
ML Case-study Interview Question: Deep Learning Recommendation Engines for Optimizing Digital Content Engagement.


Browse all the ML Case-Studies here.
Case-Study question
A technology-driven organization needs to build a recommendation engine to optimize user interactions with a large catalog of digital content. They have a dataset of user engagement metrics, content metadata, and historical behavior logs. They want to improve user engagement and retention. The approach involves data engineering pipelines, a robust machine learning solution, and an experimentation framework to validate performance. Propose a design, discuss potential models, outline your plan for deployment, and describe how you would measure success. Explain possible challenges and how you would address them. Provide specific technical details. Include a demonstration of any relevant formula, code, or method you find central to your solution.
Proposed Solution Overview
Data ingestion starts with a pipeline that periodically collects user events from streaming logs. A distributed file system stores raw event data. A separate process enriches these logs with user profile data and content attributes. A feature store then manages curated features in real time.
Model selection involves iterative experimentation. A sequential approach might start with logistic regression for classification or a deep model for ranking. Model complexity depends on data volume and feature diversity.
A typical classification approach uses cross-entropy loss to optimize predictions. The core mathematical expression is shown below.
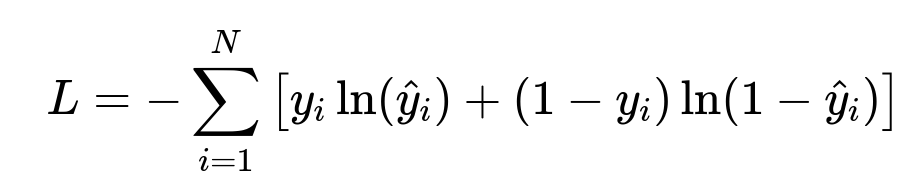
y_i is the true label for the i-th training example in {0, 1}. hat y_i is the predicted probability of the positive class for the i-th example. N is the total number of examples. The negative log-likelihood penalizes confident but wrong predictions.
After training the model on historical data, the system is deployed through an online inference service. A batch layer updates offline predictions for cold-start users, while a real-time layer handles fast-evolving user behavior.
Model performance is monitored through key metrics such as click-through rate, conversion rate, or session time. An A/B testing framework quantifies improvements. A control group uses the old system. The experimental group uses the new model. Statistical significance in improved engagement metrics confirms success.
Data Pipeline
Raw logs from user actions are parsed by a Python program that reads messages from a message queue. The program performs basic transformations and writes structured data to a data lake. A daily job merges these logs with user metadata. Feature engineering scripts transform signals like frequency of visits or recency of clicks into numeric features. A final step saves feature vectors to the feature store.
Model Training
A training script loads feature vectors and labels. The script uses libraries like PyTorch or TensorFlow. A typical code snippet in Python is shown below.
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleModel(nn.Module):
def __init__(self, input_dim):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
return x
# Sample training loop
def train_model(train_data, train_labels, epochs=5):
model = SimpleModel(input_dim=train_data.shape[1])
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(torch.from_numpy(train_data).float())
loss = criterion(outputs.view(-1), torch.from_numpy(train_labels).float())
loss.backward()
optimizer.step()
return model
The script creates a simple neural model with one hidden layer. The training loop uses binary cross-entropy. The forward pass produces probabilities. The backward pass updates weights through gradient descent.
Experimentation and Testing
The next stage is an online A/B test. A portion of traffic sees recommendations from the new model. Another portion sees older recommendations. Tracking conversion metrics or dwell time for each group validates the new approach.
Potential Pitfalls
Data quality issues arise if raw logs contain missing or noisy fields. Feature drift occurs when user behavior shifts. Overfitting risks increase with large feature sets. Latency constraints matter if model inference is too slow for real-time responses.
Follow-up question 1
How would you handle feature drift when user behavior changes quickly?
Feature drift is addressed by continuous retraining. Retraining frequency depends on how fast user interests shift. If user preferences evolve daily, a nightly batch retraining job updates parameters with fresh data. A streaming approach can also update models incrementally. Data distribution checks are run to detect changes in user behavior patterns. Pipeline automation ensures timely ingestion, transformation, and training.
Follow-up question 2
How would you verify the robustness of your model beyond a standard A/B test?
Offline tests with different data slices measure performance for various segments. Stress tests simulate extreme user behaviors. A holdout dataset with adverse conditions ensures the model is robust. Cross-validation estimates performance variance across folds. Adversarial analysis explores potential vulnerabilities, like malicious inputs. A post-deployment monitoring system checks for anomalous error rates or latency spikes.
Follow-up question 3
What strategies would you use to optimize latency in online inference?
Batching multiple user requests can reduce overhead. Model distillation compresses a complex model into a smaller one without significant loss in accuracy. Vectorizing operations on GPUs accelerates forward passes. Proper memory management and hardware acceleration improve throughput. Caching frequently requested predictions or partial results handles spikes in load. A multi-tier architecture delegates quick responses to a cached layer, then updates with real-time predictions.
Follow-up question 4
How would you ensure that your solution aligns with user privacy requirements?
All personally identifiable information is removed or anonymized before training. Access to raw data is restricted to essential processes. Aggregation at user-group level further protects identities. Encryption secures data in transit and at rest. Differential privacy techniques add noise to sensitive features if required. Legal compliance checks ensure adherence to relevant privacy regulations.
Follow-up question 5
How would you scale this system as data volume and traffic grow?
Horizontal scaling adds more compute nodes to the pipeline. Distributed file systems and cluster managers (like Spark) process large datasets in parallel. A load balancer distributes inference requests across multiple instances. Sharding user data by region or user segment organizes storage and processing. An autoscaling mechanism spins up additional instances during peak traffic. Container orchestration with Kubernetes simplifies deployment and monitoring.
Follow-up question 6
Why would a deep learning model sometimes be preferable to a simpler linear model?
Complex relationships in high-dimensional data make a simple linear boundary insufficient. Neural networks capture non-linear patterns. When user behavior is dynamic, a deep model learns representations of user intent with more flexibility. Transfer learning from pretrained embeddings can reduce data requirements. However, more parameters need more data and careful regularization to prevent overfitting. A deep architecture can improve performance if the dataset is large and rich.
Follow-up question 7
How would you address cold-start problems for new users or new content?
Collaborative filtering approaches struggle when no historical data exists. User demographic attributes or content similarity signals help bootstrap initial predictions. A content-based model suggests items similar to popular ones. A fallback strategy might show trending content to new users. Rapid logging of early user interactions updates the model or triggers a simpler rule-based approach. This approach avoids showing irrelevant items when data is limited.
Follow-up question 8
What would be your criteria for deciding whether to continue iterating on this model or to pivot to a new approach?
Performance plateaus might indicate the model is near capacity. Diminishing returns from feature engineering or hyperparameter tuning signal a need for architectural changes. Persistent feedback from user surveys or high error rates in certain segments can expose systematic shortfalls. If scaling demands exceed computational budget, a more efficient approach might be better. Changes in business goals also demand model revisions.
Follow-up question 9
How would you incorporate reinforcement learning in this system?
A reinforcement learning approach rewards actions that yield higher user engagement. The state space includes user context or session attributes. An agent selects a recommendation action and observes immediate user feedback like clicks or watch time. A policy gradient method or Q-learning approach updates the policy using cumulative rewards. This approach adapts dynamically to new behavior patterns. Careful reward shaping prevents unintended consequences, like spammy recommendations.
Follow-up question 10
What strategies would you suggest to debug model predictions in production?
A logging mechanism stores inputs, predictions, and outcomes for auditing. Sampling suspicious predictions uncovers systematic biases. Gradients or intermediate activations in neural models are inspected through specialized tools. Rolling out debug flags in the production environment captures additional diagnostic information. A partial rollback to a known stable model is done if errors spike. Continuous integration tests keep track of changes to code or model weights.
Use these methods to handle the toughest interview settings.