
ML Case-study Interview Question: Bi-LSTM for Accurate and Efficient Language ID in Short Text


Case-Study question
A fast-growing technology company faces frequent user complaints that their text-entry system fails to provide accurate auto-corrections and predictions. Engineers suspect the root cause is inaccurate language identification (LID) for very short text strings (10–50 characters). They must improve LID accuracy while also reducing the overall model size on resource-constrained mobile devices. Propose a robust method to classify the language of extremely short inputs. Explain how you would collect training data, design and train your model, evaluate performance, and ensure scalability as more training data becomes available.
Detailed Solution
A recurrent neural network that treats language identification as a character-level sequence classification problem solves this issue well. A bidirectional long short-term memory (bi-LSTM) model processes the incoming text from both left and right directions. This model achieves high accuracy on short strings and has a smaller disk footprint compared to older n-gram solutions.
Training involves splitting data by script (Latin, Hanzi, Cyrillic, etc.). Each script gets its own model to reduce confusion. For each language, gather representative text (news articles, social media posts, chat transcripts) to capture varied writing styles. Cap the input sequence length to a practical limit (like 10 characters for Latin). Label the data by language at the sequence level, starting each training sequence at a word boundary. Feed characters to the bi-LSTM as one-hot vectors or embedded vectors.
Below is the core LSTM gating formula. The hidden state h_{t} and cell state c_{t} are updated through input i_{t}, forget f_{t}, output o_{t}, and cell candidate g_{t}, which are computed via learned weight matrices and biases. LSTMs mitigate vanishing and exploding gradients through these gating mechanisms.
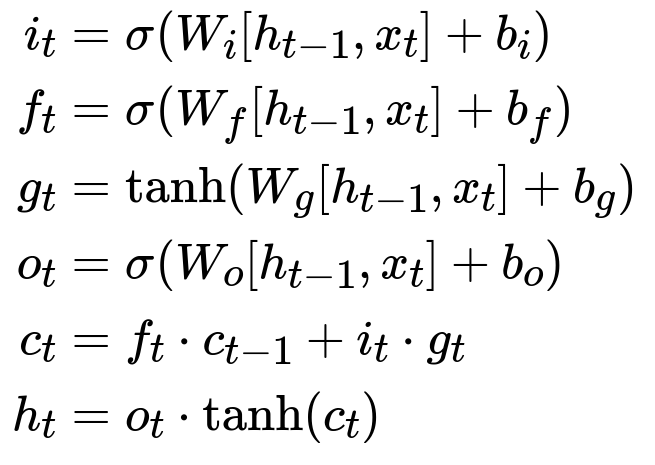
Each term denotes:
i_{t}, f_{t}, o_{t}: gate activations deciding how much new information enters, remains, or leaves the cell.
W and b: learned parameters for each gate.
c_{t}: cell state.
h_{t}: hidden state.
x_{t}: input at step t (character embedding).
A bi-LSTM runs forward and backward, then merges hidden representations to classify. A final softmax chooses which language out of K possible languages is most likely. Majority-voting or max-pooling across characters refines the final decision.
This approach learns from the entire sequence instead of relying on local n-gram statistics. More data helps performance without inflating model size, because the weight matrices remain constant in shape, unlike n-gram counts that grow with more data.
Below is a simple Python sketch of the training loop:
import torch
import torch.nn as nn
import torch.optim as optim
class BiLSTMLID(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers, num_langs):
super(BiLSTMLID, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers,
batch_first=True, bidirectional=True)
self.linear = nn.Linear(2 * hidden_dim, num_langs)
def forward(self, x):
emb = self.embedding(x)
out, _ = self.lstm(emb)
# Take the last hidden state (or max pool across time) for classification
out = out[:, -1, :]
logits = self.linear(out)
return logits
# Training loop (example)
model = BiLSTMLID(vocab_size=250, embed_dim=64, hidden_dim=128,
num_layers=2, num_langs=20)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
for batch_data, batch_labels in train_loader:
optimizer.zero_grad()
outputs = model(batch_data)
loss = criterion(outputs, batch_labels)
loss.backward()
optimizer.step()
This model processes short text sequences in both directions. Memory footprint is tied to learned parameters, so it stays nearly constant regardless of how many training examples you add.
What if the interviewer asks the following?
1) How do you ensure your model runs efficiently on a mobile device?
Neural networks can be compressed or quantized. Character embeddings can be reduced. Pruning unneeded connections in the LSTM helps. Converting weights to lower precision (16-bit floating point or 8-bit integer) maintains acceptable accuracy while lowering memory usage. On-device frameworks accelerate matrix multiplication with hardware optimizations.
2) Why not train a single classifier across multiple scripts?
Mixing vastly different scripts in one model raises confusion. Separating them keeps each model specialized. A quick script-detection step (like Unicode block checks) dispatches text to the relevant model, which is smaller and more accurate.
3) How would you handle overlapping features between similar languages?
Accumulate contextual data. Bi-LSTMs encode sequential context better than n-grams. If confusion persists, add more training examples of borderline cases. Expand the model’s hidden size if needed, but remain mindful of memory constraints.
4) How do you deal with code-switching, where users mix languages in the same string?
Split the input text into segments. Apply the relevant script-based classifier to each segment. For a single script covering multiple languages, run a sliding window over the characters. Track language probabilities at each window and segment the string accordingly.
5) How do you handle unseen characters or new user slang?
Map unknown characters to an “UNK” token. The LSTM learns general patterns for these placeholders. Periodically retrain or fine-tune your model with new data that includes emerging slang or unusual characters. This keeps performance high in evolving user contexts.
6) How do you confirm that your system outperforms an older n-gram baseline?
Run confusion matrix comparisons on a test set of short strings for each language. Compare accuracy at the diagonal (correct classification) and look at off-diagonal errors. Observe error-rate reductions or accuracy gains. Check memory usage and compute time. The LSTM solution typically yields better language identification and smaller model size.
7) Why does LSTM outperform n-grams for short strings?
N-gram methods rely on local character co-occurrence frequencies, which often fail with fewer characters. LSTM states retain context from the entire sequence. This advantage is crucial for short text, where every character can shift meaning drastically.
8) How would you scale the system to hundreds of languages?
Group languages by script. Train separate models or cluster languages with similar structures. Increase hidden-layer capacities if needed. Use hierarchical training strategies. Be mindful of inference time when loading many models.
9) What if your data distribution is skewed, with far more examples of one language than others?
Use class-balanced sampling or oversampling for rare languages. Apply class weights in the loss function to mitigate underrepresented languages. Monitor per-language metrics, not just overall accuracy, to ensure coverage.
10) How do you handle real-time usage with partial user input?
Feed character-by-character data to a streaming bi-LSTM in an incremental fashion. Update predictions as the user types. Maintain a hidden state across the partial sequence. The system can refine language predictions with each new character.
All these steps ensure a robust LID system that excels at short strings. By prioritizing memory optimization, gating mechanisms, and carefully curated data, the model matches the requirements of modern text-entry pipelines.