
ML Case-study Interview Question: Automated Property Attribute Extraction using NER and Embedding Similarity


Case-Study question
You are hired by a major online travel platform that wants to extract structured information about property listings from a massive amount of anonymous text data gathered through various text-based guest interactions. The platform is interested in automatically detecting whether a property has important amenities, facilities, or local attractions. They already have a large taxonomy of possible attributes (for example, "crib," "pool," and "gym"), but Hosts often forget to mark these attributes, and different guests describe them in many ways. The company wants you to design and implement a system that can detect relevant text phrases, map them to standard attributes, and assign a confidence score about whether the attribute is present or absent. How would you build this system and ensure it scales to handle millions of free-text inputs while maintaining high accuracy and consistency? What modeling approaches would you employ, and how would you evaluate and integrate the final output into other products like personalized recommendations or property categorization?
Provide a full end-to-end solution approach, including details on data processing, model design, deployment, and long-term maintenance.
Detailed Solution
Overview
The goal is to automatically extract structured information from unstructured text data describing property listings. This involves processing anonymous free-text inputs, identifying relevant named entities (such as amenities, facilities, or other key features), mapping those entities to a defined taxonomy, and scoring their presence or absence for each property. One robust solution framework is the Listing Attribute Extraction Platform (LAEP) approach.
Named Entity Recognition (NER)
Text passages are processed through a custom NER model that targets categories relevant to the business, such as amenities, facilities, local attractions, and property structures. First, the text goes through language detection and tokenization. Then the model locates spans of text that match predefined entity types. For example, "swimming pool" is classified as an amenity. These typed entities are the building blocks for further steps.
A practical way to train the NER model is to label a substantial dataset of example text snippets taken from different user input sources. The labeled data is split into training and validation sets. A convolutional neural network or transformer-based model can be used for sequence labeling. The trained model is then evaluated using strict span matching, which checks both entity boundaries and correct categories.
Entity Mapping
Many text phrases refer to the same attribute in different ways. For instance, "lock-box," "lockbox," and "keybox" can all map to the standard "lockbox" attribute in the taxonomy. The system resolves these variations by converting each detected entity phrase and each taxonomy attribute into vector embeddings, then measuring similarity to find the best match.
The similarity metric that captures how closely two vectors align is typically cosine similarity. Here is the core formula in big font:
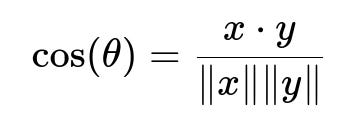
Where x dot y is the dot product of two embedding vectors x and y, and ||x|| and ||y|| are the magnitudes (norms) of x and y. A higher similarity score indicates a closer match between the detected entity phrase and a standard taxonomy entry. If no attribute exceeds a certain threshold, the result is “No Mapping,” signaling the phrase is irrelevant for that taxonomy.
Entity Scoring
Even if a phrase has been mapped to a known attribute, the system still must decide if that attribute truly exists for the listing or if the text expresses a negative sentiment or uncertain statement. This presence detection can be formulated as a text classification problem. A fine-tuned BERT or similar transformer-based model examines the local context around the detected phrase and assigns a probability that the attribute is indeed present in the listing. The classification output (YES, Unknown, NO) is combined with a confidence score to help downstream applications decide if the attribute should be flagged as present or not.
Integration and Future Use-Cases
Once the attributes are extracted, they can be integrated into multiple products, such as:
A property attribute editor that prompts Hosts to confirm or add missing attributes.
Personalized guest search or recommendation systems that highlight relevant amenities.
Analytics tools that identify new emergent attributes important to travelers.
This process can also scale to discover new attributes (for example, user mentions of unusual features) by tracking high-frequency phrases that are not yet in the taxonomy.
Model Maintenance
User language is always evolving, and new synonyms appear often. Periodic retraining and regular data refreshes help keep the NER, entity mapping, and entity scoring models accurate. Retraining can include capturing new user texts and collecting human-labeled examples of any unknown terms that become common enough to matter.
Implementation Example (Python)
A simplified snippet for entity mapping with cosine similarity:
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
if norm1 == 0 or norm2 == 0:
return 0.0
return dot_product / (norm1 * norm2)
def map_entity_to_attribute(entity_text, attribute_dict, embedding_model):
entity_vector = embedding_model.get_vector(entity_text)
best_match = None
best_score = 0.0
for attr_name in attribute_dict:
attr_vector = embedding_model.get_vector(attr_name)
score = cosine_similarity(entity_vector, attr_vector)
if score > best_score:
best_score = score
best_match = attr_name
return best_match, best_score
The above code loads or references a pretrained embedding model, takes the detected entity text, and compares it with every known attribute vector to find the highest similarity. This is a simple demonstration. In production, you might use approximate nearest neighbor search for speed when dealing with large attribute catalogs.
Follow-Up Question 1
How would you handle noisy or incomplete text inputs, especially if guest-provided data is full of spelling errors, abbreviations, or ambiguous phrases?
Answer Explanation
Noisy inputs are tackled by a combination of text preprocessing, domain-specific spelling correction, and language models trained on actual user data. Preprocessing typically removes special characters and normalizes spaces. Spelling correction rules can be created to handle common misspellings relevant to the platform’s domain. If there are abbreviations or slang terms frequent in guest conversations, the model’s vocabulary or tokenizer is expanded. Fine-tuning a word2vec or transformer-based embedding on authentic text from the platform is crucial, because it captures domain-specific writing habits and synonyms. To handle ambiguous phrases, the system uses the presence model and context around the entity to decide if a mention really implies the attribute is present or not.
Follow-Up Question 2
How would you measure the performance of the entire pipeline, and what metrics would you monitor over time?
Answer Explanation
Evaluating performance happens at multiple stages. For NER, the strict match F1 score measures how effectively the model identifies and categorizes entity spans. For entity mapping, accuracy or precision at top-1 match is used to confirm the correctness of the mapped attribute. For presence classification, separate metrics such as precision, recall, and F1 measure how well the model decides if an attribute truly exists. End-to-end accuracy can be evaluated by verifying if a set of known property attributes matches the final predictions. Over time, monitoring drift in the text distribution is key. If a drop in recall or an increase in unknown phrases is detected, the training data or the model might need an update. Maintaining a human-labeled set of text examples is an excellent way to measure real-world performance and trigger re-training or model refinements.
Follow-Up Question 3
What strategies would you use to ensure your pipeline is privacy-aware, given that the data is user-generated text?
Answer Explanation
All personally identifiable information should be removed before the pipeline processes the text. This might involve named-entity redaction rules that filter names, phone numbers, email addresses, and addresses. The tokenization or anonymization modules run before the text is fed to the NER model, ensuring the pipeline never stores or shows personal details. Any logs or intermediate data must also be sanitized and stored with robust access controls. Compliance with data protection regulations requires careful auditing of how data is ingested, used, and retained, so regularly scheduled privacy reviews are essential.
Follow-Up Question 4
What modifications would you make if you wanted to scale this platform to multiple languages?
Answer Explanation
Multilingual expansion starts by creating language detection and branching the pipeline according to the detected language. For every additional language, you need a labeled dataset or a cross-lingual approach. One approach is to train a multilingual NER model that can handle multiple languages simultaneously. The entity mapping step might rely on multilingual embeddings or separate embeddings per language. The presence model can be fine-tuned on examples in those target languages. When scaling, region-specific synonyms or idioms should be incorporated. Continuous retraining is crucial, because language usage varies greatly across different countries and cultures, and the system must capture local naming for certain amenities or facilities.
Follow-Up Question 5
What challenges do you foresee if the taxonomy grows to tens of thousands of attributes?
Answer Explanation
A larger taxonomy means more embeddings to compare, so naive similarity searches can become computationally expensive. Scaling issues appear in both memory usage and query time. Approximate nearest neighbor (ANN) search techniques like FAISS, HNSW, or ScaNN can speed up high-dimensional similarity searches. Index structures in ANN algorithms reduce the time needed to find the top candidate attribute vectors. Another challenge is an increasing overlap of attributes, which may lead to confusion among models. Clear attribute definitions and rigorous pruning or consolidation of similar attributes help. Ongoing user feedback is essential for refining the taxonomy so it remains meaningful and not overloaded with marginal items.
Follow-Up Question 6
Could these extracted attributes enable new product features beyond simple search improvements?
Answer Explanation
Yes. Extracted attributes can drive dynamic personalization by showing listings to specific user segments (for instance, remote workers, families, or adventure travelers). Attribute data can feed analytics systems that uncover emerging trends in host offerings or traveler preferences. Property owners can receive automated suggestions about popular amenities they might consider adding. Local attraction data can be used for personalized trip recommendations or neighborhood guides. Additionally, new categories of accommodations can be discovered by analyzing patterns in the extracted features, creating fresh browsing or filtering experiences for users.
That concludes the comprehensive solution, discussion, and possible follow-up questions relevant to a Senior Data Scientist role.