
ML Case-study Interview Question: Auto-Categorizing Data Fields at Scale Using Hybrid Rules and Machine Learning.


Browse all the ML Case-Studies here.
Case-Study question
A leading technology platform processes massive datasets stored across different systems. They want to auto-categorize the fields in these datasets (at column level) with minimal human input. Many fields look identical (for example, numeric fields named “value” or “note”), but they may represent different types of data (like a latitude, an exchange rate, or a cost). The platform wants to automate tagging fields as personal data, financial data, location data, and more. They plan to use a hybrid approach of manual tagging of less than 1 percent of key datasets and using this as labeled data to train an AI/ML system. Some columns are extremely sensitive, so misclassification is risky. They want a system that uses both rules and machine learning models, works at scale with diverse storage systems, and continuously learns from errors and reclassifies fields when rules or models improve.
They ask you to outline a design for this auto-categorization system. Explain your data science approach. Show how you would handle the scale, ensure accuracy, and incorporate feedback loops to refine rules and models. Propose ways to mitigate high false positives and false negatives, especially for sensitive data. Finally, describe how you would measure success and track metrics like accuracy, precision, recall, and F2.
Proposed Solution
A multi-stage pipeline is suitable. The first stage builds a minimal “golden” labeled dataset, focusing on high-impact tables, to train an initial machine learning model and to create robust handcrafted rules. A second stage applies these techniques to the large majority of unlabeled data. A final stage introduces checks, reviews, and continuous improvements.
Building the Labeled Baseline
A small sample of critical datasets is manually classified. Domain experts verify these columns. These verified datasets provide ground truth for training and evaluating the model. The manual effort is limited to high-value tables, reducing cost while still creating reliable training data.
Rule-Based System
Rules interpret features such as column names, data types, known dictionaries, typical value ranges, or patterns like an email regex. The system gives each rule-based signal a weight, which might be positive or negative. The rule engine sums these signals to produce a final score per category per column. If the score exceeds a threshold, the system assigns that category.
Machine Learning Classifier
The model ingests metadata (column name, type, location) and sampled data values (like 1 percent of rows). It transforms them into feature vectors for a classification algorithm. Linear SVM often works well, but other algorithms can be tested. Low-support categories might require extra labeled examples. The model outputs a score for each category, and these scores are combined with rule-based results.
Combining Signals
Lineage (knowing which columns feed into which new tables) helps. If a derived table’s column has strong lineage from a known sensitive column, that signal increases the probability. The system aggregates all signals. Weighted ensembling merges rule-based scores and ML-based scores. A final threshold decides classification.
Feedback Loop
Domain experts and dataset owners can correct classifications. Those corrections are logged, and the system adjusts rules or retrains models to avoid repeating mistakes. Over time, rules become more refined, and model accuracy improves. The system then re-tags datasets with updated logic.
Accuracy and Metrics
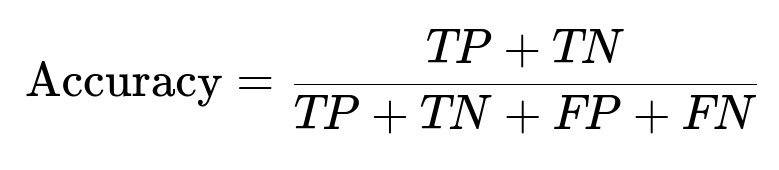
TP is true positives. TN is true negatives. FP is false positives. FN is false negatives.
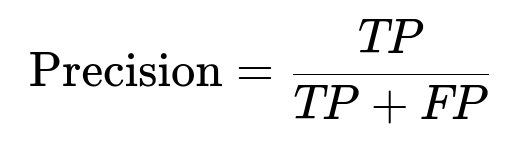
Precision captures how many predicted positives are correct.
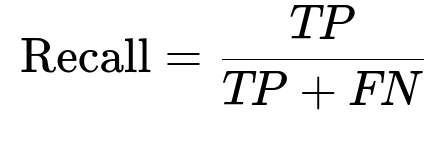
Recall measures how many actual positives are found.
F2 emphasizes recall more than precision. Tracking these metrics helps ensure sensitive columns are seldom missed and columns are not wrongly flagged. Additional indicators like how often an owner overrides an auto-tag give insight into areas needing improvement.
Production Deployment
A central sampling system draws data from all storage technologies. This standardized pipeline processes each new dataset. Early in production, auto-categorized labels trigger human review for the riskiest tables. Low-risk tables skip review. Over time, confidence grows, and full automation takes over unless manual override flags recurrent errors.
Code Snippet Example in Python
import re
def rule_based_score(column_name, sample_values):
score = 0
# Example rule: if column name matches an email regex, give some positive score
# This is a simplistic illustration
if re.search(r'email', column_name.lower()):
score += 10
# Another rule: check the content of sample values
for val in sample_values:
if re.match(r'^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$', val):
score += 5
return score
column_sample = ["john@example.com", "alice@yahoo.com", "sales@company.org"]
print(rule_based_score("user_email", column_sample))
The function checks the column name and pattern-matches the sampled values. A real system would incorporate more rules with negative or contextual scoring.
Follow-Up Question 1
Explain why a single numeric column can be ambiguous without extra context. How do you ensure the model or rule engine differentiates between location data and financial data?
A numeric column might represent monetary amount, age, latitude, or other fields. Generic column names like “value” or “amount” reveal minimal information. Rules or models use known dictionaries, typical numerical ranges, lineage from a known source, or correlated columns in the same table. A numeric location field might be combined with another location-like column. A numeric financial field might come from a database named “finance_transactions.” These context clues reduce ambiguity.
Follow-Up Question 2
How do you handle columns that might mix data types, like a free-text field containing both numeric codes and personal text?
For free-text fields, sampling enough rows is essential. The system detects multiple categories if strong signals exist. Mixed content might produce partial matches for various rules, so the aggregated score could be split among different labels. A threshold-based approach might classify the column as “unstructured text” if no single category dominates. In more advanced setups, sub-column detection or natural language processing might refine the categorization for partial fields.
Follow-Up Question 3
What strategies do you use if an ML model has acceptable accuracy on common tags, but fails badly on rare tags?
Increasing labeled data for rare tags is key. One approach is targeted sampling: ask experts to label more examples of these tags. Another approach is to combine rarely used tags into broader groups if possible. Feature engineering can be refined for these categories. You can also apply transfer learning from related but more common labels, or adopt cost-sensitive learning that penalizes mistakes on rare classes.
Follow-Up Question 4
Why is negative scoring useful? How do you implement it?
Negative scoring helps counter spurious matches. A rule might say, “If the database name is ‘public_repos,’ penalize any personal data category because it is unlikely to contain private user data.” Implementation involves assigning a negative weight when certain conditions are met. For example, a finance name match might yield +5 for “transaction_data” but a mismatch in a purely public dataset might yield -5, reducing false positives.
Follow-Up Question 5
How would you automate updates to handcrafted rules?
Collect override logs of inaccurate tags. Identify repeated mistakes. Build a small pipeline that mines these mistakes for patterns. For instance, a misclassified location might reveal that a dictionary approach was insufficient. The pipeline then suggests new or modified rules, adjusts thresholds, or updates data dictionaries. Domain experts can review these suggestions. Eventually, a fully automated loop will safely push updates once confidence in the proposed changes is high.