
ML Case-study Interview Question: Detecting Food Delivery Claim Fraud Using Weakly Supervised Label Generation


Browse all the ML Case-Studies here.
Case-Study question
A popular online food delivery platform runs a three-sided marketplace with customers, restaurants, and delivery partners. Fraud and abuse sometimes occur. They want an automated system that detects suspicious claims made by customers after order delivery, where these claims might be about missing items or quality issues. They have limited human-labeled data for training. They collect huge volumes of unlabeled transaction data every day and want a scalable way to generate labels and train a fraud classifier. Design a detailed solution strategy that addresses how to gather weak labels, clean them, build features, build a final discriminator model, and serve it in real time to decide whether a claim is genuine or fraudulent. Propose methods to handle potential fraud rings or collusions among customers, and suggest how you would measure impact.
Proposed Approach
Create an end-to-end pipeline that starts from data ingestion and ends with real-time fraud decision. Use a four-stage process: data and feature processing, label generation, a final discriminator model, and a feedback-driven evaluation system.
Data and Feature Processing
Aggregate historical data of claims and orders. Store the data in a centralized data warehouse. Partition it into smaller segments:
A small set of strongly labeled data from human experts.
A large unlabeled dataset containing transaction records.
Build cross-sectional features like customer tenure, restaurant reliability, and delivery-partner attributes. Build near real-time features including current order details and short-term claim counts. For sequence modeling, collect recent order histories for each customer to highlight potential bursty behavior. Construct a graph of customers connected by shared payment instruments or other relevant factors and derive embeddings to capture collusive patterns.
Label Generation
Combine domain knowledge and automated methods to generate weak labels. Write multiple labeling functions (LFs). Each LF can label a data point as fraud, non-fraud, or abstain. Merge LF outputs using a generative model that reconciles conflicts between LFs and estimates label confidence. Observe that some generated labels remain noisy. Train two autoencoders, one per class (fraud and non-fraud). Compute reconstruction errors. Flip labels whose reconstruction error is higher for the assigned class but lower for the opposite class. Perform two iterations so final labels are stable.
Final Discriminator Model
Train neural networks on features and final weak labels. One approach is a Multi-Layer Perceptron (MLP) with cross-sectional, near real-time, and graph-embedding features. Another approach is an LSTM over sequential behavior. Ensemble both outputs for the final fraud probability. Use standard classification objectives.
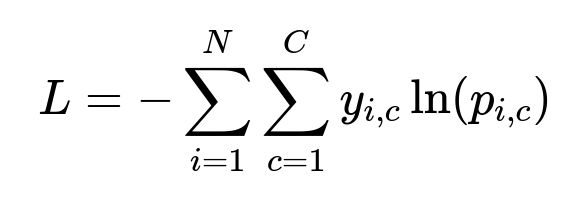
Here, N is the total number of samples, C is the number of classes (fraud or non-fraud in a binary scenario), y_{i,c} is the actual label (0 or 1) for class c of sample i, and p_{i,c} is the predicted probability.
Implementation Infrastructure
Use a data pipeline (for example, Spark or Flink) to generate features in batch and near real-time. Store computed features in a low-latency key-value store for model-serving. Serve the neural network with a high-throughput microservice that fetches the stored features and outputs the fraud score. Post-decision feedback is sent to the risk team for periodic auditing and re-labeling to maintain model precision.
Follow-up Question 1
How would you handle ongoing changes in fraud patterns?
Use a weakly supervised approach that is regularly retrained. Periodically refresh labeling functions or decision trees with newly labeled data. Monitor feature distribution drift. Incorporate newly discovered fraud trends into updated graph embeddings. Revisit autoencoders to flip labels of outliers that do not match the current distribution. Maintain a real-time feedback loop with human experts who sample flagged claims weekly or monthly and refine the model.
Follow-up Question 2
Why not rely solely on a large manually labeled dataset?
Manual labeling at scale is expensive and slow. Fraud changes quickly. A purely manual approach lags behind evolving fraud patterns. Weak supervision leverages smaller human-labeled datasets alongside large unlabeled datasets to cover more fraud modes. Autoencoders further correct label noise without constant human supervision.
Follow-up Question 3
How do you ensure the model handles collusions effectively?
Use a graph-based approach. Represent customers as nodes. Connect them if they share payment details, referral patterns, or suspicious order overlaps. GCN embeddings capture local and extended neighborhood structures. Feed these embeddings into the fraud classifier. Catch clusters of accounts with similar high-risk features. Periodically re-run graph embedding generation to incorporate newly appearing edges or nodes.
Follow-up Question 4
How would you deal with new types of fraud that do not match any existing labeling functions?
Monitor real-time claim patterns and track features that deviate strongly from historical norms. Label a small sample and retrain or refine decision trees for automated labeling. Establish a pipeline that allows analysts to create new labeling functions quickly. Rely on anomaly detection to highlight suspicious clusters for expert review. Re-run the generative label pipeline with updated LFs.
Follow-up Question 5
Explain the LSTM approach for capturing bursty fraudulent behavior.
Collect the last k orders for each customer. Sort them chronologically. Feed them into a stacked LSTM that encodes temporal dependencies. At each timestep, incorporate features like order amount or number of recent claims. The final LSTM output condenses sequential information into a representation. Dense layers project that hidden representation to a fraud probability. This method excels at flagging repeated suspicious actions in a narrow timeframe.
Follow-up Question 6
What practical steps improve real-time serving efficiency?
Pre-store features in a fast, in-memory cache like Redis or DynamoDB-DAX. Build minimal feature engineering steps into the TensorFlow Serving pipeline. Keep the model architecture lean (fewer layers) if latencies rise. Batch incoming requests only if concurrency is very high. Continuously monitor serving logs and memory usage. Refine the feature pipeline to reduce complexities.
Follow-up Question 7
Why use autoencoders for label denoising instead of simpler methods like majority voting?
Autoencoders transform input features into a latent space to learn the predominant pattern for each class. They reconstruct typical samples accurately. Label errors cause unusual feature combinations, leading to high reconstruction errors. Autoencoders detect these outliers more effectively than basic thresholds or majority voting. They scale better and adapt to evolving feature distributions.
Follow-up Question 8
How would you handle class imbalance?
Collect negative examples carefully. Downsample frequent non-fraud data to balance training. Alternatively, use class weighting in the cross-entropy loss to penalize fraud misclassifications more strongly. Augment data with synthetic examples via generative models if appropriate. Validate the final system with metrics focused on precision and recall at high thresholds.
Follow-up Question 9
How would you measure the actual business impact?
Calculate how many fraudulent refunds are prevented per week. Track how many genuine requests were wrongly flagged. Measure changes in net losses due to fraud and the time saved by automating claim decisions. Compare these metrics to historical baselines. Gradually expand the solution to more regions or user segments and track metrics.