
ML Case-study Interview Question: Real-Time Machine Learning for High-Recall, High-Precision Transaction Fraud Detection.


Case-Study question
A fast-growing multi-service platform processes millions of transactions daily. Fraudsters exploit loopholes to evade payment. The company previously used a rule-based pre-authorisation system to place a temporary hold on a user's card. They realized that rigid rules were easy to reverse-engineer and often inconvenienced genuine users. The company wants a more adaptive and higher-precision approach with machine learning. How would you build and deploy a real-time solution that minimizes financial loss from fraudulent behavior while maintaining a positive user experience?
Constraints and Requirements
The system must:
Operate in real-time with minimal latency.
Achieve high recall (at least 0.9) to avoid missed fraud cases.
Attain the best possible precision to limit customer dissatisfaction.
Scale across diverse geographies and payment behaviors.
Be maintainable, with easy feature engineering and threshold adjustments.
Detailed Solution
Overview of the ML Approach
Rule-based methods rely on fixed conditions that can become inflexible and predictable. Machine learning models compute probabilities, not binary outputs, so they handle new fraud patterns more adaptively.
Data Preparation
Data relevance is critical. Large volumes of historical records are available, but not all data is helpful or even feasible for real-time. Recent transactions and core features matter more.
Features must be computed in a way that can be refreshed quickly. For instance, a feature might represent the count of certain trip types for a user over the last 7 days. This needs daily aggregation rather than a heavy query at prediction time.
Model Choice
Gradient boosting models (CatBoost, XGBoost, or similar) often perform well on tabular data and handle categorical variables elegantly. Neural networks and anomaly detection models can be explored, but gradient boosting is a simpler path and usually yields strong outcomes.
Training uses time-based validation. A rolling window approach helps ensure the model predicts future fraud while trained on recent periods. This method respects chronological order and prevents data leakage from future events.
Core Formulae for Metrics
Precision and Recall define the trade-offs in fraud detection. The project has a recall requirement of at least 0.9 to block most fraudulent attempts. Maximizing precision above that threshold curtails customer complaints.
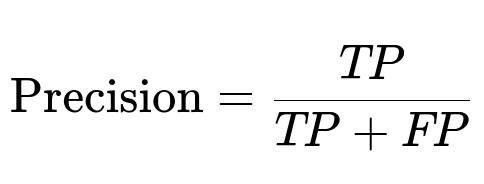
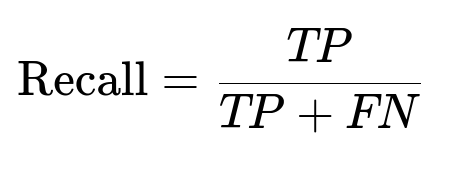
Where:
TP is the count of fraud cases correctly flagged.
FP is the count of genuine transactions incorrectly flagged.
FN is the count of missed fraudulent attempts.
Real-time Implementation
Production constraints demand near-instant decisions. Aggregation happens offline. Each day, aggregated tables update relevant feature counts for every user. The model uses these precomputed features to output a probability of fraud in milliseconds.
Below is a simplified illustration in Python for how one might handle daily updates:
import datetime
from collections import defaultdict
# Suppose we maintain a dictionary of counts per user
special_trip_counts = defaultdict(int)
# Example of end-of-day aggregation process
def aggregate_daily_counts(trip_data):
today = datetime.date.today().strftime('%Y-%m-%d')
for record in trip_data:
user_id = record['user_id']
trip_type = record['trip_type']
trip_day = record['day']
if trip_type == "special" and trip_day == today:
special_trip_counts[user_id] += 1
During scoring, the model fetches special_trip_counts[user_id] to compute new or existing features. This separation of offline feature preparation from online prediction is critical.
Deployment and Shadow Mode
An internal model-hosting platform can run the model as an API endpoint. The model serves predictions in shadow mode before full rollout. In shadow mode, the system logs predictions without acting on them. This process uncovers data or scoring discrepancies in production.
After validating performance, the platform gradually diverts more traffic to the model-driven path. The approach includes gating logic so that severe misclassifications do not break user flows.
Results and Future Outlook
Shifting from rules to a machine learning model improved fraud detection precision by 60%. User complaints declined because fewer legitimate users were incorrectly blocked. The system remains under constant monitoring. Fraud patterns evolve, so data scientists must continuously refine features and thresholds.
Potential Follow-up Questions
How would you handle a situation where some genuine transactions are incorrectly denied?
Models inevitably produce some false positives. An explanation approach:
Identify the top features influencing the model decision.
Investigate if certain rules or distributions are overly restrictive.
Consider dynamic thresholding (e.g., raising the decision threshold when a specific user has historically valid payment behavior).
Create a customer complaint feedback loop to catch and learn from false positives. Explain how misclassification data is tracked to retrain the model with updated labels. Emphasize version control for rollback if new thresholds cause too many false negatives.
How do you measure model performance when the system denies or blocks transactions, making it unclear whether they were fraudulent?
Explain that you can:
Run an A/B test or partial traffic split. Compare transactions served by the existing rule-based approach vs. the new ML model.
Use historical data where outcomes are known to validate the model offline.
Deploy the model in shadow mode for a sampling of transactions. For blocked transactions, track subsequent signals (e.g., repeated attempts or no further user activity) as potential evidence of fraud. Highlight how you might combine partial ground-truth outcomes with statistical inference to approximate performance on blocked transactions.
How do you ensure your offline training data aligns perfectly with real-time production data?
Discuss how string formatting, missing values, or feature transformations can differ between training and production pipelines. Emphasize:
Strict versioning of data definitions.
Checking aggregator logic for consistency.
Parallel logging in both the training environment and production environment. Mention that frequent spot checks, integration tests, and continuous monitoring of input distributions safeguard data alignment.
Why not rely on unsupervised anomaly detection?
Point out that while anomaly detection might discover novel fraud, it usually needs fine-tuning to avoid over-triggering. Traditional supervised methods typically excel when labeled fraud data is available. Anomaly detection can be a supportive approach in domains with sparse labels, but it can become complex for real-time decisions and threshold calibration.
What if the fraud patterns shift significantly over time?
Explain a strategy for continuous or regular retraining on recent data. Show how to keep a buffer of the most recent days or weeks to capture new behaviors. Describe a fallback approach where if the model sees an out-of-distribution pattern, it can revert to safer high-recall thresholds or escalate suspicious activity for manual review.
How do you select and maintain features that are most effective for this fraud model?
Describe a cycle of monitoring feature importances, removing stale features that no longer add value, and adding new ones that capture the latest fraudulent signals. Stress the importance of domain knowledge in designing features that reflect typical fraud tactics like stolen cards or repeated rejections of payments.
If you had to integrate a deep learning approach, how would you proceed?
Clarify that you would:
Analyze if unstructured data (images, text, etc.) could benefit from neural networks.
Determine if enough labeled data exists for those modalities.
Use embedding layers for categorical variables, or advanced architectures if the data has temporal sequences. Warn that deep models often require more tuning and compute resources, which might not always be optimal in low-latency environments.
End of case-study.