
ML Case-study Interview Question: Ranking Code Changes with Fine-Tuned LLMs for Faster Incident Diagnosis


Browse all the ML Case-Studies here.
Case-Study question
A large-scale software platform handles thousands of code changes in a monolithic codebase daily. These frequent changes occasionally cause incidents, so the platform’s Site Reliability Engineering team wants to speed up root cause identification. They plan to build an AI-assisted system that retrieves recent code changes relevant to an investigation, then ranks them using a fine-tuned large language model. Design a solution approach for this system, describe the technical components you would use, and explain how you would evaluate its accuracy. Discuss how you would mitigate risks of wrong suggestions from the model. Propose real-world steps for integrating and fine-tuning the model, including data collection, training, and deployment. Outline how you would confirm the model’s suggestions without misleading engineers.
Provide end-to-end details on your design. Propose a retriever method, an LLM-based ranking algorithm, and explain the training pipeline. Include how you would handle extremely large sets of potential code changes. Suggest how to validate low-confidence outputs. Discuss future enhancements like proactive detection before code push. Describe any system components, potential pitfalls, and how to address them.
Detailed Solution
Overall Design
The architecture uses two main components: a retriever that narrows down code changes related to an incident, and a large language model (LLM)-based ranker that surfaces the most likely culprit. The retriever returns a few hundred changes. The ranker consumes these changes plus context about the incident and outputs a top set of likely root causes.
Heuristic-Based Retrieval
This stage uses ownership metadata (e.g., which team or directory owns certain code sections) and a runtime graph of dependencies. It filters out changes irrelevant to the affected subsystem. It prunes thousands of changes down to a smaller subset. This approach quickly reduces the search space without harming recall. It may also rely on time windows (e.g., changes in the last 24 hours) and anomaly detection signals (e.g., changes in the same directory as an impacted system).
LLM Ranking
The next step ranks the retrieved list of code changes. A fine-tuned LLM processes limited inputs at a time due to context window restrictions. The system splits the set of candidate changes into chunks of 20 or fewer items. It prompts the LLM to select the top five changes from each chunk. Results across all chunks are aggregated, and the process continues until only five remain. This is sometimes called ranking through election. The final five changes become the recommended culprits.
Key Formula for LLM-Based Scoring
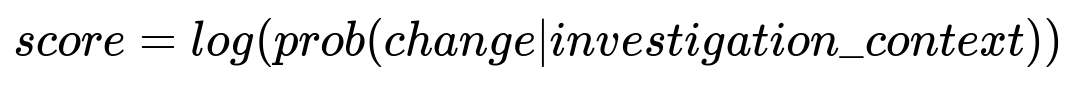
score is the log of the model-assigned probability that a particular change is relevant to the investigation_context describing the incident. Higher score implies greater likelihood that the change caused the incident.
Model Training
A continued pre-training (CPT) phase exposes the base model to the platform’s specific documentation, wikis, and common code patterns. Then a supervised fine-tuning (SFT) stage uses historical incidents with known root causes. Each training example includes partial or minimal information about the investigation (title, impacted systems) plus a set of candidate changes. The known culprit is labeled. This dataset can exceed 5,000 incidents, with each incident containing a range of candidate changes. Fine-tuning teaches the model to generate ranked lists of changes relevant to the incident context.
Combining Scores
After the model produces log probabilities for each candidate, the system ranks them. Another mini fine-tuning pass on similar prompts teaches the model to produce a sorted list. The final re-run of SFT ensures the model’s default output is a list of changes in descending likelihood order.
Risk Mitigation
Wrong suggestions from the model can derail investigators. The system includes:
Confidence thresholds: Low confidence outputs get flagged or omitted, preserving trust at the expense of coverage.
Explainability: The system logs relevant factors (e.g., ownership data, code graph references) so engineers can reproduce or double-check results.
Implementation Example in Python
import numpy as np
def retrieve_candidates(changes, affected_subsystems, code_graph):
relevant = []
for change in changes:
if change['directory_owner'] in affected_subsystems:
relevant.append(change)
else:
# Check runtime dependencies
if any(dep in affected_subsystems for dep in code_graph[change['id']]):
relevant.append(change)
return relevant
def rank_candidates_with_llm(llm_model, investigation_context, candidates):
# Chunk the candidates
chunk_size = 20
top_candidates = candidates[:]
while len(top_candidates) > 5:
new_top = []
for i in range(0, len(top_candidates), chunk_size):
chunk = top_candidates[i:i+chunk_size]
# Prompt the LLM to pick top 5 from this chunk
prompt = build_prompt_for_llm(investigation_context, chunk)
partial_top = llm_model.get_top_five(prompt, chunk)
new_top.extend(partial_top)
top_candidates = consolidate_and_dedupe(new_top)
return top_candidates
def consolidate_and_dedupe(candidate_list):
unique_candidates = []
seen = set()
for c in candidate_list:
if c['id'] not in seen:
seen.add(c['id'])
unique_candidates.append(c)
return unique_candidates
This approach uses a simple chunking method for short LLM prompts and merges results until only five remain.
Handling Very Large Change Sets
When code commits exceed tens of thousands in a short window, the retriever must be more aggressive, leveraging further heuristics:
Limit changes by time gating (only consider changes from the last few hours)
Use error logs or monitoring signals to focus on directories with the highest anomaly rate
Incorporate watchers or tags from the code review system to find suspect code paths
Validation and Measurement
Collect historical incidents with known root causes. Apply the system to each incident’s initial data. Compare the ranker’s top five suggestions against the real culprit. Calculate how often the actual culprit ranks in the top five. This gives a meaningful accuracy metric (e.g., 42%).
Future Enhancements
Proactive detection: Check code changes before merge, run a simulated ranking pass to detect high-risk commits.
Automated tasks: Once the system identifies likely culprits, let it trigger smaller-scale tests or rollbacks.
Tight feedback loops: Encourage investigators to mark false positives or confirm correct suggestions, continually improving training data.
How do you handle extremely low-confidence outputs?
Low-confidence scenarios occur when the model’s log probabilities cluster close together or remain near zero. Provide no definitive recommendation in such cases. Return a short list of potential changes labeled with “Low Confidence” and supply direct references to logs or metrics. Engineers must confirm manually.
How would you adapt the system if code changes break multiple subsystems at once?
Apply domain tagging for each subsystem, then treat each subsystem’s malfunction as a separate but parallel inquiry. The retriever filters candidate changes for each subsystem’s domain. The ranker merges results from all domains and ranks them jointly. If there is an intersection of changes appearing in multiple subsystem results, those changes get boosted in final ranking.
How would you fine-tune the model for a new codebase acquired through a merger?
Gather code patterns and domain-specific documentation from the newly merged codebase. Perform another CPT pass to familiarize the model with new domain data. Add new SFT examples with known incidents from that codebase to help the model rank relevant changes. Keep separate curated samples from legacy data plus new data to ensure the model learns both domains fairly.
How would you maintain explainability for LLM outputs?
Attach metadata to each suggestion. Highlight code owners, lines of code changed, and relevant call graph edges that triggered the suggestion. Store intermediate model prompts to trace how it filtered each set of changes. Publish a short textual reason (“This change modifies core logic used by the impacted subsystem”) for each suggested culprit.
How would you integrate rollback or remediation into this system?
Allow the system to initiate a rollback pipeline if the model’s confidence in a specific culprit crosses a predefined threshold. Follow the principle of gating, requiring human approval before final rollback. This ensures wrong automated rollbacks are avoided while still saving time once the model is sufficiently sure of the root cause.
How do you measure improvement over existing manual processes?
Compare mean time to resolution (MTTR) before and after deploying AI-assisted investigation. Track how often the proposed suggestions match the actual culprit and how quickly engineers confirm them. Gather feedback from investigators on perceived time savings and overall trust in the tool.
How would you address privacy and security concerns in logs or internal documentation used for continued pre-training?
Anonymize or remove sensitive data before feeding it into the model. Mask personally identifying information and secret tokens. Limit access to any training data, plus keep model outputs within a secured system. Apply standard compliance checks and enforce role-based data access.
How would you ensure the model’s suggestions do not become stale?
Frequent updates to the retriever heuristics and periodic re-training keep the system accurate. Introduce a monitoring system that checks for drop-offs in success metrics. When performance deteriorates, schedule a re-training run with fresh incidents.