
ML Case-study Interview Question: Neural Network Behavior Fingerprinting for Detecting Rideshare Driver Scams


Browse all the ML Case-Studies here.
Case-Study question
A rideshare platform has observed a sophisticated scam targeting drivers. Scammers pose as official support representatives and trick drivers into sharing account credentials. The scammers’ app usage logs show suspicious repeated ride cancellations, high driver contact activity, and other unusual patterns. You are tasked with designing a data-driven system to detect and prevent such fraudulent user behavior. How would you approach this problem end to end?
Background and context
Fraudsters create user accounts, request rides, then call drivers with claims of special awards. They trick drivers into providing verification information, leading to account takeover and stolen funds. Over time, these scammers adapt their tactics (for example, using different phone numbers or partially completing rides) to evade rules-based detection.
Requirements to solve
Build a robust model or set of models to identify suspicious behavior and block fraudsters.
Handle high-volume event streams capturing user actions in real time.
Maintain good user experience by not over-blocking legitimate drivers or riders.
Evolve detection methods as scammers change their patterns.
Detailed Solution
Data sources
Collect user activity logs (app events like ride requests, cancellations, screen interactions) and structured features (transaction data, location checks, account info). Stream these signals for online or near-real-time inference.
Model selection
Start with gradient-boosted decision trees (GBDT) because they handle heterogeneous features (numeric and categorical) and capture feature interactions. But GBDT alone struggles to model temporal relationships. Introduce a neural network architecture that directly processes user action sequences, preserving order and timing.
Neural architecture for behavior fingerprinting
Use an embedding layer to transform each discrete action into a dense numeric representation. Pass embedded actions into 1D convolutional layers that extract local n-gram-like patterns. Feed the convolutional outputs into a recurrent neural network (for example, LSTM) to preserve longer-term dependencies. Combine the final RNN output with structured features. Output a classification score indicating likelihood of fraud.
Core formula
Below is the cross-entropy loss function often used to train such classification models:
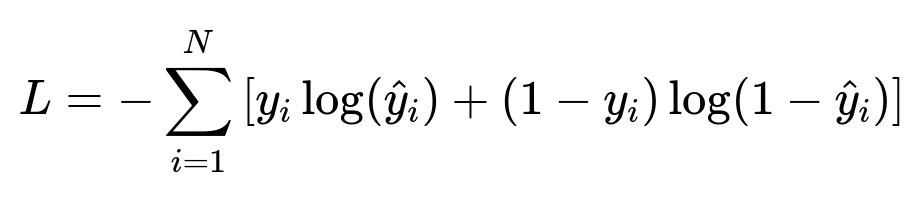
Where y_i is the true label (fraud or not fraud) and hat{y}_{i} is the model’s predicted probability. N is the number of training samples.
This formula measures how well the model’s predicted probabilities match the true labels. The term y_i log(hat{y}_i) penalizes incorrect predictions for the positive class, while (1 - y_i) log(1 - hat{y}_i) penalizes incorrect predictions for the negative class.
Improving robustness
Train with sequences representing real user sessions. Capture repeated patterns of canceling rides or calling drivers. Include partial sessions for near-real-time blocking. Validate the model on fresh fraud patterns to confirm adaptability.
Practical considerations
Keep track of concept drift as scammers shift tactics. Monitor performance metrics such as precision, recall, and false positives. Retrain or fine-tune the model when you observe new behavioral footprints. Augment your approach with semi-supervised methods (for example, generative adversarial networks) to learn normal behavior and flag anomalies.
Implementation outline
In Python, you might build the neural pipeline as follows:
import tensorflow as tf
from tensorflow import keras
def build_behavior_fingerprint_model(num_actions, embedding_dim, seq_length, structured_input_dim):
input_actions = keras.Input(shape=(seq_length,))
embeddings = keras.layers.Embedding(input_dim=num_actions, output_dim=embedding_dim)(input_actions)
conv_output = keras.layers.Conv1D(filters=64, kernel_size=3, activation='relu')(embeddings)
conv_output = keras.layers.Conv1D(filters=64, kernel_size=3, activation='relu')(conv_output)
rnn_output = keras.layers.LSTM(64)(conv_output)
input_structured = keras.Input(shape=(structured_input_dim,))
combined = keras.layers.Concatenate()([rnn_output, input_structured])
dense_output = keras.layers.Dense(64, activation='relu')(combined)
final_output = keras.layers.Dense(1, activation='sigmoid')(dense_output)
model = keras.Model(inputs=[input_actions, input_structured], outputs=final_output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
This code uses an embedding layer for action IDs, two convolutional layers for local feature extraction, an LSTM for sequential modeling, and final dense layers combining structured features. In production, deploy the model behind an API that scores each new session in real time.
Possible Follow-Up Questions
1) How would you handle incomplete or very short user sessions?
Short sessions lack enough events to form robust temporal patterns. Use partial session data in the RNN. Initialize hidden states with minimal prior events. If session length is extremely short, fall back on structured features. Train the model on mixed-length sequences so it learns to handle partial data.
2) How do you address model latency in real-time fraud detection?
Optimize model serving by reducing concurrency overhead and using efficient libraries (TensorFlow Serving, ONNX, etc.). Use batching when feasible. Profile the pipeline to identify bottlenecks. If needed, run a smaller, distilled version of the model for real-time checks, then run a more complex offline model for further review.
3) How would you keep up if fraudsters change their tactics?
Monitor downstream metrics. Look for distribution shifts in features and user behaviors. Log new fraudulent sessions and re-label them quickly. Retrain or fine-tune your models regularly. Deploy an anomaly detection system that compares ongoing activity to normal patterns, then route flagged sessions to specialized classifiers or manual review.
4) How would you handle the risk of overfitting on certain known fraud patterns?
Ensure you have a large, diverse dataset with balanced representation of normal and fraudulent activities. Use regularization in your neural network. Stop training early when validation loss stops improving. Perform thorough cross-validation. Periodically test on data from new time periods. Use interpretability tools (for example, SHAP or integrated gradients) to see if the model focuses on spurious features.
5) How do you evaluate the model’s success beyond standard metrics?
Track financial impact. Compare the total blocked fraud amount vs. false positives. Monitor user satisfaction (for example, driver or passenger retention). Look at how the fraud rate changes over time. Check if average fraud ring lifecycle shortens. Evaluate how quickly the system adapts to new scams.
6) How would you use semi-supervised or generative approaches?
Train a generator to model normal user behavior. Generate synthetic samples representing typical actions, then label high-deviation patterns as suspicious. Use real fraudulent examples alongside these synthetic “normal” samples for a discriminator network. This method can detect unknown fraud behavior faster because it triggers on activities far from learned normal usage.
7) How do you incorporate business rules and the neural model together?
Use a hybrid strategy. Filter out obvious fraud with lightweight rules. Feed the remaining data into the neural network model. Combine the outputs with rules-based thresholds for final decisions. This approach catches known patterns quickly and lets the deep model handle complex or ambiguous cases.
8) Why not only rely on rules-based systems?
Rules-based systems are easy to maintain for known patterns but break when fraudsters change their methods. They cannot capture deep patterns without constant manual updates. They also do not handle high-dimensional signals or sequence modeling effectively. Neural models automatically learn complex interactions and adapt better over time.
9) How do you debug or interpret a neural network prediction in real-life fraud investigations?
Collect local explanations (for example, saliency on important actions). Highlight suspicious subsequences. Investigate the most influential features. Compare results across normal vs. fraudulent sequences. Work with fraud analysts who do manual reviews to align model decisions with ground truths and domain insights.
10) How would you scale this to millions of daily transactions?
Leverage distributed computing for data preprocessing. Use mini-batch training and GPU or TPU resources. Set up streaming pipelines (like Kafka) to push real-time events into a scoring service. Implement robust caching and asynchronous processes for large-scale scoring. Monitor latency and concurrency. Keep a well-structured data schema for easy model updates and re-deployments.