
ML Case-study Interview Question: Detecting Account-Hopping Retail Fraud Using Graph Neural Networks


Browse all the ML Case-Studies here.
Case-Study question
A major online retail platform faces repeated policy abuse from fraudsters who claim false product incidents (items not delivered or damaged). Fraudsters create multiple new accounts to avoid detection and gain free replacements or refunds. You are asked to design a data science solution that can identify and prevent such “account-hopping” fraudsters in an end-to-end manner. Outline the approach, specify how you would utilize shared customer attributes (payment, device, address, etc.) in a graph-based model, discuss model evaluation metrics, and propose a plan for real-time deployment.
Detailed Solution
Graph-Based Detection Approach
Construct a knowledge graph where each customer is a node. Draw an edge between two customers if they share attributes (email patterns, devices, or payment methods). Assign node features (account history, frequency of incident claims, etc.). Edges remain unweighted or can carry weights if certain attributes are more predictive of fraud.
Use a Graph Neural Network (GNN) to learn node representations that capture relational information. Train a node-level binary classifier to predict whether a given account is fraudulent or not.
GNN Architecture
A popular architecture is GraphSAGE, which iteratively aggregates features from each node’s neighbors. The message-passing process integrates information from the local subgraph.
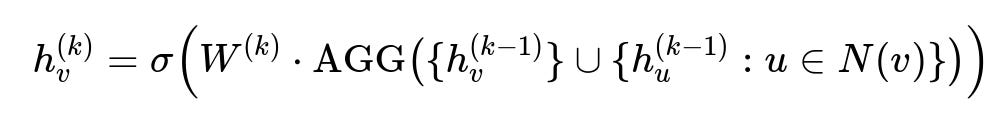
Parameters:
h_{v}^{(k)} is the updated embedding of node v at layer k.
W^{(k)} is a trainable weight matrix at layer k.
N(v) is the set of neighbors for v.
AGG is an aggregation function (e.g., mean, max, or pooling).
sigma is a nonlinear activation such as ReLU.
At the final layer, produce a log-softmax output for binary classification. Label fraud accounts with a positive class.
Training Setup
Train on historical data where fraud labels are known. Split the graph into train, validation, and test sets by nodes. Each node’s feature vector includes user attributes, incident claim patterns, and aggregated neighbor features. Use a Precision-Recall AUC metric to emphasize detecting fraudulent accounts with minimal false positives.
Infrastructure and Serving
Batch inference runs several times a day to flag newly created accounts. Generate node embeddings by sampling neighbors (GraphSAGE sampler). Store embeddings in a feature store for downstream models. Consider real-time serving by caching relevant neighbor features in memory or using a low-latency graph database. Overcome challenges of dynamic graph updates with incremental training or frequent re-training.
Example Python Snippet
import torch
from torch_geometric.nn import SAGEConv
import torch.nn.functional as F
class FraudGNN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.conv1 = SAGEConv(in_channels, hidden_channels)
self.conv2 = SAGEConv(hidden_channels, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=0.2, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# Model usage example
# x: node features, edge_index: adjacency info
model = FraudGNN(in_channels=128, hidden_channels=64, out_channels=2)
out = model(x, edge_index) # Log-softmax predictions
Train the model with negative log-likelihood loss. Evaluate on a validation set, optimize hyperparameters (learning rate, dropout, aggregator type), and track performance.
How would you further validate model performance in a real-world environment?
A/B test the GNN-based detection against a baseline system. Evaluate cost savings from intercepted fraud and measure false positives. Observe whether flagged users contact support or correct mistakes. Monitor Precision at high Recall to ensure minimal friction to genuine customers.
How do you address the risk of over-smoothing in deeper GNN layers?
Over-smoothing occurs when repeated message passing makes all node embeddings similar. Limit the number of layers to 2 or 3. Use skip connections or residuals in deeper architectures. Apply dropout and choose an appropriate neighborhood size. If topological depth is necessary, experiment with Graph Attention Networks to focus on more critical neighbors.
How do you incorporate device or payment attributes that are often shared by many users?
Add intermediate nodes to represent attributes (e.g., Device A, Payment Method B). Link them to corresponding customers. This bipartite structure captures attribute usage frequency. Weighted edges can reflect the attribute’s risk level. The GNN learns patterns from attribute usage, spotting unusual overlaps.
What are possible failure cases or adversarial tactics from fraudsters?
Fraudsters may vary their information. They might switch devices, addresses, or payment methods. They may try to randomize names or re-route packages to third parties. Regularly retrain and incorporate advanced features (location anomalies, velocity checks). Continually expand coverage to new or obscure attributes.
How do you handle real-time detection if graph updates come in continuously?
Build a near-real-time pipeline. Whenever a new order arrives, incrementally update the graph in a streaming database. Employ fast approximate neighborhood retrieval techniques (e.g., indexing attributes in memory). Run inference for suspicious accounts on a streaming basis. Retrain periodically with offline batch processes for accuracy stability.
How do you scale training when the graph becomes very large?
Use mini-batch training with neighborhood sampling. Partition the graph into subgraphs. Store data in a distributed system (e.g., graph databases or specialized systems). Leverage frameworks like PyTorch Geometric or DGL that are optimized for large-scale GNNs. Perform regular housekeeping to remove inactive users or irrelevant edges.
How would you justify investment in GNN models over standard feature engineering?
Demonstrate improved Precision-Recall AUC in offline experiments. Show the same or better business metrics in production (reduced fraudulent claims, minimal false flags). Highlight the automated feature extraction that GNN provides, reducing manual overhead and capturing subtle relationships. Confirm the model’s ability to generalize to new fraud patterns.
How to integrate these GNN outputs with other fraud detection pipelines?
Export node embeddings or fraud scores into a feature store. Let other models consume these embeddings as features (boosted trees, logistic classifiers). In decision-rules engines, combine the GNN score with manual rules or watchlists. Validate synergy in an online experiment, ensuring improved catch rates or cost savings.