
ML Case-study Interview Question: Building Scalable Real-Time Image Recognition with Transfer Learning


Browse all the ML Case-Studies here.
Case-Study question
A large on-demand platform has massive incoming image data provided by drivers. The platform wants to build an in-house image recognition pipeline to identify objects or situations in these images. Data is labeled in minimal volumes, so transfer learning is required for fast model building. The pipeline must integrate with existing data sources, process predictions in near real time, and handle privacy requirements. Provide a plan for designing and productionizing this solution and explain how you would ensure scalability, accuracy monitoring, and rapid onboarding of new use cases.
Proposed Solution
A deep neural network pipeline with transfer learning handles classification tasks with limited labeled data. ResNet or a similar backbone model initializes the system. Data augmentation reduces overfitting. A continuous feedback loop feeds daily or real-time data back for retraining, ensuring models remain fresh. A direct integration with internal services enables secure handling of sensitive data. In production, batch or streaming workflows load images, run inference, and produce outputs accessible to downstream systems.
Transfer Learning and Model Architecture
Pre-trained networks such as ResNet provide strong feature extraction. Fine-tuning the final layers with a smaller labeled dataset meets accuracy requirements with minimal training time. The pipeline applies data preprocessing steps, including resizing, normalizing, and augmenting images to improve generalization.
Core Classification Objective
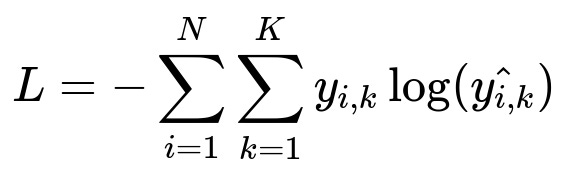
L is the cross-entropy loss. N is the number of training examples. K is the number of classes. y_{i,k} is 1 if image i belongs to class k, else 0. hat{y_{i,k}} is the predicted probability of class k for image i.
Data Pipeline and Production Integration
Daily ETL jobs or real-time services feed raw images to the model. Predictions go into a database for quick consumption. A model tracking dashboard monitors performance metrics like accuracy or precision/recall. Retraining triggers if performance dips below acceptable thresholds or if new labeled data becomes available.
Use Case Onboarding
Teams propose a new use case. Engineers confirm whether the problem requires straightforward image classification and whether labeled images exist. If potential return on investment is substantial, the pipeline trains a pilot model with minimal overhead. Online or offline evaluation drives acceptance criteria. Final integration includes scheduling inference tasks and linking predictions to business services (for example, fraud detection, order assignment logic, or storefront validation).
Example Code Snippet
import torch
import torch.nn as nn
from torchvision import models, transforms
model = models.resnet50(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, num_classes)
# Simple transform example
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
# Fine-tuning logic omitted for brevity
# ...
This code loads a pre-trained ResNet50, replaces the final classification layer with a new layer, and applies simple transforms. Real production code wraps these steps in ETL or streaming jobs.
What steps will you take to handle data privacy and security?
Sensitive images must be removed after short retention periods. Internal data pipelines enforce scheduled deletion. Real-time systems discard personally identifiable details after generating predictions. Images are stored in restricted-access buckets. Role-based authentication ensures only authorized services or teams access the data. Privacy-related transformations, such as cropping or masking sensitive regions, reduce compliance risks if needed.
How do you evaluate whether to use a batch ETL approach or real-time inference?
Batch ETL fits daily or periodic analysis tasks that are not time-critical. Real-time inference is necessary for situations needing immediate results, like fraud detection or order assignment. Resource constraints also matter. Real-time systems incur higher operational costs, while batch processes reduce system load. User experience expectations often decide the approach.
How do you confirm that the model remains accurate over time?
A model monitoring tool regularly checks performance on a validation set. Accuracy, recall, and precision metrics are graphed to spot drifts. Retraining triggers if metrics fall below a threshold. Freshly collected labeled samples improve the dataset. Gradual performance shifts, caused by changes in business patterns, highlight the need for re-annotation or new classes.
How do you extend this solution to new types of tasks like object detection or image segmentation?
The pipeline is flexible enough to swap models. A Faster R-CNN or Mask R-CNN-based approach handles bounding boxes or segmentation masks. Transfer learning still applies. The core logic for data ingestion, augmentation, and output storage remains. The training phase redefines the network heads and relevant loss functions. In production, the new model’s outputs (for instance, bounding box coordinates) integrate with downstream processes that rely on object-level data.
How do you mitigate model bias and ensure fairness?
Diverse training data reflecting real scenarios reduces bias. Annotators provide balanced examples for each class. Model predictions are audited for potential false positives or negatives. If issues appear, additional or re-labeled data addresses skewed distributions. A thorough evaluation on different user populations or geographical regions checks for disparate performance.
How do you handle mismatch between model predictions and manual verifications from support teams?
Enable a feedback channel that reports discrepancies to a labeling team. Newly verified images enrich the training set. This dynamic loop corrects systematic errors and updates the model. Anomalies, like major class confusion, signal deeper root causes (for example, overlapping classes, inconsistent labels) that must be resolved by refining label definitions or training sets.
How would you approach real-time model deployment with minimal downtime?
A canary deployment increments traffic to the new model while preserving the old version for fallback. Container orchestration systems manage multiple replicas. Logs and metrics check if response times and accuracy remain stable. A rollback to the previous version is triggered if anomalies appear. This strategy avoids disruptions for critical use cases.
How would you handle scaling to millions of images per day?
Distributed inference solutions process large volumes. GPU clusters or auto-scaling compute resources handle variable load. Data is sharded across multiple nodes to balance I/O. A message broker or stream processor coordinates ingestion. Infrastructure is monitored for latency or bottlenecks to adapt the cluster size in real time. A caching layer can handle repetitive queries.
How do you test that your model works in real-world conditions rather than just a lab environment?
Staging environments mirror production data flows. Real images from daily operations feed test pipelines. Monitoring logs capture error cases, throughput, and performance. Approximations of real device types, image resolutions, or user-driven conditions confirm that the model handles real-life variations, like poor lighting or partial occlusion. A controlled A/B test in a small region or group verifies robust performance before global rollout.