride Acceptance Rates with Predictive Scoring and Continuous Experimentation.


Case-Study question
A leading transportation marketplace wants to reduce the mismatch between passenger requests and driver availability. They discovered that many rides on the platform had a high likelihood of being rejected by drivers. They built a scoring model to decide whether to display each listed ride option to potential passengers. The platform also tested multiple strategies to adjust how many low-probability rides were hidden, aiming to increase global acceptance rates and total bookings.
Propose a step-by-step solution strategy for this case. Describe how you would:
Justify that hiding certain ride options would not reduce total bookings.
Run an initial experiment and measure its business impact.
Move from a single experiment to a continuous monitoring approach.
Handle data drift, keep the model updated, and prove its ongoing value to stakeholders.
Explain your approach, including assumptions, data requirements, experimental design, monitoring, and how you would scale it from proof of concept to full production deployment.
Detailed Solution
Idea Validation and Initial Experiment
Train a simple model using historical data capturing when drivers accept or reject ride requests. Score each potential request based on acceptance probability. Hide low-score rides for a test group of users while a control group sees all rides. Compare acceptance rates and overall bookings. Show that fewer rides displayed to passengers does not reduce total bookings, but actually boosts successful matches.
Continuous Probing Setup
Split users into distinct groups:
A control group that sees all rides (critical for benchmarking and retraining).
Several treatment groups each hiding a different percentage of low-score rides (for instance 20%, 30%, 40%).
Observe acceptance rates, total seat bookings, and other metrics to identify which hide-percentage performs best. Rotate allocations based on performance to adapt to shifts in marketplace behavior. Keep a small control group active at all times so the model can be retrained with fresh data, including low-score examples that were hidden for others.
Retraining and Data Freshness
Monitor drift by comparing offline predictions with observed acceptance on the control group. If performance degrades, retrain using the latest data. Update the model in production following rigorous validation. Automate the data processing pipeline to ensure timely retraining without manual intervention.
Stakeholder Reporting
Develop dashboards showing daily acceptance rates, seat bookings, and changes in driver or passenger activity. Present these findings to leadership. Reveal how adjusting the hidden-percentage of low-score rides improves acceptance. Incorporate feedback from product and business teams, such as concerns around edge cases (e.g., rural routes that rely heavily on boosted segments). Integrate those insights as additional features.
Example Core Formula
When analyzing acceptance trends, measure the acceptance rate with the following expression:
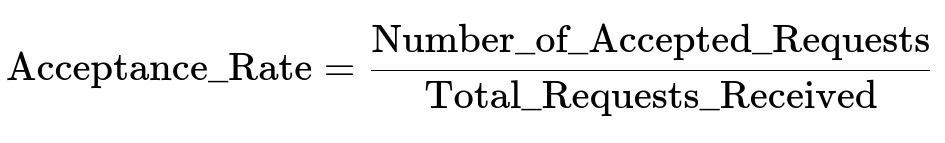
Acceptance_Rate indicates the ratio of successful ride confirmations to total requests. It is a primary metric for optimization.
Implementation Example in Python
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Assume df has columns ['features...', 'accepted']
X = df.drop(columns=['accepted'])
y = df['accepted']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
predicted_scores = model.predict_proba(X_test)[:, 1]
# Suppose we define a threshold for low-score rides
low_score_threshold = 0.2
hidden_mask = (predicted_scores < low_score_threshold)
# Evaluate acceptance or booking rates with hidden rides
# ...
This snippet fits a classification model for acceptance prediction. Scores under a threshold are withheld from display. Different thresholds can be tested to see which yields the best acceptance or booking metrics.
How to Handle Follow-up Questions
1) How would you decide on the threshold for hiding rides?
Analyze acceptance or booking metrics at different cutoffs. Compare performance across thresholds in an A/B/C structure. Choose the threshold that optimizes acceptance rate and total bookings. Periodically reevaluate the threshold as market behavior shifts.
2) How do you ensure the model is not biased toward popular routes?
Check if the model systematically hides rides on less popular routes. Add route popularity features. Calibrate the model so it does not penalize rare routes too heavily. Confirm via the control group that acceptance scores for niche areas align with actual driver behavior. If you see mismatches, incorporate adjustments or specialized features for low-traffic routes.
3) How do you handle seasonality or sudden shifts in user demand?
Keep continuous monitoring. Periodically retrain on recent data. If acceptance or booking metrics drop sharply, investigate causes like holidays, new competitor releases, or post-pandemic changes. Adjust the threshold or retraining frequency to capture new trends swiftly.
4) What if the solution initially fails to show improvements in acceptance rate or bookings?
Revisit data assumptions. Check if the features capture correct signals (driver history, route patterns, timing). Verify training labels are correct. Examine whether the threshold approach is too aggressive, possibly hiding too many rides. Tweak thresholds or refine the model architecture.
5) How do you gain stakeholder buy-in for a production rollout?
Demonstrate results from small tests. Showcase stable uplift in acceptance or bookings without harming user experience. Build user stories of improved match quality. Offer transparent dashboards so non-technical teams can monitor changes in real time. Emphasize the control group’s role in mitigating business risk.
6) How might you extend the system to integrate more real-time data?
Leverage streaming frameworks to fetch new ride requests and driver responses in near real time. Maintain a fresh feature store updated hourly or daily. Retrain or fine-tune the model on a rolling basis using new data. Evaluate incremental learning methods if data volume is high.
7) Why is continuous experimentation more effective than a single A/B test?
Single A/B tests only give a snapshot. Long-term changes require ongoing adaptation. Continuous experiments offer rolling feedback on system performance. This helps address changes in user preferences, competition, or macro-events. It also ensures you never lose visibility into hidden-ride outcomes.
8) What are the main risks with this approach?
Possible hidden bias against less frequent routes or certain driver demographics. Potential misalignment if model objectives diverge from user satisfaction. Implementation complexity in maintaining multiple experimental groups. Continuous pipeline reliability issues, like stale data or system downtime. Each risk can be mitigated with careful monitoring, robust data engineering, and domain knowledge embedded into the feature set.
9) How do you see this scaling to a global platform with different usage patterns?
Separate data by region or segment. Track local acceptance distributions. Deploy region-specific thresholds or models if the user base has stark differences in behaviors. Carefully manage the infrastructure for model updates, as each region might have unique data pipelines. Build strong logging, metrics, and retraining capabilities for each locale to ensure consistent performance.
10) What final architecture changes would you propose?
Propose an MLOps pipeline with automated data ingestion, retraining triggers, model versioning, and live monitoring. Build a system that re-allocates user traffic to different hiding tiers. Offer real-time dashboards and alerts when metrics shift beyond normal bounds. Design it to be modular so future predictive improvements can be plugged in easily.
These steps and strategies would address business requirements, ensure robust experimentation, and push the platform toward higher acceptance rates and better user satisfaction.