
ML Case-study Interview Question: Detecting Recommendation Quality Shifts Using Data Distribution Monitoring


Browse all the ML Case-Studies here.
Case-Study question
A leading streaming platform wants to improve its recommender system. The system suggests movies, TV series, news, and sports content to users. The Business Intelligence Team reports that, while the system seems to respond properly, some audiences complain about irrelevant content. Engineers suspect that the data pipeline and model update process might cause recommendation quality shifts that are not captured by typical service uptime checks. You are asked to propose a robust monitoring strategy for detecting drops in recommendation quality, especially focusing on data passed to the model, final recommendations users receive, and model training data. Describe how you would implement a scalable, flexible, and automated monitoring solution that addresses possible anomalies before they impact user experience.
Provide specific metrics, explain the underlying technical reasoning, and detail how you would handle the real-time flow (for request/response data) alongside batch data (for training pipelines). Discuss how to approach alert thresholds, root-cause analysis, and integration with an engineering workflow so domain owners can handle new or evolving metrics over time. Suggest ways to ensure continuous improvement of the monitoring system.
Proposed Solution
The monitoring solution must target three major categories: data passed into the model for inference, final recommendation outputs, and the model training data pipeline. Monitoring these areas ensures that input errors, post-processing errors, or training data anomalies do not go unnoticed.
Data Passed into the Model
Log every user feature or metadata passed for inference. Compare the distribution of each field over time. If user locale fields suddenly shift (for example, the fraction of a certain language usage spikes), investigate the client or backend data-passing module for possible bugs. This approach prevents silent data drifts.
Final Recommendation Outputs
Compare the resulting recommendation lists’ size, genre composition, or other meaningful attributes. Sudden drops in the length of a recommendation list may imply model or post-processing logic failures. Monitoring these outputs prevents issues like expired content filtering or empty list scenarios from eroding user satisfaction.
Model Training Data
Inspect training samples for missing features, abnormal label ratios, or sudden decreases in data volume. If the portion of positive labels fluctuates wildly, reevaluate your data pipeline, including any upstream data changes. Keeping these data properties stable preserves training consistency.
Distribution-Change Metrics
Comparing distributions at two different time points helps detect anomalies. One common measure is KL Divergence.
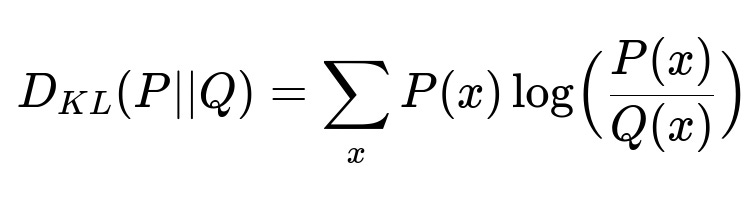
P(x) is the probability of x in the current distribution, Q(x) is the probability of x in a historical or reference distribution. KL Divergence indicates how much the current data distribution deviates from the reference distribution.
Implementation Considerations
Build separate real-time data ingestion for user request/response logs and a batch pipeline for training data. Real-time logs are processed within seconds, generating near-instant alerts if a distribution changes. Batch data is processed less frequently, but still watch out for event-time shifts that introduce lag. Maintain a scalable approach so introducing a new model simply adds a new configuration for its unique metrics without disturbing existing jobs.
Alert Configuration
Set thresholds that focus on high precision. Excessive false positives lead to alert fatigue. Engineers should regularly tune thresholds based on actual anomalies. A monthly review of all triggered alerts encourages lessons learned and fosters updates to monitoring strategies.
Ownership and Domain Knowledge
Involve domain owners in defining new metrics for new features, new content categories, or user interface changes. They maintain the metrics they own and adjust alerts as the business evolves. This division of responsibility keeps the monitoring solution aligned with changing requirements.
Continuous Improvement
Revisit logging strategies, thresholds, and monitored features. Document discovered anomalies in post-mortems. Over time, this feedback loop expands coverage and improves detection accuracy.
Follow-Up Question 1
How would you handle performance overhead while logging features for real-time monitoring?
Engineers often worry about the trade-off between thorough data logging and system latency. Over-collection can slow the service. Minimizing overhead requires a careful selection of only the most important features. Use asynchronous logging methods to write logs in separate threads or processes. Batch the logs before sending them to a time-series storage system. Compress large payloads if necessary, and keep critical logs short and structured. If that is insufficient, random sampling of user requests (for example 1% of traffic) can reduce data volume while preserving distribution patterns.
Follow-Up Question 2
How would you backfill historical data if you discover that your real-time logging was partially broken for a short period?
Check if there is a reliable fallback source, such as archived request logs in a separate system. Merge that source into your monitoring pipeline. Align event-time with the same metrics as real-time logs. Re-generate missing segments of the time series by replaying historical logs in chronological order, inserting them into the time-series database. Ensure the pipeline’s logic remains consistent for historical data, including any transformations and format conversions. Label these backfilled intervals clearly, so analysts understand the data was recovered and might have slight delays.
Follow-Up Question 3
What would you do if some newly launched user features cause distribution shifts, yet those shifts are legitimate and not an error?
Monitor baseline patterns for the new feature. If significant changes are expected, raise thresholds or separate the new feature’s metrics so they do not trigger false alarms. Mark normal changes as known events in the monitoring system. If a real anomaly is hidden inside a legitimate shift, refine the monitoring approach by isolating new-feature usage from stable usage. Compare each subset to its relevant historical range.
Follow-Up Question 4
Why might alerts be ignored if precision is not carefully tuned?
Excessive false alarms create noise. Engineers begin ignoring or muting the alerts that almost always turn out to be harmless. Once alerts become background noise, real issues go unnoticed. Sufficient effort to calibrate thresholds is required. Frequent re-checking of the alert-to-incident ratio and involvement of domain experts help shape correct triggers. If a system sends only relevant alerts, trust remains high, and teams respond rapidly.
Follow-Up Question 5
How would you integrate the system with an engineering workflow so domain owners can easily add or modify monitoring rules?
Design a flexible schema with a simple rules definition file. For real-time pipelines, deploy a long-running service that reads these rules at startup and reloads them on the fly. The domain owner updates a configuration repository, which triggers a continuous integration pipeline that pushes the new configuration to the service. This eliminates code redeploys for every new metric. Maintain version control to track who changed rules, when they did it, and why. Encourage the domain owners to annotate changes with business context, so the entire team understands the rationale behind each new or modified rule.